缓存服务 ACS
产品介绍
缓存服务 ACS(SenseCore AI Cache Service)为存储提供缓存加速服务,支持Posix、CSI接口,可以缓存存储中的热点文件,提供高性能、高吞吐量的数据加速服务。
产品优势
针对AI训练场景,提供高IO、高吞吐的缓存加速服务。
1.高性能
- 面向训练,带宽随容量大小线性增长,实现百万级IO和吞吐,提升模型训练的速度。
2.高可用
- 支持99.9%的高可用性,保证在训练加速时高性能不中断。
3.多种训练场景支持
- 支持不同的训练场景,比如:多模态、特别是图像、语音等海量中小数据读取加速的场景。
产品功能
1.多种加速方式
- 支持对象存储的缓存加速功能,支持不同训练场景的性能需求。
2.支持扩容和缩容
- 用户根据业务需求扩容满足性能需求,和通过缩容降低成本。
3.支持预热功能
- 用户在训练前,把将要训练的数据集预热到缓存,提高训练效率。
应用场景
1.模型训练场景
训练数据存储在大规模低成本S3对象存储里,通过缓存加速的方式进行模型训练。训练中的数据类型主要有两种:一种为视频、图像、语音类训练任务的小文件,一种为NLP、多模态等场景使用的大文件。
- 为S3对象存储的提供缓存服务
- 对接多种计算集群,提供超高吞吐和超高 IOPS 能力。
2.多机多卡训练场景
覆盖单机多卡,多机多卡,千卡;数据集文件数规模万~千亿规模的场景。
- 深度优化缓存服务,支持大模型训练场景
计费说明
1.计费方式
按量付费:申请缓存配置容量,根据时长计算费用。
| 计量项 | 计量方式 | 计费方式 |
|---|---|---|
| 存储容量 | 容量规格和购买时长 | 按量付费:缓存费用=申请的缓存配置容量×每GB单价×使用时长 |
2.使用规则
- 购买时配置的容量即为缓存服务的最大容量,根据使用时长计费。
3.欠费提醒
- 到期前5天、前3天、前1天通过站内信消息通知用户
4.欠费处理
- 欠费后,进入到保留期,服务停止,缓存空间保留15天,15天后自动销毁缓存空间,数据不可恢复。
快速入门
01.开通服务(注册账号并申请开通)—— 02.创建缓存服务(根据业务需求创建缓存服务)添加加速路径—— 03.管理缓存服务(通过控制台管理ACS缓存服务)。
快速创建实例
通过用户名密码登录。

2.登录进入主页面,点左上角产品目录按钮,弹出产品目录页,在快速入口页点击【AI缓存服务ACS】,进入ACS控制台
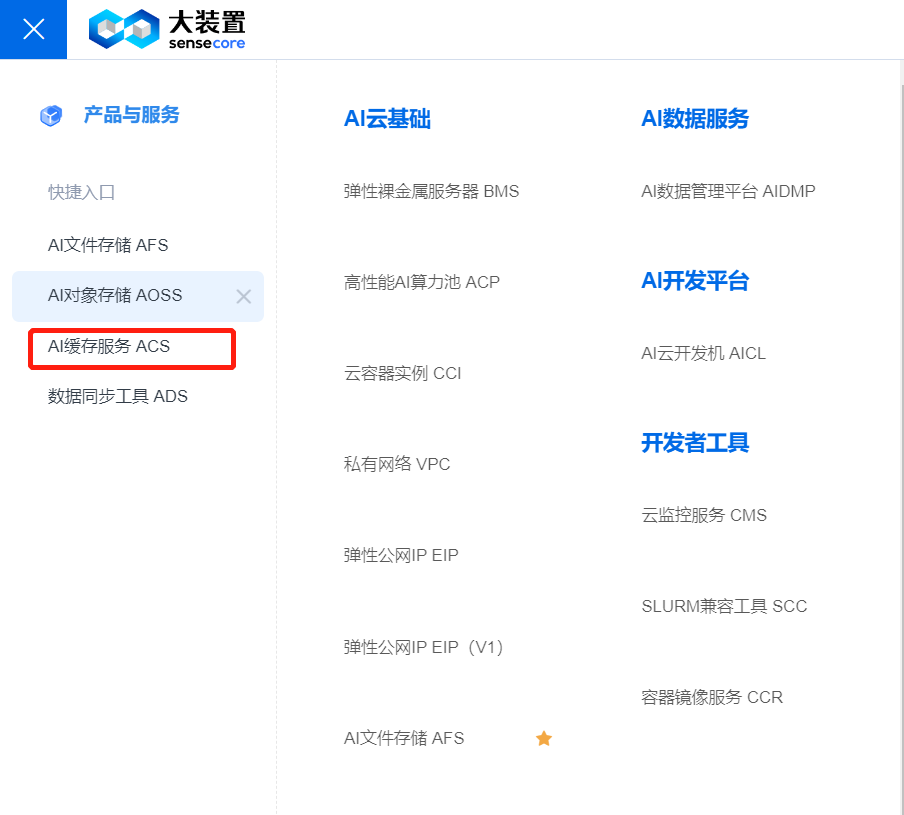
3.进入缓存服务控制台,可以看到缓存服务列表,展示已经创建的缓存服务列表信息,
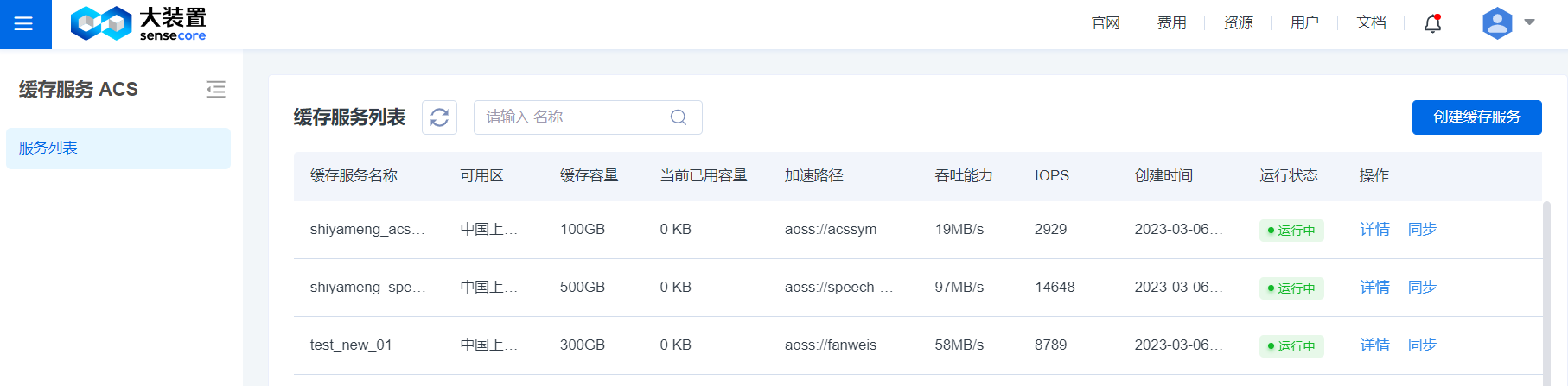
4.创建缓存服务:点击【创建】缓存服务,弹出下单页进行创建,计费模式为按量,即:缓存费用=申请的缓存配置容量×每GB单价×使用时长,其中容量为固定值 ,使用时长为为用户真正使用的时间。在资源配置,用户可以填写缓存的容量信息,最低100GB,最大可为500TB容量。然后再设置缓存加速路径,需要在下拉列表里选择已创建的存储桶,选择加速整个存储桶或者自定义填写存储桶内已有的某个目录,支持添加多个加速路径。基本信息,可选择默认资源组,并填写资源名称,点击立即购买,根据向导完成创建。创建完成后的信息展示在缓存服务列表页。
资源配置中列出缓存配置空间对应性能的范围
吞吐:200MB/s/TB~100GB/s
IOPS:30000/s/TB~100万
延迟:<=1ms
注:
在【第三方存储加速】目前支持第三方s3存储和跨租户加速路径可以填写Endpoint信息,填写Endpoint信息时,建议先使用内网域名,如果不支持内网域名,再使用外网域名访问,进行存储的加速。
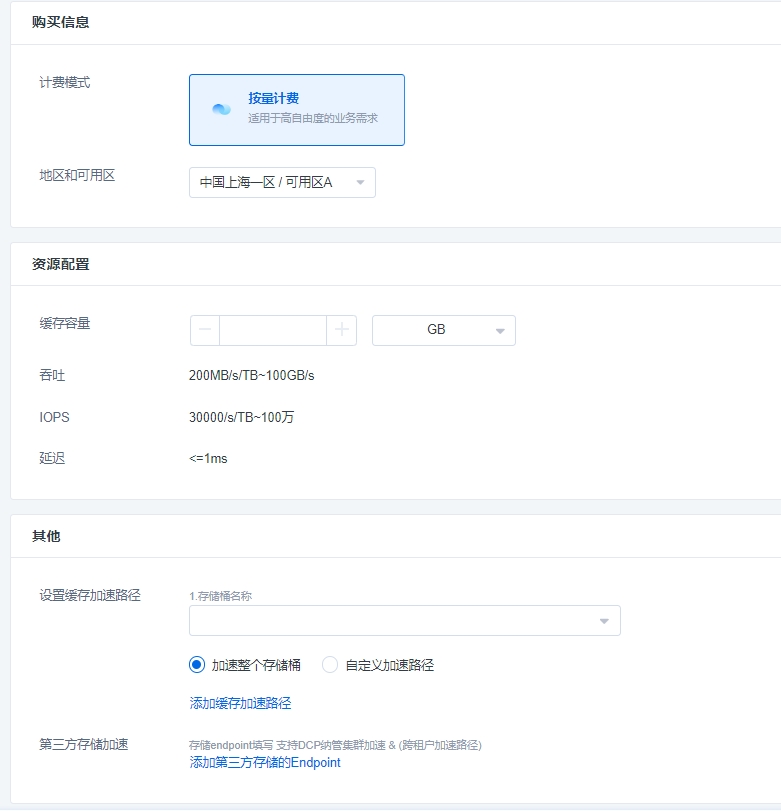
缓存加速路径创建说明
缓存加速路径是一种通过缓存技术来优化应用程序性能的方法。它的作用是加速特定路径的操作,从而提高应用程序的响应速度和用户体验。
缓存加速路径有两种方式创建:
一种是通过下单页面支持加速路径填写(必须填写至少一条加速路径)。
第二种是在编辑页面,想要增加或者减少加速路径时,可以通过编辑功能实现。
目前不支持SDK方式创建加速路径。
以下为可以创建加速路径的两种方式:
下单页面支持加速路径
【设置缓存加速路径】可以下拉到自己已经创建的桶进行选择,并选择加速整个存储桶还是自定义桶的路径。
在【第三方存储加速】目前只支持DCP集群的s3存储和跨租户加速路径,可以填写Endpoint信息,进行存储的加速。 通过编辑页面增加或者减少加速路径
缓存使用说明
1.环境需求
Python版本: 3.6, 3.7, 3.8, 3.9, 3.10, 3.11, 3.12
CPU指令集: x86_64
操作系统:Ubuntu版本 >=18,CentOS版本 >=7
C库:GLIBC >= 2.17
建议用户使用conda python环境,anaconda或miniconda二选一安装部署。
anaconda安装文档:https://docs.anaconda.com/free/anaconda/install/index.html
miniconda安装文档:https://docs.conda.io/en/latest/miniconda.html
2.安装ACS SDK步骤
# acs sdk版本
acs_ver='0.11.0'
# 下载ACS whl包,2个包均支持python 3.6-3.12版本
curl -fO https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/quarkacs/release/acs-${acs_ver}-py3-none-any.whl
curl -fO https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/quarkacs/release/acs_sdk_py-${acs_ver}-cp36-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.release.whl
# 卸载旧版 ACS whl包
pip uninstall acs acs_sdk_py
# 使用pip安装whl包
pip install acs*${acs_ver}*.whl
#若报安装依赖包超时,可尝试 pip install acs*${acs_ver}*.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.SDK使用示例
以下涉及到的域名信息请根据对象存储所在区域的实际EndPoint填写,如:上海公有云环境域名,EndPoint= 'http(s)://aoss.cn-sh-01.sensecoreapi-oss.cn' ,如果是商汤专有云环境,EndPoint= 'http(s)://aoss.st-sh-01.sensecoreapi-oss.cn'。或者专有云有其他第三方存储集群,根据对象存储实际的EndPoint填写即可。
本版本兼容Petrel OSS SDK, 以下提供Petrel OSS SDK、AOSS SDK、 Boto3 SDK三种用法。
3.1 通用操作示例
从缓存详情页复制ACS缓存实例的acs_uid, acs_cid, acs_tid,粘贴到 $HOME/acs/use_cache.toml 里,如图。
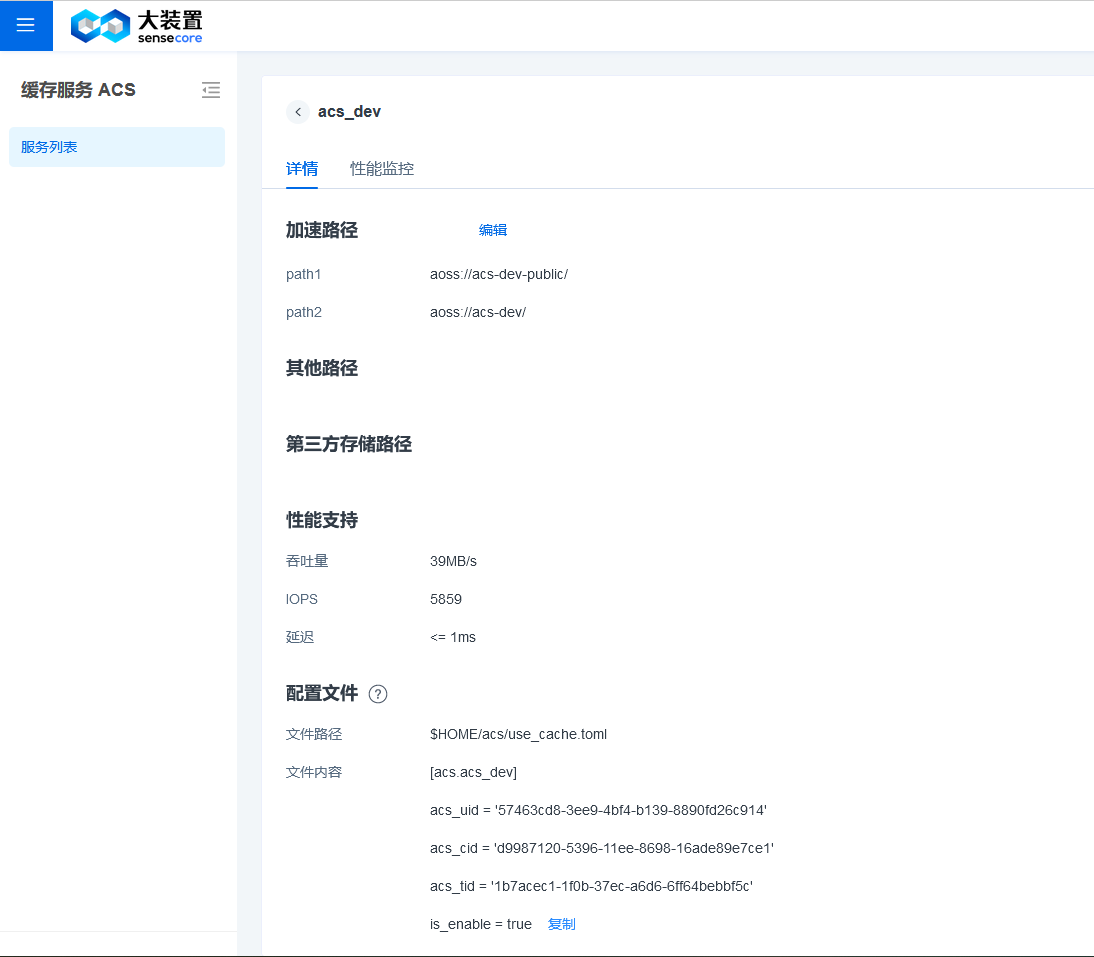
$HOME/acs/use_cache.toml 配置例子:
[global] # global配置可以不写
is_on = true # 是否全局开启acs,默认为true,本行配置可以不写;true false全部小写。false时,直接转发原sdk
[acs.缓存名称] # 以acs和英语句点开头,后面接缓存名称
acs_uid = '57463cd8-3ee9-4bf4-b139-8890fd26c914'
acs_cid = 'a349b05b-f949-11ed-aa24-4a12c7a27366'
acs_tid = '1b7acec1-1f0b-37ec-a6d6-6ff64bebbf5c'
is_enable = true # 是否开启当前acs实例,默认为true,本行配置可以不写;true false全部小写
3.2 open-mmlab修改方法
替换from petrel_client import client为 from acs.aoss import client,其他代码无需修改。
#修改mmengine/fileio/backends/petrel_backend.py, 替换from petrel_client 为 from acs.petrel_oss
location=`pip show mmengine | grep Location | awk '{print $NF}'`
sed -i -r 's/(^[\t ]*)from petrel_client import client/\1# from petrel_client import client\n\1from acs.petrel_oss import client/' $location/mmengine/fileio/backends/petrel_backend.py
说明:
acs提供了跟petrel oss全兼容的sdk,提供给用户2层控制是否经过acs缓存。
- $HOME/acs/use_cache.toml配置里[global] is_on,默认true。如果设置 is_on = false,那么全部调用原对象sdk 的 api。如果为true,那么看说明2;
- 如果acs没有对应api实现,那么走对象 api。当acs有正在访问的api实现,如果访问数据在acs实例的加速路径里且实例is_enabled = true,则走acs实例;如果访问数据不在acs实例的加速路径里或实例的is_enabled = false,则通过acs sdk访问对象存储。
3.3 AOSS SDK完整示例
acs.aoss SDK提供最小的用户python代码修改,用户修改1行 import,其他逻辑无需修改。
# 使用ACS缓存加速访问S3 兼容 aoss SDK
# 使用acs.aoss替代aoss_client
from acs.aoss.client import Client
#from aoss_client.client import Client
s3 = Client() # 创建client时,SDK获得endpoint, ak, sk后,触发数据集预读
Uri = 's3://s3-test/'
print("hello")
s3.put(Uri+'hello.txt', b'hello, world/n')
out = s3.get(Uri+'hello.txt')
print(out)
print("file")
with open(u'./local_file_a', 'rb') as f:
s3.put(Uri+'local_file_a', Body=f)
with open(u'./local_file_b', 'wb') as f:
out = s3.get(Uri+'local_file_a', enable_stream=True)
f.write(out.read())
contents = s3.list(Uri)
for e in contents:
if e.endswith('/'):
print('directory:', e)
else:
print('file:', e)
3.4 Petrel OSS SDK示例
acs.petrel_oss SDK提供最小的用户python代码修改,用户修改1行 import,其他逻辑无需修改。
# 使用ACS缓存加速访问S3 兼容 aoss SDK
# 使用acs.petrel_oss替代petrel_client
from acs.petrel_oss.client import Client
#from petrel_client.client import Client
s3 = Client() # 创建client时,SDK获得endpoint, ak, sk后,触发数据集预读
Uri = 's3://s3-test/'
print("hello")
s3.put(Uri+'hello.txt', b'hello, world/n')
out = s3.get(Uri+'hello.txt')
print(out)
print("file")
with open(u'./local_file_a', 'rb') as f:
s3.put(Uri+'local_file_a', Body=f)
with open(u'./local_file_b', 'wb') as f:
out = s3.get(Uri+'local_file_a', enable_stream=True)
f.write(out.read())
contents = s3.list(Uri)
for e in contents:
if e.endswith('/'):
print('directory:', e)
else:
print('file:', e)
3.5 Boto3 SDK完整示例
acs.boto3 SDK提供最小的用户python代码修改,用户修改1行 import,其他逻辑无需修改。
import acs.boto3 as boto3
替换原有对象存储的boto3包,ACS SDK提供了get,put接口加速S3对象存储访问。
# 使用ACS缓存加速访问S3 兼容 boto3 SDK
# 使用acs.boto3替代boto3
#import boto3
import acs.boto3 as boto3
# 无需修改用户访问S3对象存储的逻辑
ENDPOINT = 'https://aoss.cn-sh-01.sensecoreapi-oss.cn'
BUCKET = 's3-test'
# 创建client时,SDK获得endpoint, ak, sk后,触发数据集预读
s3 = boto3.client('s3', endpoint_url=ENDPOINT,
aws_access_key_id="your_ak", aws_secret_access_key="your_sk")
print("hello")
s3.put_object(Bucket=BUCKET, Key='hello.txt', Body=b'hello, world/n')
resp = s3.get_object(Bucket=BUCKET, Key='hello.txt')
print(resp['Body'].read())
print("file")
with open(u'./local_file_a', 'rb') as f:
s3.put_object(Bucket=BUCKET, Key='local_file_a', Body=f)
with open(u'./local_file_b', 'wb') as f:
resp = s3.get_object(Bucket=BUCKET, Key='local_file_a')
f.write(resp['Body'].read())
用户可以通过filelist指定数据预加载的顺序。当缓存容量使用超过90%时,缓存按'先入先出'替换内容。
# 用户通过file list进行缓存的动态预加载
s3.preload_by_file_list('file_list_path', 'endpoint', 'bucket')
#用户可选传入parent_dir;例如cache.preload_by_file_list('file_list_path', 'endpoint', 'bucket', 'parent_dir'),
#parent_dir非空,缓存自动检查并拼接路径 endpoint/bucket/parent_dir/entry_in_file_list, 此时endpoint/bucket/parent_dir/需要在加速路径中
#parent_dir = None或""时,缓存自动检查并拼接路径 endpoint/bucket/entry_in_file_list,此时endpoint/bucket/需要在加速路径中
用户可以通过标注文件进行缓存数据的预加载。当缓存容量使用超过90%时,缓存按'先入先出'替换内容。
# 用户通过标注文件进行缓存的数据预加载, 属于对象存储endpoint uri、桶名、目录路径
s3.preload_by_ann_json('/fs_path/ann.json', endpoint='endpoint', bucket='bucket', parent_key='parent_key', ann_key="filename", code="utf-8")
用户可以通过目录进行缓存数据的预加载。当缓存容量使用超过90%时,缓存按'先入先出'替换内容。
# 用户通过目录进行缓存的数据预加载, 属于对象存储endpoint uri、桶名、目录路径
s3.preload_by_directory('endpoint', 'bucket', 'directory1')
s3.preload_by_directory('endpoint', 'bucket', 'directory2')
# 用户可以获取在队列中的预加载任务
res = s3.list_preload('bucket', 'directory1', 'cache_id')
print(res)
#用户可以取消状态不是running的预加载任务
s3.cancel_preload('bucket', 'directory2', 'cache_id')
3.6 WebDataSet使用方法
WebDataSet为PyTorch提供了Dataset实现,使用tar归档大量样本数据,仅使用高效率的顺序流式数据访问。在许多计算环境中WebDataSet都能带来了显著的数据访问性能优势,对于超大规模训练至关重要。WebDataSet同样适用于较小的数据集,并简化了深度学习训练数据的创建、管理和分发。在不同存储系统上使用WebDataSet不需要任何形式的数据转换,数据在tar文件内的存储格式不变,所有的预处理和数据增强代码都保持不变.
当数据集在ACS缓存的加速路径中包含对象存储路径,可以使用ACS缓存加速WebDataSet访问。
1)下载增加ACS和AOSS支持的whl包;
curl -fO https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/quarkacs/release/webdataset-0.2.86-py3-none-any.whl
pip install webdataset-*.whl
2)url地址增加前缀'acs:'或'aoss:',告知WebDataSet从ACS或AOSS加载数据。
import webdataset as wds
# 原url增加'acs:'前缀,告知WebDataSet使用acs缓存
url = "acs:s3://quark/quarkacs/tech/00000.tar"
dataset = wds.WebDataset(url).shuffle(100)
for sample in dataset:
key = sample["__key__"]
url = sample["__url__"]
json = sample["json"]
print(key, url, json)
break
- 挂载为文件系统
4.1 裸金属挂载
参考2节安装
#!/usr/bin/bash
# 从2.1节获取acs_uid, acs_cid, acs_tid
# MNT_POINT 为挂载的目标路径
# SPEED_UP 为缓存详情页的加速路径
#挂载整个cache
acs-client mnt volumeID=$ACS_CID $MNT_POINT -o userID=$ACS_UID,clusterID=$ACS_TID,ak=$AK,sk=$SK
#挂载某加速路径
acs-client mnt volumeID=$ACS_CID,subDir=$SPEED_UP $MNT_POINT -o userID=$ACS_UID,clusterID=$ACS_TID,ak=$AK,sk=$SK
挂载为文件系统后,endpoint去掉协议(http://或https://)作为目录,bucket做为目录,key按'/'分隔作为目录。
4.2 对象key到文件目录说明
显示编码需为UTF-8。
文件路径使用'/'作为分隔符,'.'表示目录自身,'..'表示父目录。目录或文件名不能为空。同一级目录下没有重名。
对象key为UFT-8字符序列,可能包含上述文件路径的保留字符,需要进行转义。
对象key按'/'分为多个字符串,每个都作为目录项;特殊字符串按下面5条规则转换:
1)空串转换为'␀'(unicode空字符);
2) '.'转换为全角'.'(全角英文句点);
3)'..'转换为全角'..'(两个全角英文句点);
4)文件和目录同名时,对应文件增加'␜'后缀(unicode文件符);
5)转义字符'‛'(全角英文引号),当字符串本身为前述特殊字符,那么进行转义;
举例说明,同一个桶下有两个key:a/b/c 和 a/b/c/d,挂载为文件后的路径为a/b/c␜ 和 a/b/c/d,因为c不能同时为目录和文件名。
对象key:/x/y和x/y,挂载后的路径为␀/x/y和x/y。key:z///1挂载后的路径为z/␀/␀/1
- 缓存预热
5.1 按标注文件预热
from acs.aoss.client import Client
client = Client()
# 下面代码解析ann.json文件,获取所有filename字段组成list,parent_uri作为前缀加上list中每一项组成对象key的集合,从而缓存后台大并发从对象存储读取需要预热的数据
# parent_uri需被缓存加速路径覆盖到
client.preload_by_ann_json('/fs_path/ann.json', parent_uri, ann_key="filename", code="utf-8") # 默认 ann_key="filename", code="utf-8"
# 下面代码查看预热任务进度,parent_uri需被缓存加速路径覆盖到
client.list_preload(parent_uri)
5.2 按目录预热
用户传入目录,缓存按目录list顺序进行下载,先入先出替换。
from acs.aoss.client import Client
parent_uri = 's3://s3-testbkt/dir'
parent_uri1 = 's3://s3-testbkt/dir1'
client = Client()
# 后台目录预加载
client.preload_by_directory(parent_uri)
client.preload_by_directory(parent_uri1)
# 下面代码查看预热任务进度,parent_uri需被缓存加速路径覆盖到
res = client.list_preload(parent_uri)
print(res)
# 取消状态不是running的预热任务
client.cancel_preload(parent_uri1)
5.3 单文件同步预热
aoss, petrel_oss 例子:
from acs.aoss.client import Client
client = Client()
# preload返回成功时,缓存中加载了's3://s3-test/hello.txt'
client.preload('s3://s3-test/hello.txt')
5.4 list预热
用户传入filelist,缓存按filelist的顺序进行预读,先入先出替换。
from acs.aoss.client import Client
parent_uri = 's3://s3-test'
flist = ['hello.txt', 'world.txt']
client = Client()
# 后台批量预加载
client.preload_by_file_list(flist, parent_uri)
用户指南
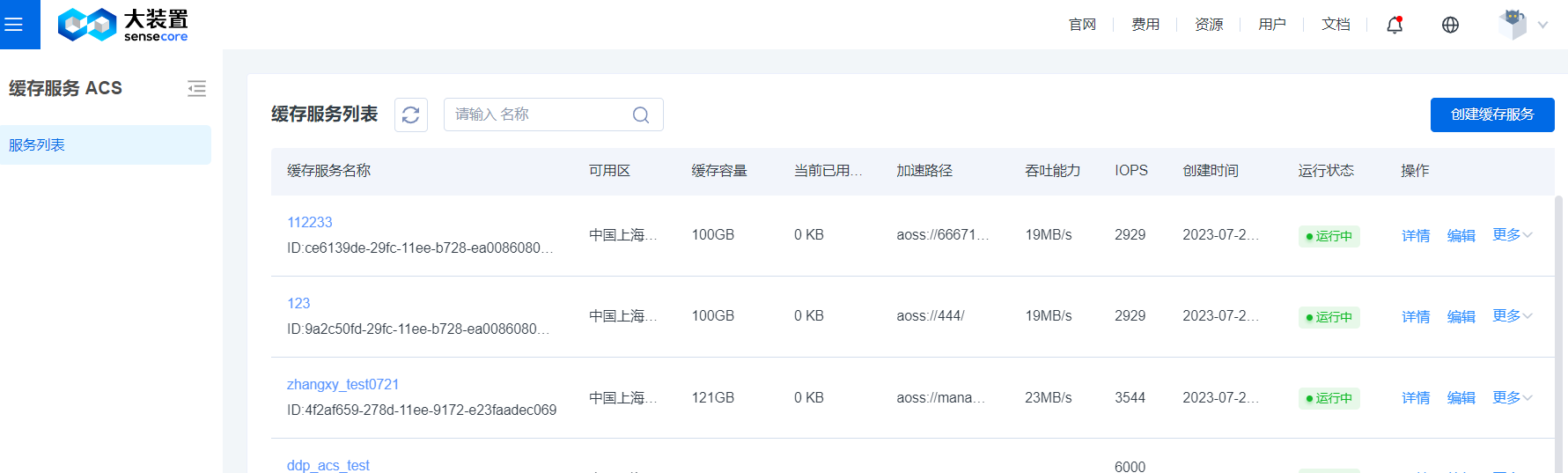
- 缓存服务列表展示
缓存服务列表主要展示了缓存服务信息,缓存服名称:用户在创建缓存的下单页填写的资源名称。还有可用区和缓存容量配置与当前已用容量的展示,加速路径展示了缓存服务加速存储桶的路径信息,吞吐能力和IOPS展示了缓存能够在此缓存空间能够提供的性能为多大。在操作页有两个按钮:【详情】和【同步】,【详情】展示了缓存的详细信息和性能监控信息,【同步】是为了保证缓存数据为最新数据,当对象存储增加了新数数据,点击【同步】,把新数据同步到缓存里。

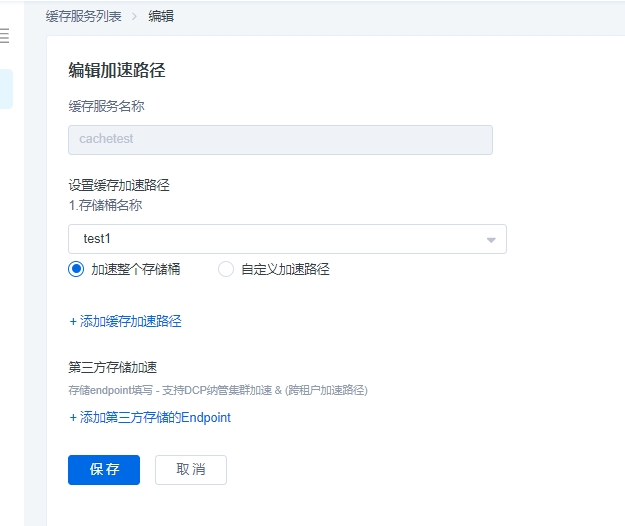
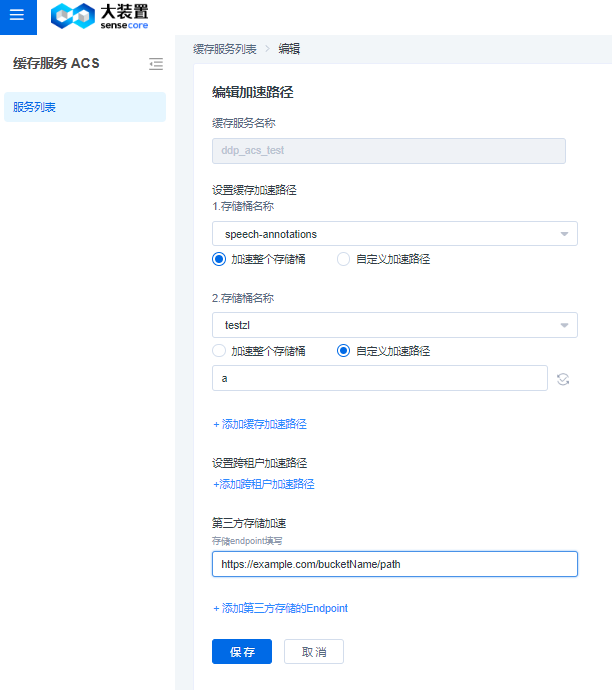
- 编辑功能
在缓存列表页,选择要编辑的缓存实例,点击【编辑】,弹出编辑对话框,可以增加或者删除加速路径。
设置缓存加速路径:支持加速租户内的桶或者桶内的目录。
设置跨租户加速路径:为跨租户或者对象存储租户内部无法list到的具有读写权限的桶。
第三方存储加速:支持加速非SenseCore的存储资源,目前支持 S3协议的存储。
2.详情信息展示
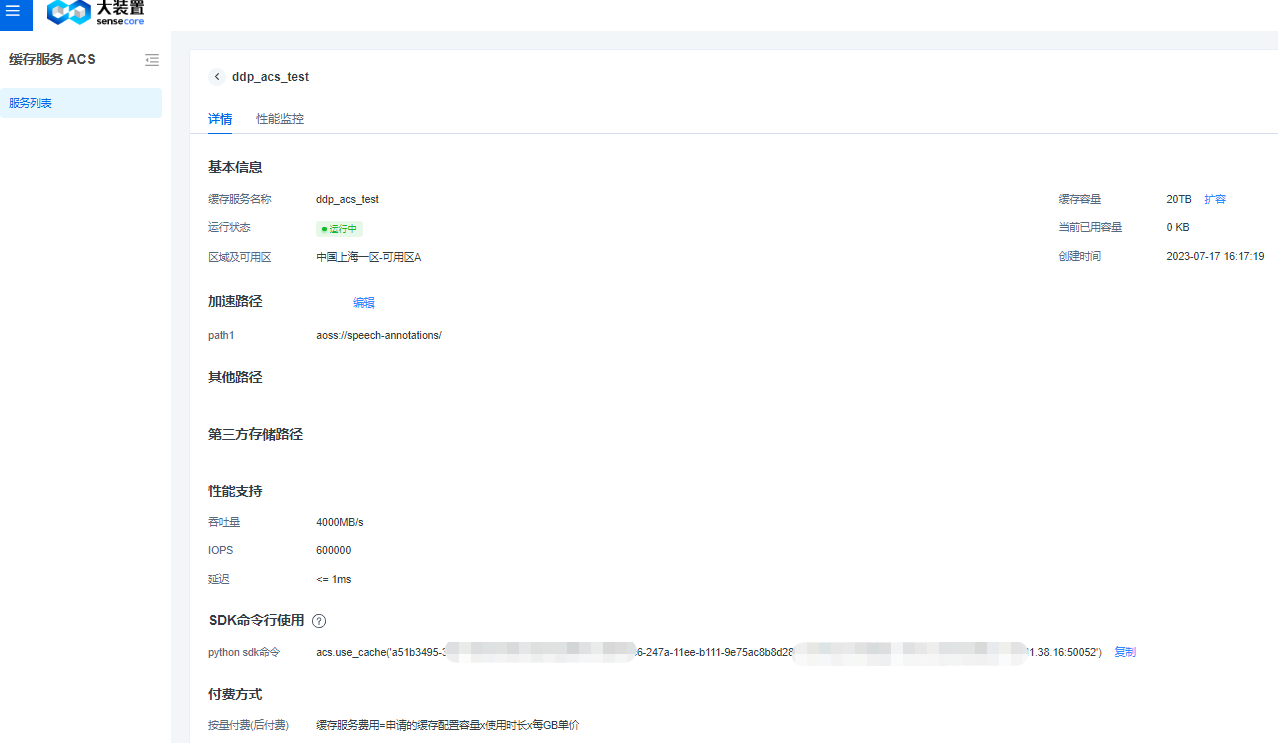
点击缓存服务对应的【详情】按钮进入到详情页,展示了缓存的基本信息、加速路径,其中【加速路径】为SenseCore租户内桶加速,【其他路径】为跨租户或者对象存储租户内部无法list到的具有读写权限的桶、【第三方存储路径】为非SenseCore的存储加速,目前支持S3协议存储;支持SDK命令行使用和付费方式的信息
3.性能监控
点击【性能监控】,在本页展示了缓存的读写IOPS、读写吞吐、读写延迟的折线图和缓存命中率的环形图信息展示。 其中缓存命中率计算公式:缓存命中率=经缓存读的文件数量/(经缓存读的文件数量+直接从对象存储读取的文件数量)

常见问题
1.缓存主要支持哪种存储加速?加速范围是什么?
答:主要支持对象存储的缓存加速服务,为多模态、特别是图像、语音等海量中小数据读取加速的场景。
缓存加速范围:创建缓存时,用户填入加速路径,缓存只加速加速路径范围内的对象读取。
2.ERROR: acs_sdk_py-xxx.whl is not a supported wheel on this platform.
答:Python 版本和当前whl包不匹配。
解决办法:按手册SDK安装方法安装。如果没有对应python版本的whl包,请联系交付支持。
3.OSError:transport error
答:客户端跟服务端网络通信问题,请先排查客户机器本身网络通畅。排除机器本身网络问题后,如果错误仍旧存在,请联系交付人员请求支持。
4.preload_by_file_list()是否可多次调用,多次调用有什么影响
答:可以多次调用。当file list在缓存里累计数据集合大小超过容量90%时,按先入先出淘汰。当一个文件多次加入时,按最后的位置淘汰。
5.preload_by_file_list()内容跟缓存加速路径的关系
答:只对缓存加速路径范围有效。当某个文件不在一个缓存实例的加速路径里时,不会被这个缓存加速。
6.不使用preload_by_file_list()时缓存的行为
答:缓存get后缓存,如果数据大于缓存容量的90%,那么触发先入先出淘汰。
7.缓存创建大小
答:每个缓存对应一个计算任务访问的数据集,缓存大小应略大于数据集大小。