对象存储 AOSS
产品介绍
对象存储 AOSS(AI Object Storage Service)是商汤为AI企业和开发者提供的海量、高可靠、低成本的分布式云存储服务,针对AI场景做特定的性能优化,为用户解决AI生产过程中的海量数据搜集、标注、冷存的低成本需求等问题。用户可以使用AOSS方便快捷地对海量图片、音视频数据进行处理和访问,性能不影响。
产品优势
1.稳定可靠
- 全冗余架构设计,为数据持久存储提供更可靠的保障。
2.安全合规
- 完善的权限控制和加密功能,满足企业数据安全与合规要求。
3.智能存储
- 提供数据生命周期管理,满足企业数据管理需求。
产品功能
1.AWS S3兼容
- AOSS兼容AWS S3,解决了基于AWS S3开发的应用程序在不需要二次开发前提下接入AOSS。
2.多种写入API
- 针对AI场景中的不同写入需求,提供丰富的写入API:简单上传、断点续传、追加上传等方式。
3.多种操作方式
- 用户可以通过控制台、API、SDK方式进行存储管理。
4.数据安全
- 提供完善的权限管理,并支持服务端加密功能,多方位保护数据的安全。
5.小文件读写优化
- 优化海量小文读写性能,支持小文件合并功能。
产品类型与规格
1.标准存储
- 标准提供高可靠、高可用、高性能的对象存储服务,能够支持频繁的数据访问。适用AI数据搜集、标注、大数据分析等业务场景。
注:01a,01b和01e三个可用区已经打通,01b做为主要站点,01a的资源环境快满,建议新建资源包或者桶时,优先在01b创建。可以其他区(01a和01e)访问,性能不影响。
2.归档存储
- 提供高持久性、极低存储成本的对象存储服务。有最低存储时间(60天)和最小计量单位(64 KB)要求。归档存储属于冷数据类型,数据取回时需要提前恢复(解冻),并且在读取数据前需要先进行数据恢复(适用于数据长期保存的业务场景)。
注:归档产品刚上线,功能还不完善,例如最低存储时间要求,目前还未限制,控制台已经支持解冻功能,数据层面还未支持解冻,可以通过命令行,SDK直接读写,后面会排期进行控制面和数据面的统一。
3.性能规格
1130版本更新默认限制
- 目前在临港可用区,01A使用的为标准1.0版本,01B使用的为标准2.0版本,推荐新建桶和资源包的创建,在01B进行创建,享受更好的规格性能。
- 单个存储桶文件数量上限为2亿(1.0版本),2.0版本不限制桶内文件数量。
- 如果使用时,性能突破默认限制,请联系对应的技术人员,会根据购买的容量,做对应的上调。
- 01a外网带宽:500Mbps。
- 01b和归档外网带宽:500Mbps。
- 除特殊提单要求桶QOS限制的用户进行配置,其余默认不设置桶的QOS。
| 存储类型 | 默认限制 |
|---|---|
| 标准1.0 | 租户内网吞吐:2GB/s,QPS:10000 |
| 归档 | 租户内网吞吐:1GB/s,QPS:10000 |
| 标准2.0 | 租户内网吞吐:4GB/s,QPS:10000 |
应用场景
1.AI数据存储与管理
AOSS支持不同种存储类型,根据数据的冷热进行分层,满足不同AI需求的存储服务
- 提供存储分层能力,降低存储成本
- 优化海量小文件读写性能
- 优化超大文件读写性能
2.AI数据容灾与备份
AOSS提供本地冗余和同城冗余的能力,避免存储受到不可抗逆灾难时会造成的损失
- 保证数据的可用性和持久性
- 跨区域复制可以创建跨区域之间数据的异步复制
计费说明
1.计费方式
资源包计费: 资源包是由单个或多个计量项组合的固定套餐,按计量单位包年包月方式进行销售,一次性完成支付,支付后立即生效。
| 计量项 | 计量方式 | 计费方式 |
|---|---|---|
| 标准存储容量 | 容量规格和购买时长 | 包年包月,购买时一次性付费(容量以【GB/TB/PB】为单位,购买时长以月和年为单位) |
| 归档存储容量 | 容量规格和购买时长 | 包年包月,购买时一次性付费(容量以【GB/TB/PB】为单位,购买时长以月和年为单位) |
| 流量包(外网下行) | 容量规格和购买时长 | 包年包月,购买时一次性付费(容量以【GB/TB/PB】为单位,购买时长以月和年为单位) |
| 请求包 | 容量规格和购买时长 | 包年包月,购买时一次性付费(容量以【万次】为单位,购买时长以月和年为单位) |
按量计费: 资源按照实际用量结算,在每个结算周期生成账单并从账户中扣除相应费用。资源包相比按量付费更划算,推荐购买资源包。
| 计量项 | 计量方式 | 计费方式 |
|---|---|---|
| 标准存储容量 | 实际用量 | 开通后按实际使用量结算费用 |
| 归档存储容量 | 实际用量 | 开通后按实际使用量结算费用 |
2.购买方式
| 购买方式 | 资源包(预付费)包年包月按量 | 备注 |
|---|---|---|
| 标准存储类型资源包 | 标准型容量包+请求包+流量包(外网下行) | 3个资源包都需要同时购买 |
| 归档存储类型资源包 | 归档型容量包+请求包+流量包(外网下行) | 3个资源包都需要同时购买 |
| 按量计费 | 不需要购买资源包 按量计费分为:标准存储容量计费、归档存储容量计费、流量计费、请求计费 按实际使用量计费 | 开通后按实际使用量结算费用 |
注:
1.流量包:用于外网下行的流量使用。
2.用户不使用外网下行流量包可以填写0购买,如果已购买的流量包,使用超额后,只影响外网下行流量的使用(如:外网的读和下载会影响),内网读写不影响。
3.请求数支持超额不降级,如果用户如果出现降级,先扩容恢复, 后续即可请求次数超量不降级。
3.使用规则
- 购买包年包月存储容量资源包后,立即生效,用户即可使用对象存储功能。
- 购买时配置的容量即为总的最大存储容量,如果超出容量,请进行扩容,否则无法写入。
- 按量计费对象存储的使用费用每小时结算一次。
4.到期提醒
- 包年包月服务到期前5天、前3天、前1天分别通过站内信消息通知用户。
5.服务到期后提醒及处理
- 服务到期后进入宽限期,宽限期为24小时,在宽限期内资源只读,通过站内信方式通知用户。
- 服务到期24小时后,进入保留期,保留期为14天,保留期14天内保留数据但不可读取。
- 服务到期15天内续费,数据恢复正常使用;服务到期15天内未续费,服务到期15天后自动销毁数据,数据不可恢复。
6.存储资源包扩容
存储资源包剩余用量不够时,可对其进行扩容。扩容操作步骤如下:
进入对象存储控制台,点击右上角【购买扩容资源包】,进入下单页面;选择需要的容量后,进入下单页面,对扩容订单进行支付,支付成功即可扩容。
注:930版本更新流量和请求计费(预付费)
1. 流量和请求按月周期计费,月周期,如2.21购买到3.21为一月。下月reset,流量和请求次数统计会被重置为零,开始新一轮的计费周期。
2. 月周期请求和流量不足时,扩容,扩容为后面所有时长。 用户可以通过缩容解决。
3.以前按总量使用的消息告警,变为月周期使用量的告警。如 80%,90% 100%时的告警。
4.dashboard 由以前展示总量剩余,变为月总量,月剩余量。
6. 针对老用户告警信息切换:月总量=当前总量,月使用量=当前使用量;订单履约月刷新后,月总量(不变)=当前总量,月使用量清零重新累加。
快速入门
裸金属跨区访问对象存储配置 (930版本后,新增祼金属不需要配置)
近期,上海三个可用区01a、01b和01e进行了打通,裸金属(物理机)所在的01a、01b和01e,如果想通过数据网跨区访问对象存储,需要进行配置;如果是同可用区访问,如:01a-01a,01b-01b,01e-01e,不用进行配置。
针对不同可用区的使用情况进行了梳理:
| 域名/机房 | 01a | 01b | 01e |
|---|---|---|---|
| aoss-internal.cn-sh-01.sensecoreapi-oss.cn | 无需,走老LVS | 10.118.184.237/238/239 | 10.118.119.244/245/246/247 |
| aoss-internal.cn-sh-01b.sensecoreapi-oss.cn | 10.118.176.48-53,112-117 | 10.118.184.247/248/249 | 10.118.119.242/243/248/249 |
| archive-aoss-internal.cn-sh-01.sensecoreapi-oss.cn | 10.118.176.38-43,102-107 | 10.118.184.232/233/234 | 10.118.119.236/237/238/239 |
上表中,01a,01b,01e代表的是裸金属节点所在的可用区,最左侧的域名,代表的是不同可用区的对象存储域名。如果想进行跨可用区的访问,需要在裸金属/etc/hosts 进行IP和域名配置:
比如裸金属从01a访问归档存储,需要在/etc/hosts 里面写入IP和域名:
10.118.176.38 archive-aoss-internal.cn-sh-01.sensecoreapi-oss.cn
比如裸金属从01b访问归档存储,需要在/etc/hosts 里面写入IP和域名:
10.118.184.232 archive-aoss-internal.cn-sh-01.sensecoreapi-oss.cn
注:
配置IP的时候,随机选择,尽量都不配相同的一个。
如果不想进行/etc/hosts配置,可以直接访问IP即可。
裸金属配置/etc/hosts方案为短期方案,930版本升级后即可正常访问,无需进行配置,功能升级后,再通知用户。
1.登录sensecore控制台
输入账号密码登录控制台

2.购买对象存储资源
进入对象存储控制台概览页面,点击右上角【购买存储资源包】
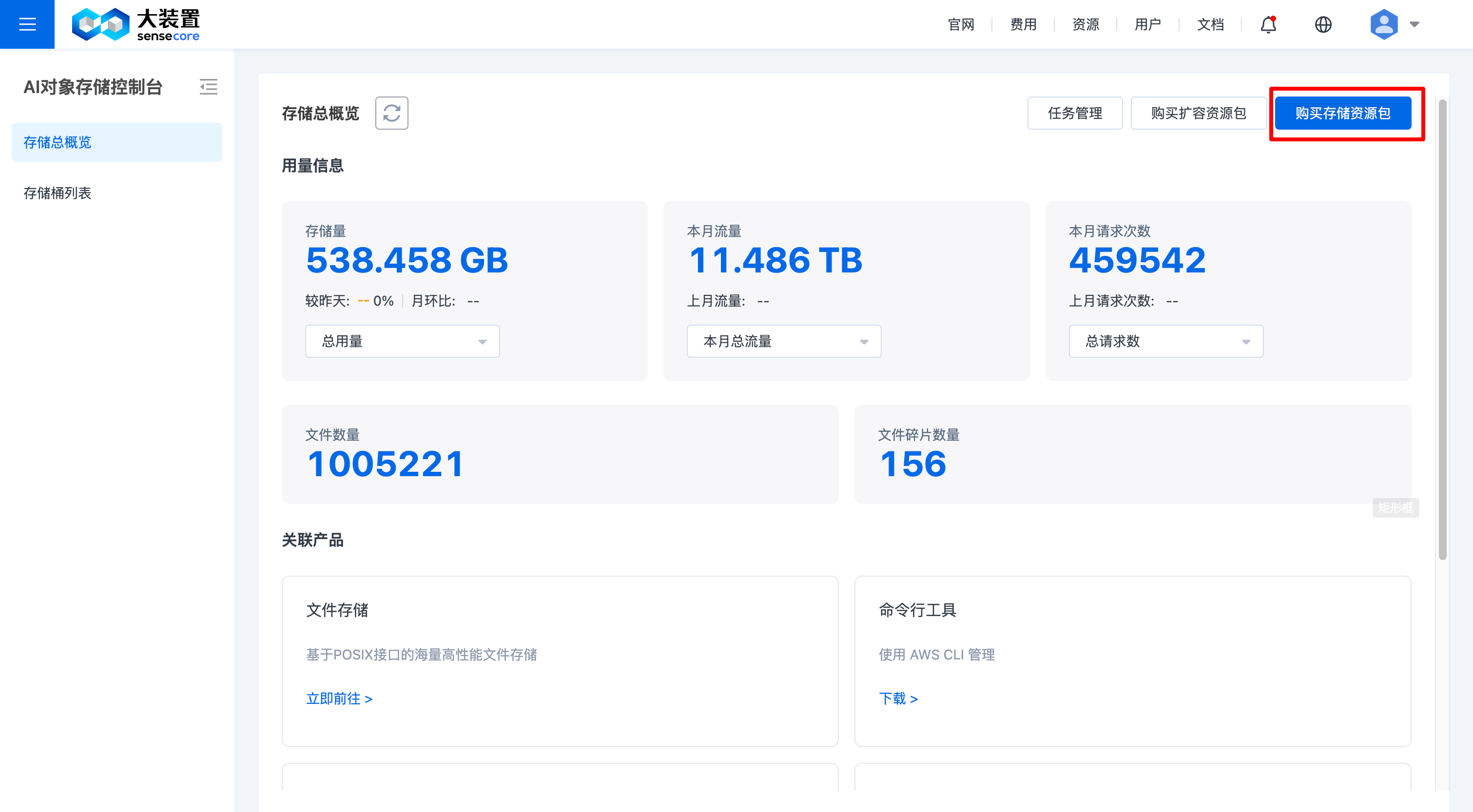
选择需要的容量,购买资源
注意:
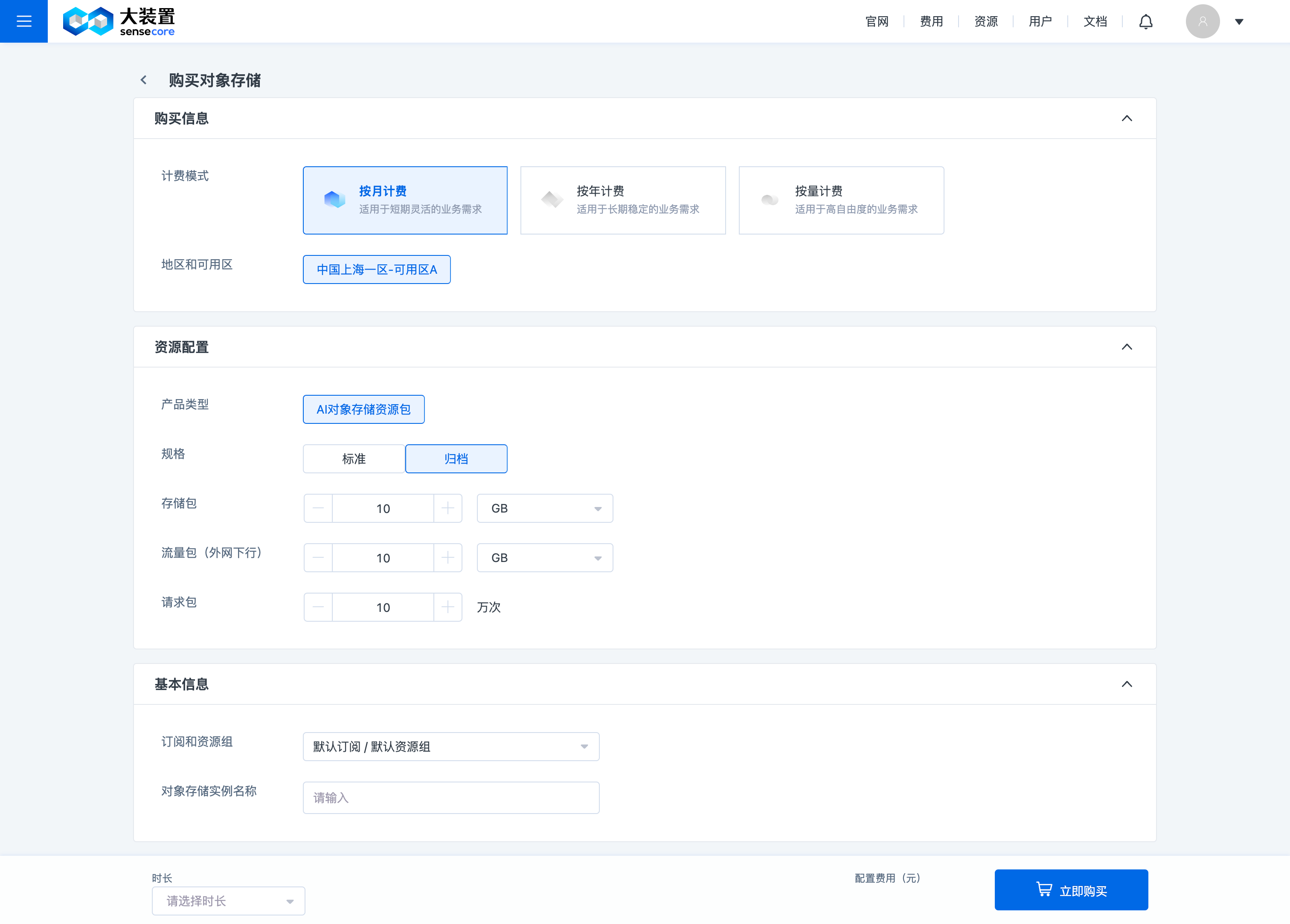
用户购买标准或归档存储资源包时,需要同时购买请求包和流量包(使用容量的过程会涉及请求和流量的使用),即:每次下单的组合为【标准+请求+流量】或【归档+请求+流量】;
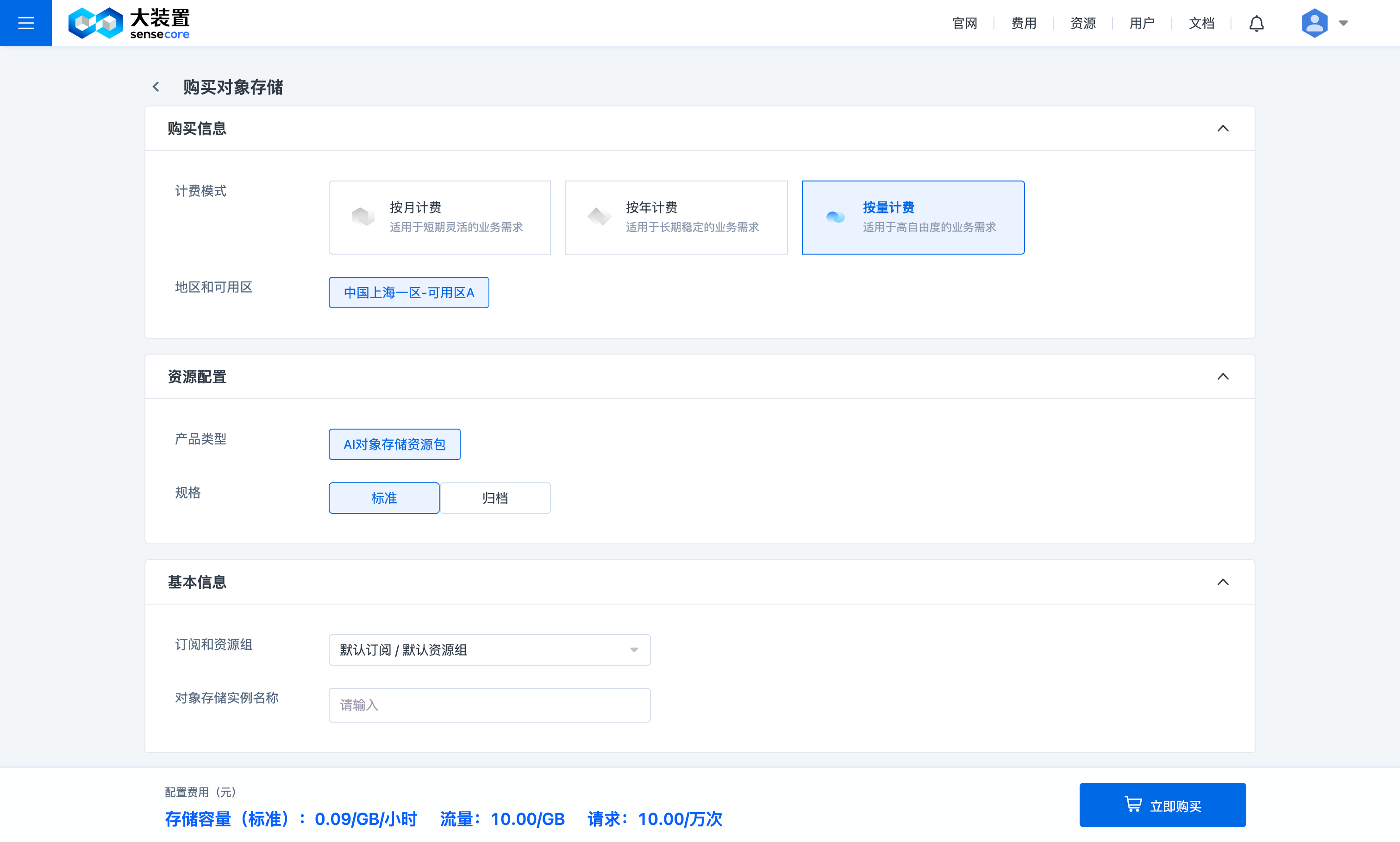
用户购买按量计费时,需选择开通的存储类型为【标准】或【归档】;一旦开通,请求和流量的按量计费也会同时开通
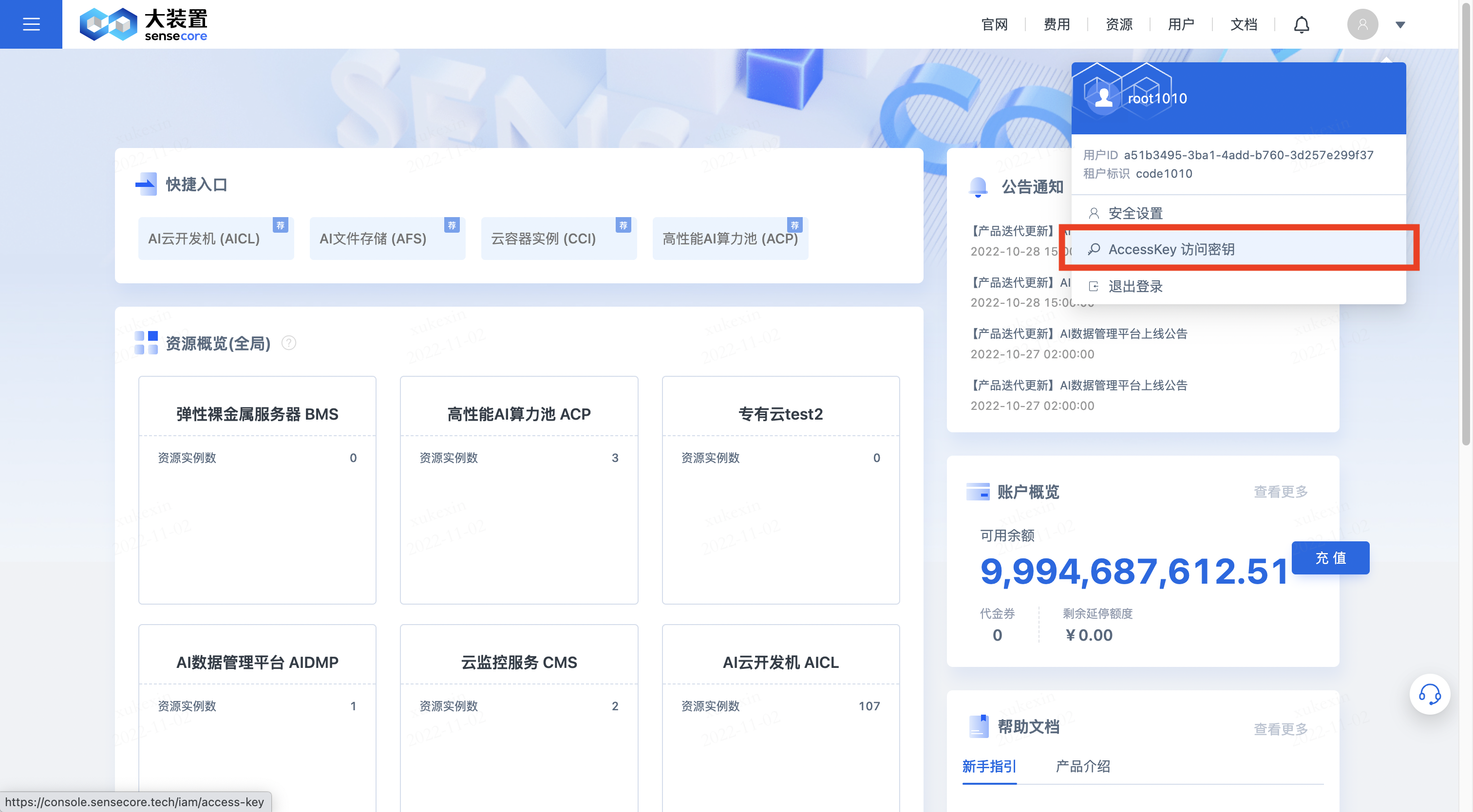
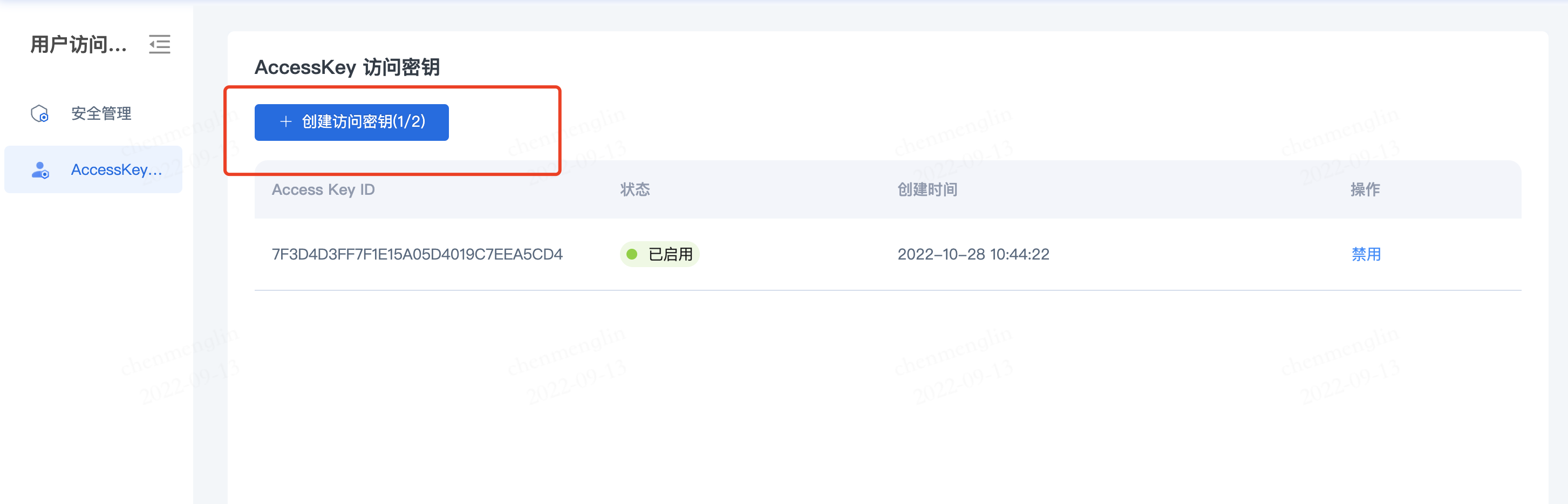
3.创建AKSK(用户角色需先创建aksk方可创建桶)
用户角色需要先创建AKSK,然后点击【开始使用】对象存储,方可创建桶及正常使用
点击右上角头像下的【AccessKey访问密钥】,进入密钥管理界面
 点击【创建访问密钥】,即可创建AKSK
点击【创建访问密钥】,即可创建AKSK
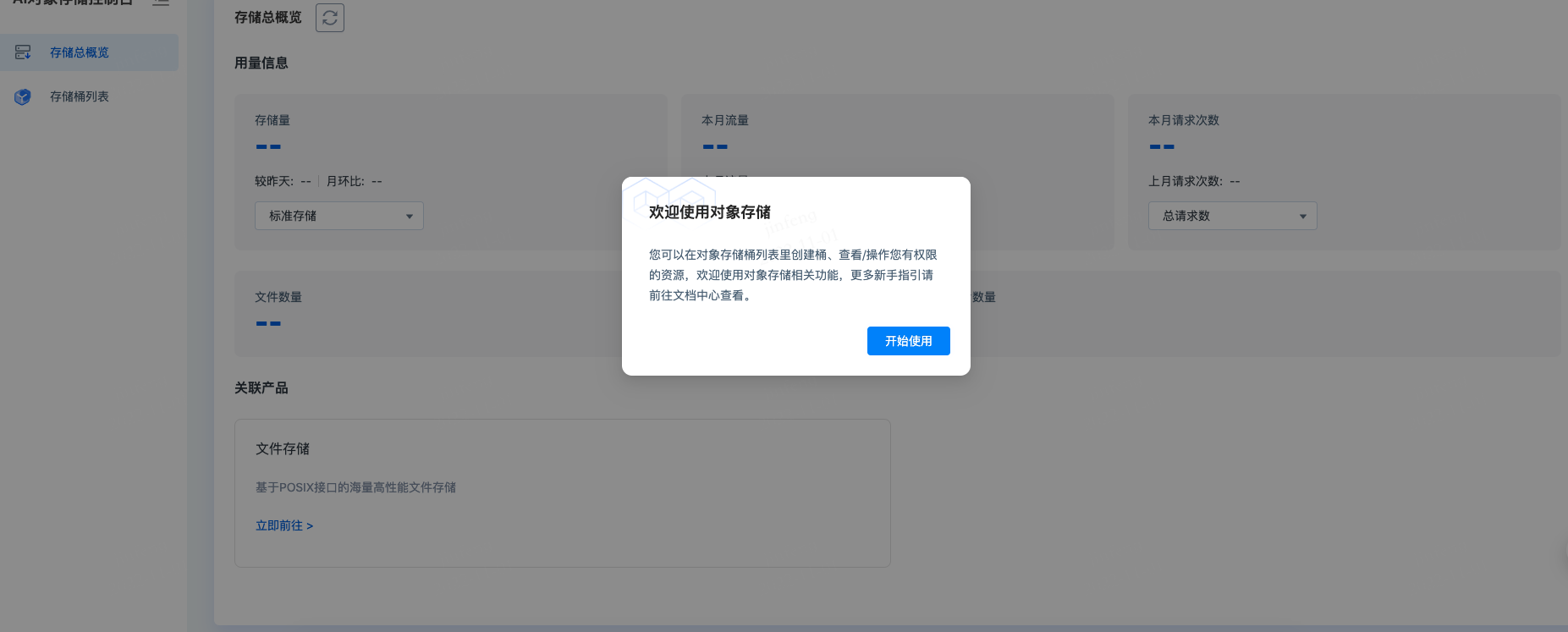
 首次进入点击【开始使用】,即可正常使用对象存储
首次进入点击【开始使用】,即可正常使用对象存储
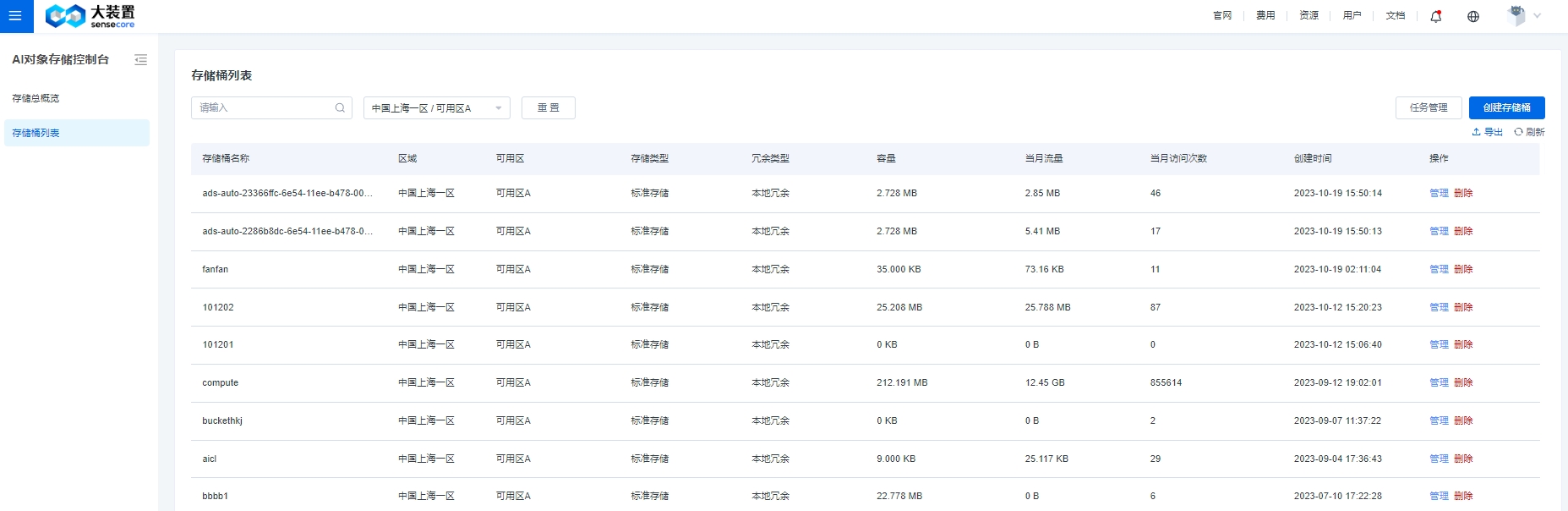
4.创建桶
购买资源成功后,回到对象存储控制台,在桶列表中即可创建桶
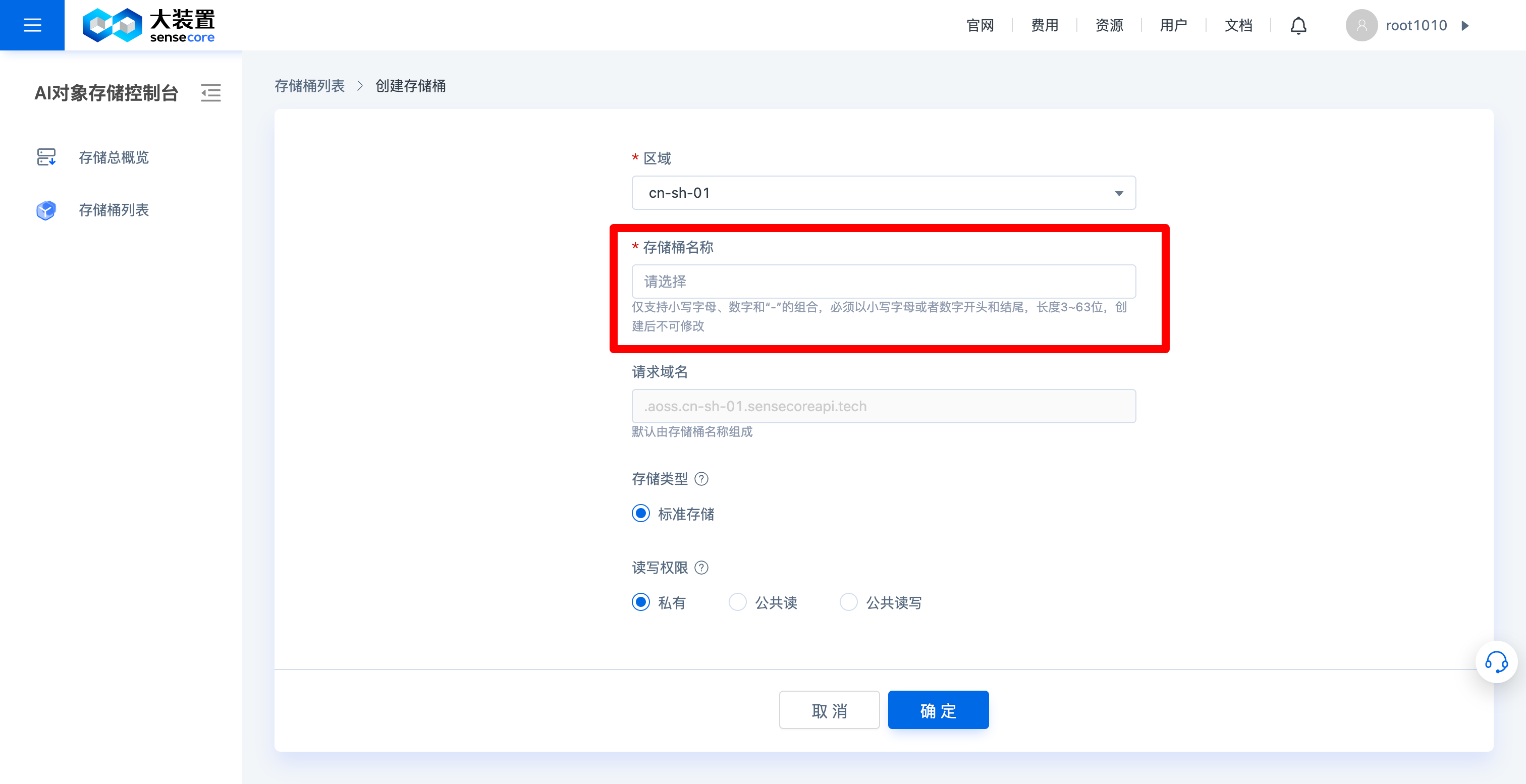
5.上传文件/目录
创建桶成功后,即可上传数据,文件数量限制为2亿(2亿为正在使用的1.0产品,2.0上线后无数量限制)
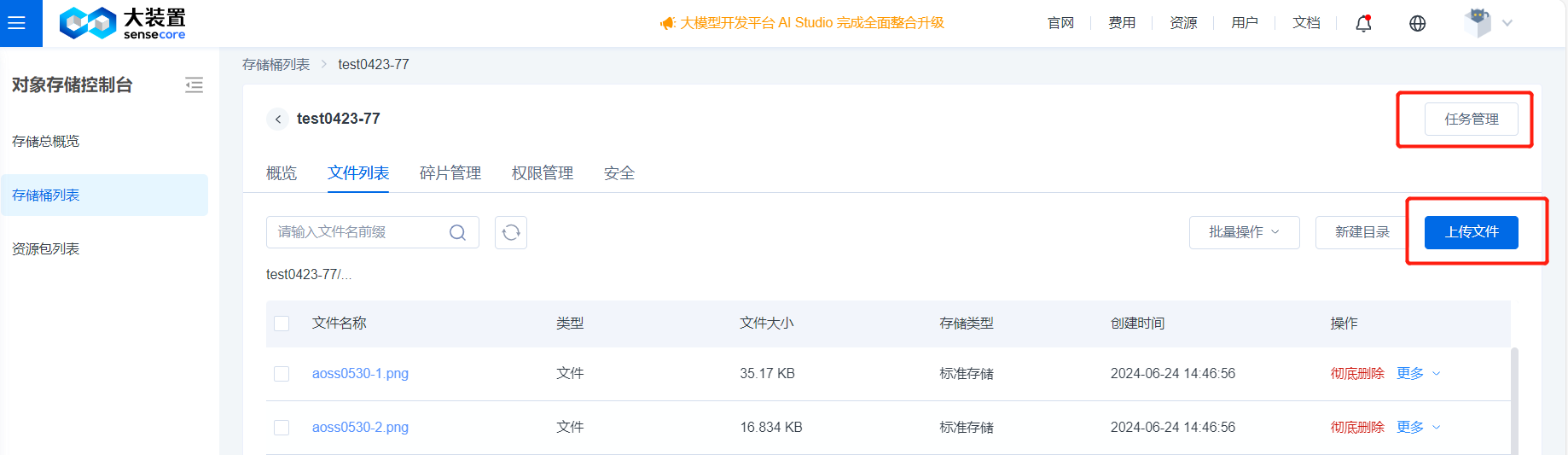
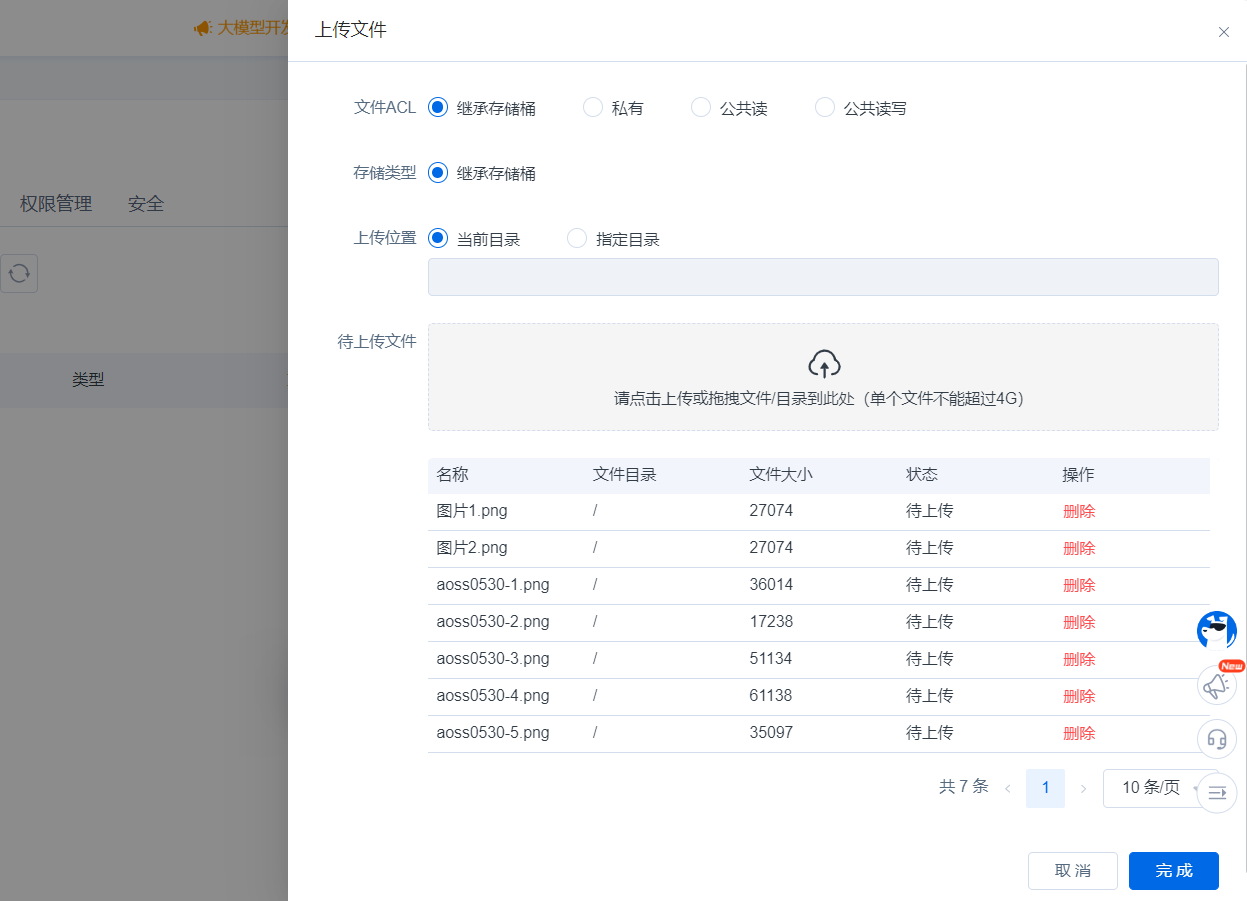
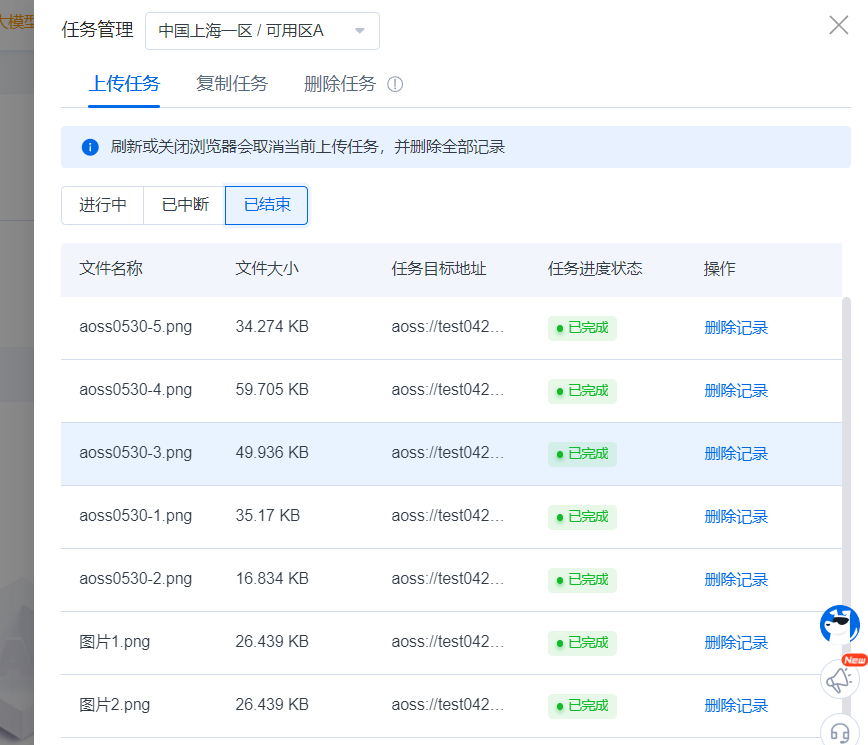
可通过点击或拖拽上传文件或文件夹,支持修改文件ACL、指定上传位置、删除无用的待上传文件。点击完成,可在任务管理列表中查看上传进度。
6.购买存储扩容资源包
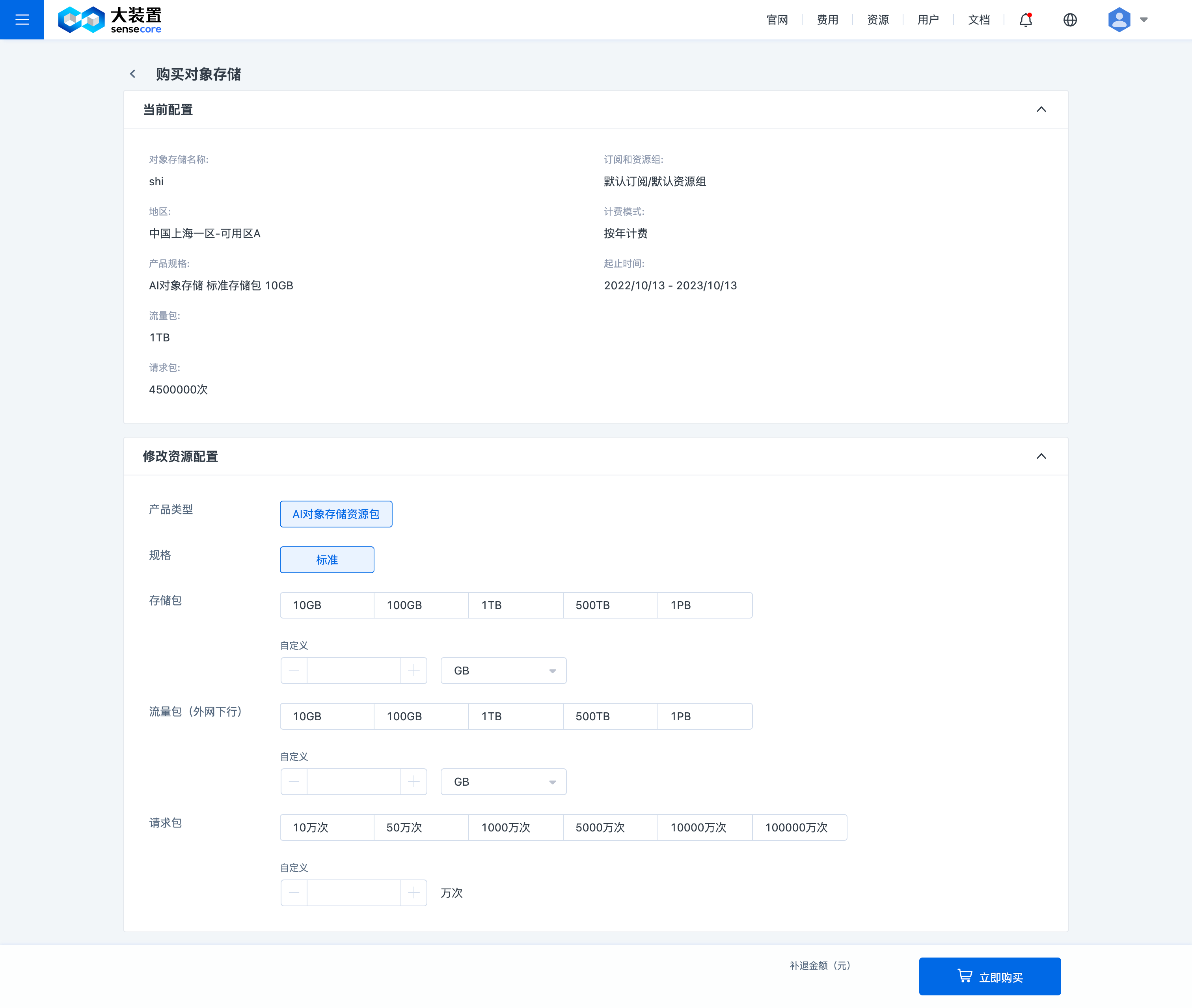
购买扩容资源包----修改资源配置:是指填写最终容量
点击右上角【购买扩容资源包】
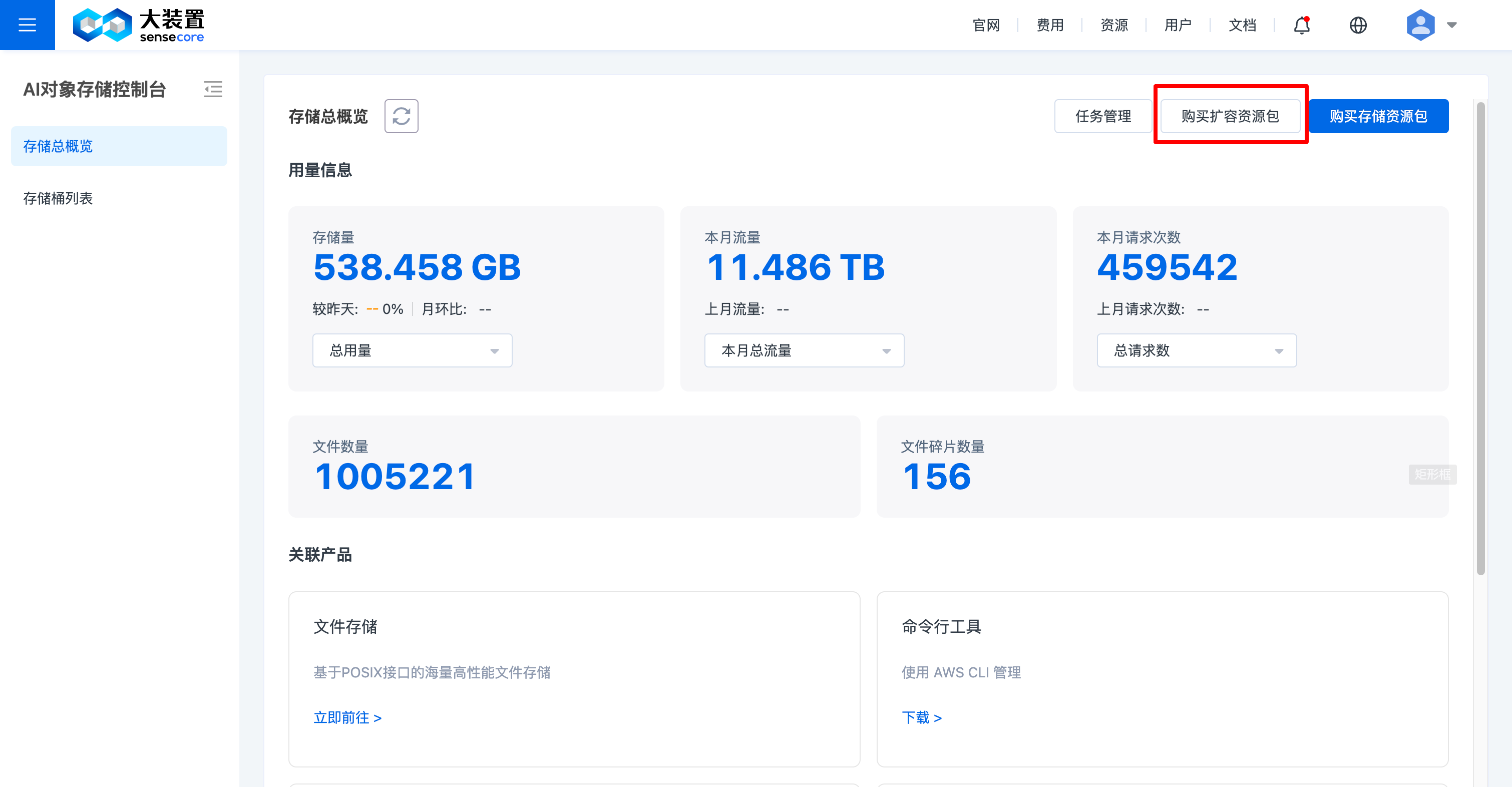
选择需要扩容的资源包类型
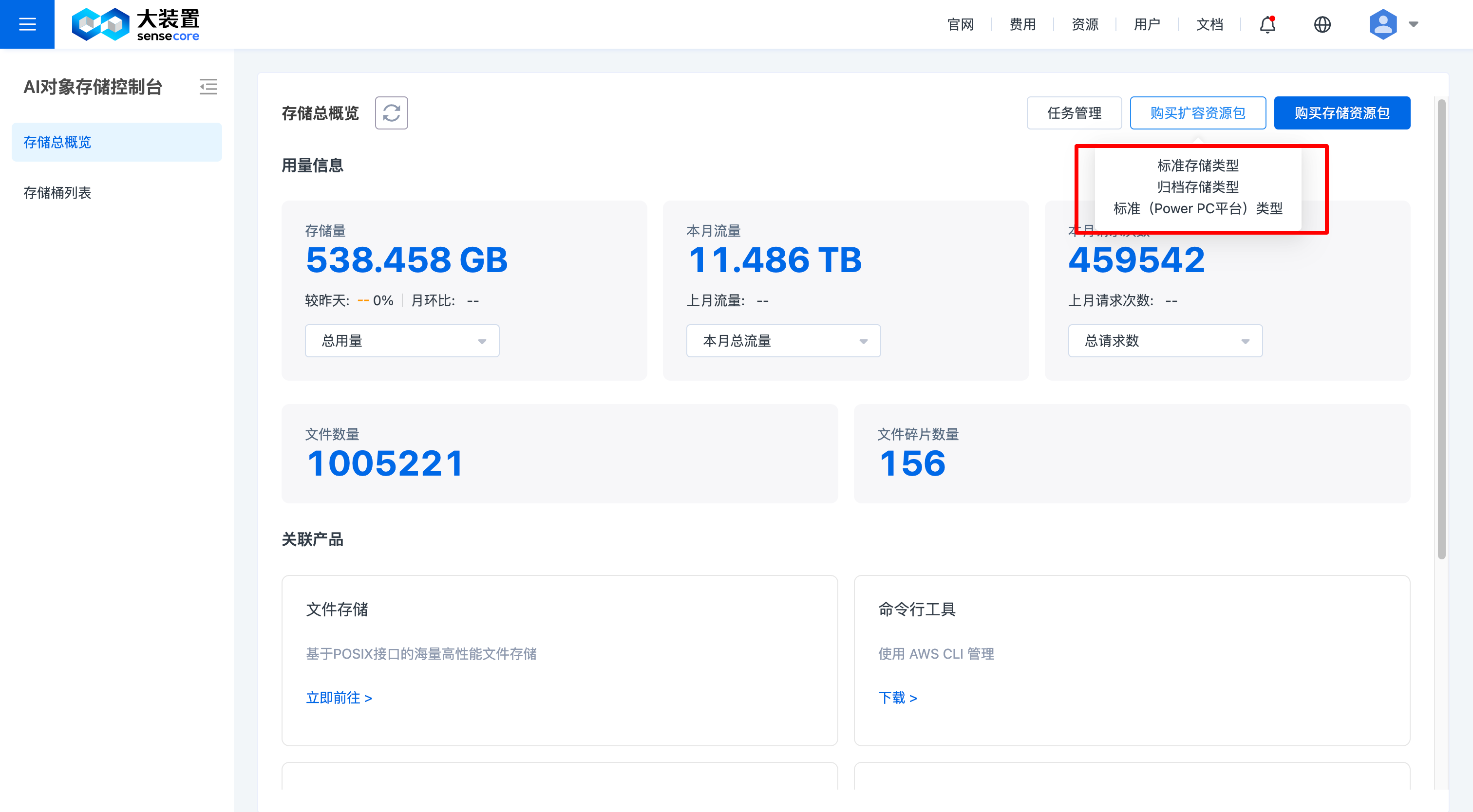
填写资源配置,资源配置是指填写最终容量
用户指南
对象存储功能主要包括:对象存储总概览、对象存储桶及对象操作及其他。以下为页面功能说明:
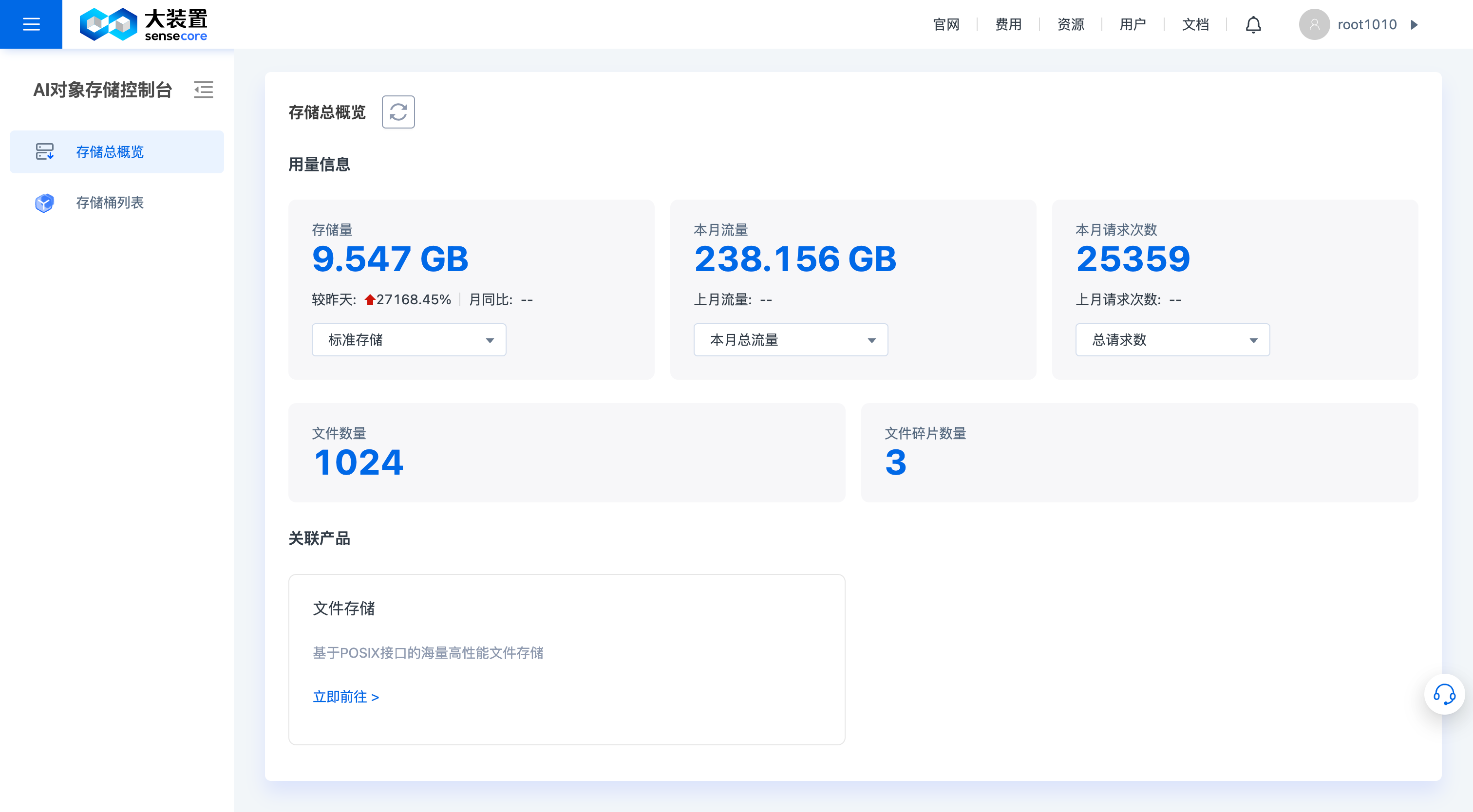
1.对象存储总概览
对象存储总概览中,支持以下功能:
- 查看存储用量总概览:支持查看各类型总存储已用量、总使用流量、总请求数、文件数量、文件碎片数。
- 跳转关联产品
数据同步服务合并到对象存储
ADS WEB服务合并到对象存储侧,功能与以前保持一致(24.10.30版本)
2.对象存储桶操作
a.查看对象存储桶列表
对象存储控制台支持对象存储桶的相关操作,具体包括:
- 支持创建桶、搜索桶、删除桶、下载当前桶列表
- 支持管理桶(详见3.对象存储桶内操作)
- 新增可用区B选择(2030.10.30)
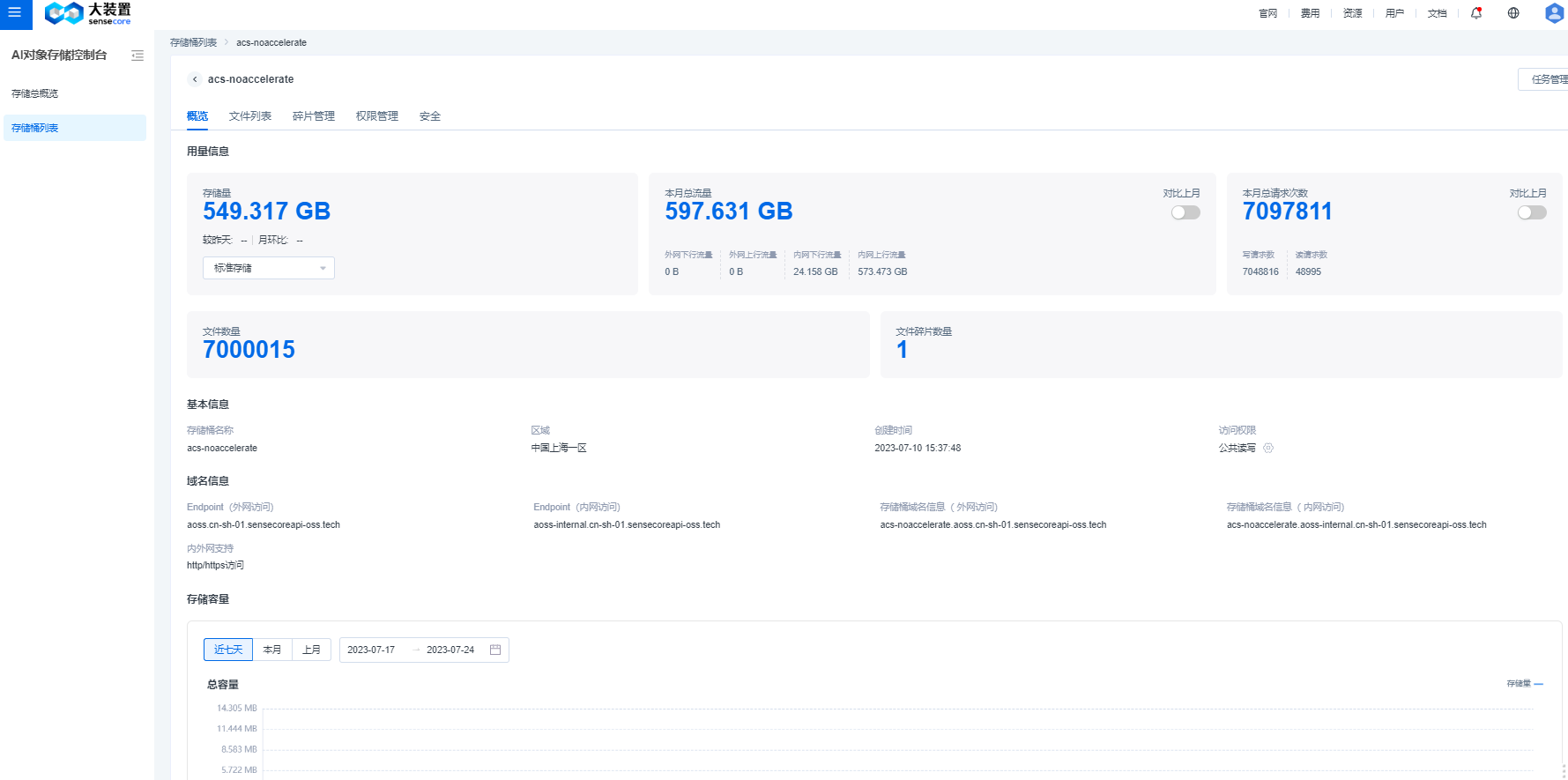
b.查看对象存储桶概览
- 桶概览中,支持查看该桶的基本用量信息、访问域名信息、基本监控指标(容量、流量、请求数)
c.查看对象存储桶文件列表及文件详情
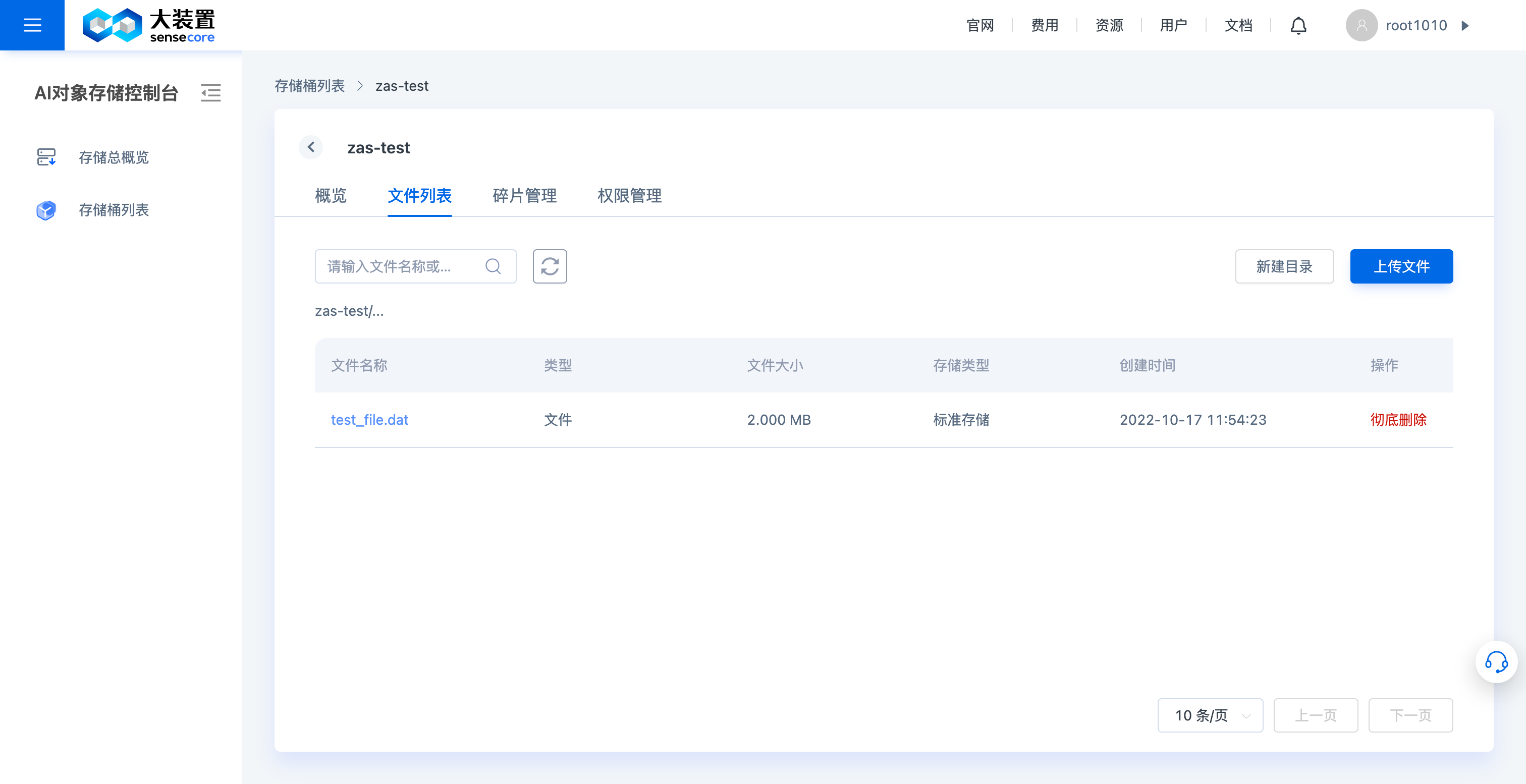
支持查看桶文件列表
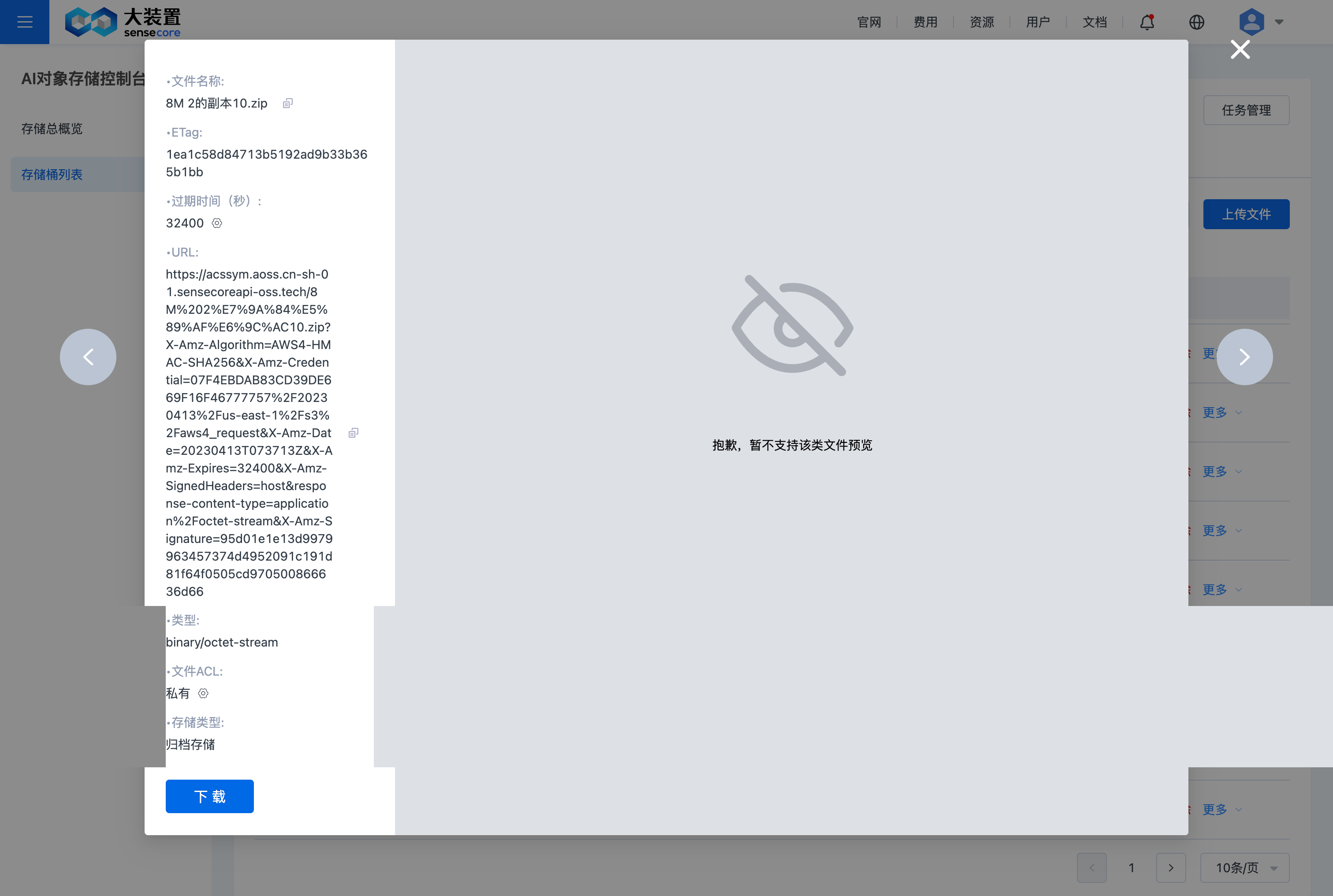
支持查看桶文件的详情,支持主流图片格式和文本格式预览。
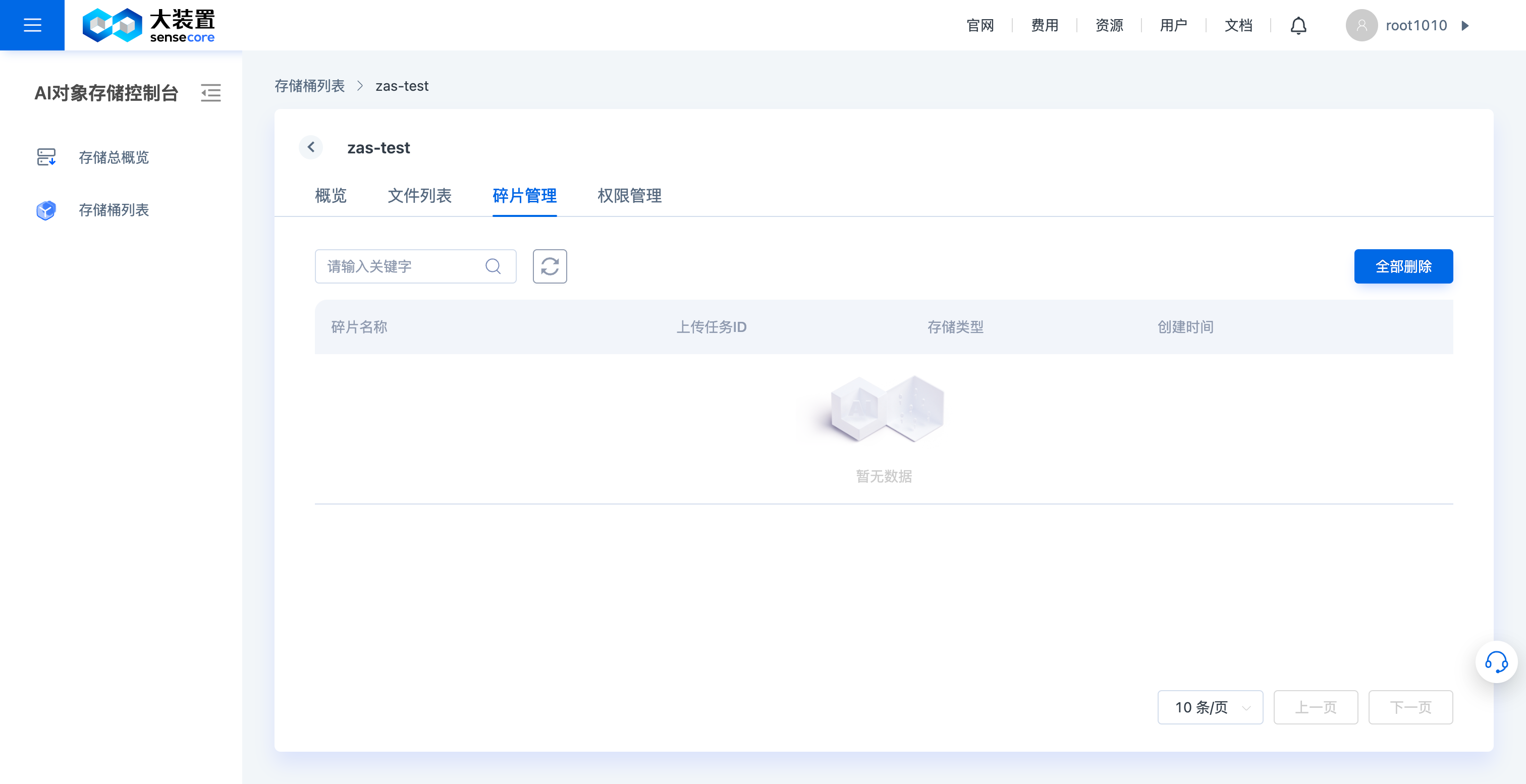
d.对象存储桶碎片管理
- 碎片管理页面中,支持手动删除桶内文件碎片(文件碎片会占用存储空间)
e.对象存储权限设置管理
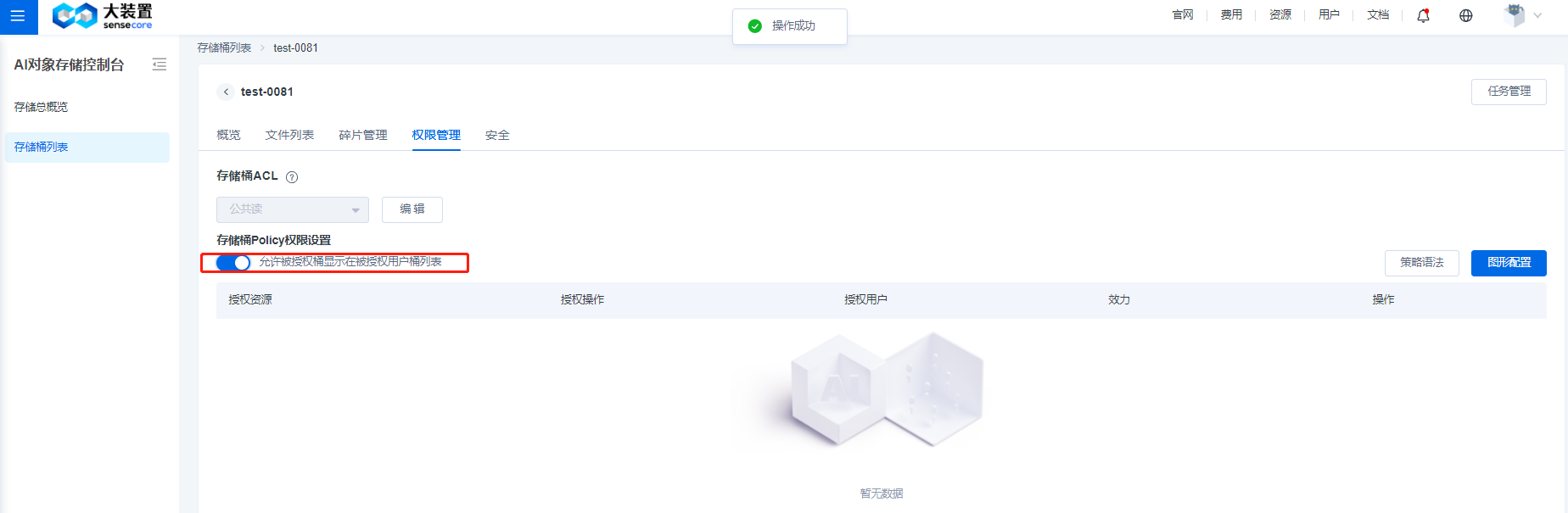
权限策略支持3种类型策略的添加:存储桶ACL、存储桶权限策略、关联IAM(暂未上线)
- 存储桶ACL支持对桶设置访问ACL
- 存储桶权限策略支持原生的桶权限策略,可以通过图形界面或策略语法进行设置
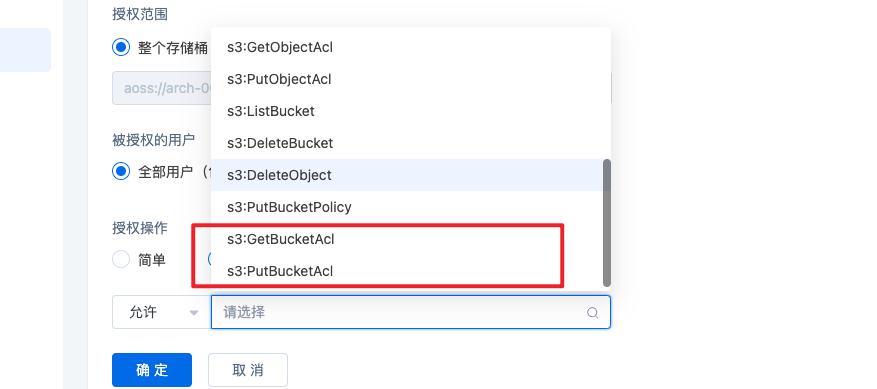
- 打开策略开关(默认关闭),支持允许被授权桶显示在被授权用户桶列表,如果想要授权的用户看到桶的endpoint信息,可以在图形配置【高级】允许里面添加getbucketacl,putbucketacl选项可以修改桶权限。
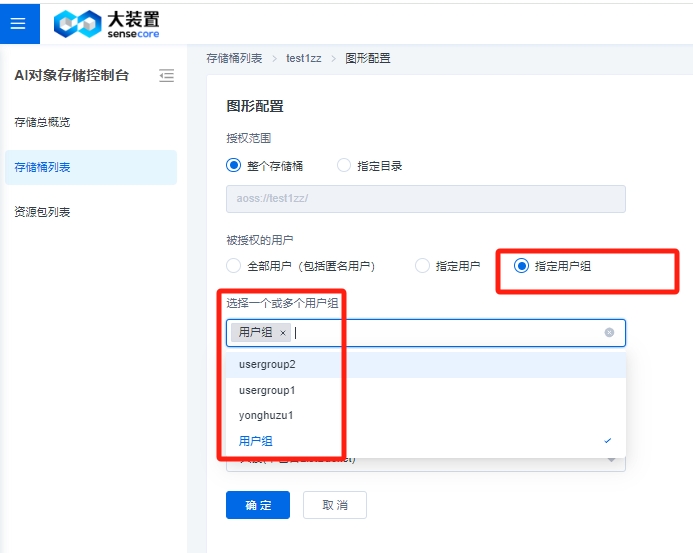
其中,权限策略图形配置中,【全部用户】指【SenseCore的所有用户】,【指定用户】中的【其他用户ID】指【跨租户的用户ID】,新增加【指定用户组】选项,可以选择下拉列表中的用户组。
当使用【指定用户组】可以选择对应的用户组,点击确定,会在桶策略表里展示。
注:如果是子账号选择【指定用户组】,必须先让管理员为子账号在IAM侧授予组权限。
"..."可以展示用户组下的所有用户 ,如果后期增加新用户,可以在编辑里面增加新的用户添加到这个组。
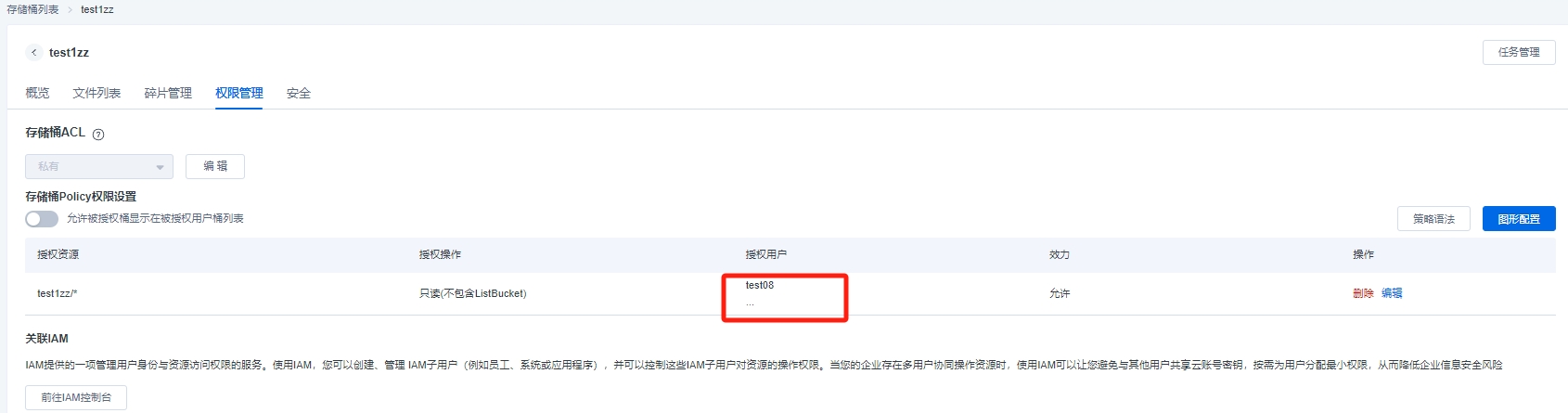
点击【编辑】弹出对话框,自动回到指定用户选择,可以在下拉表,选择新用户,点击确定,新用户就增加到用户组中。
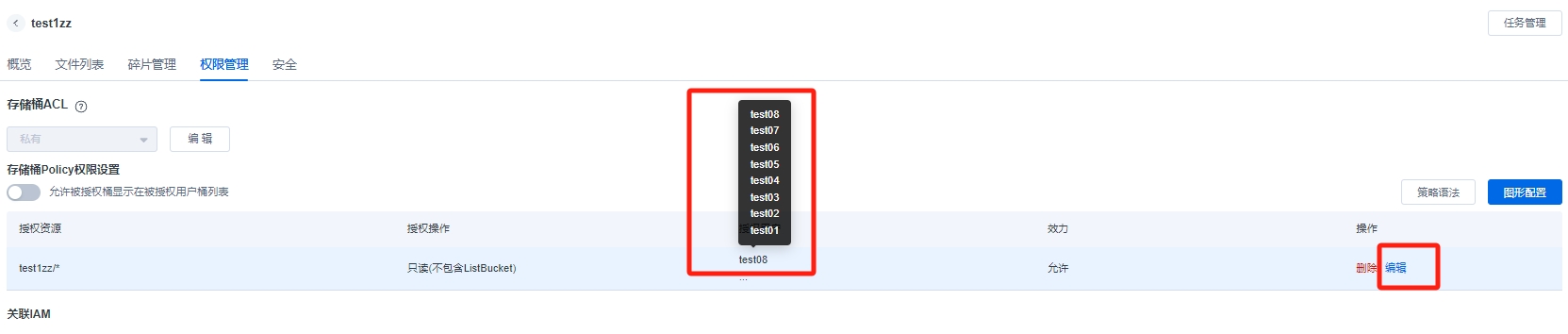

删除策略
使用语法删除相关桶的方法:
按图示打开【策略语法界面】
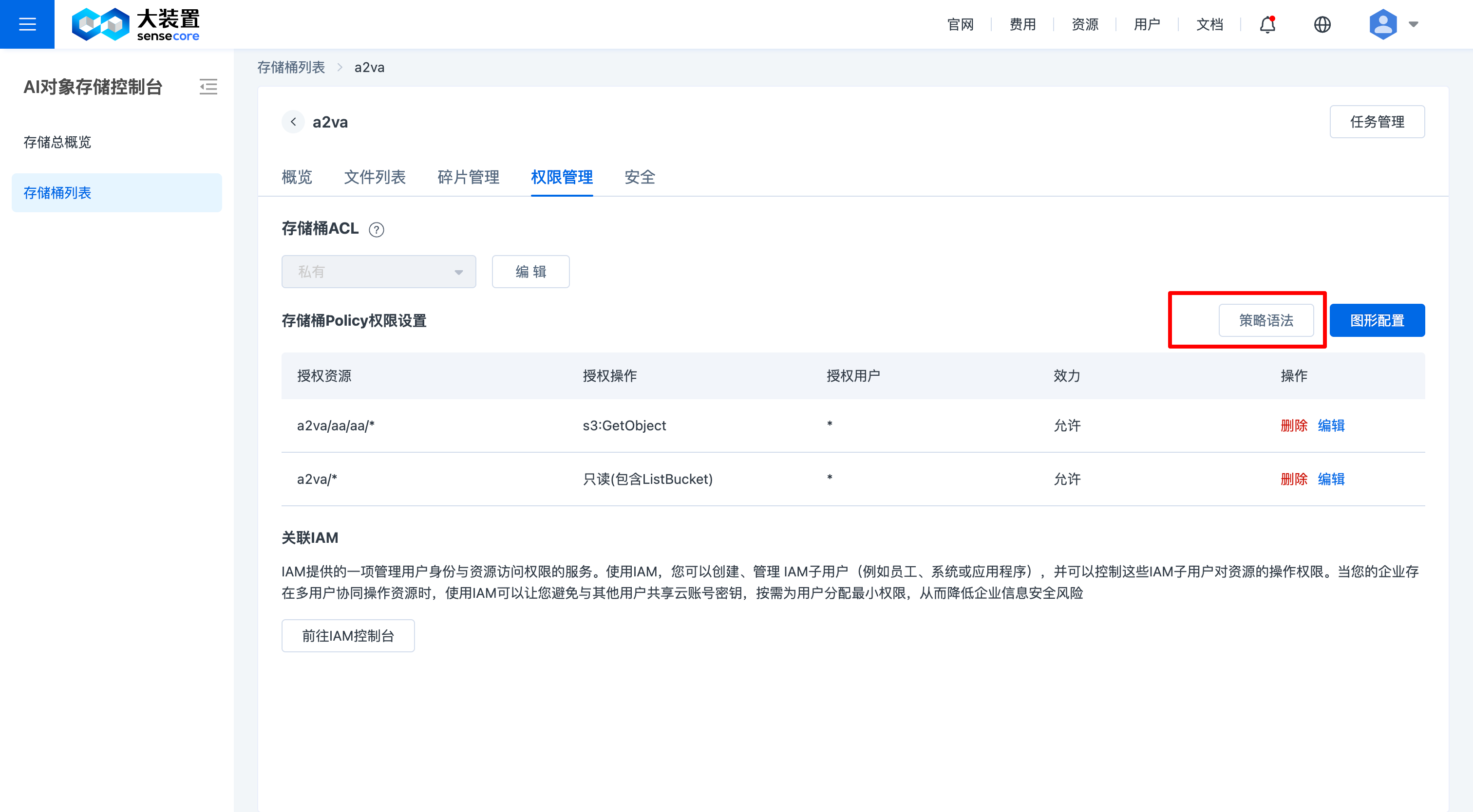
在图示位置根据需要添加代码
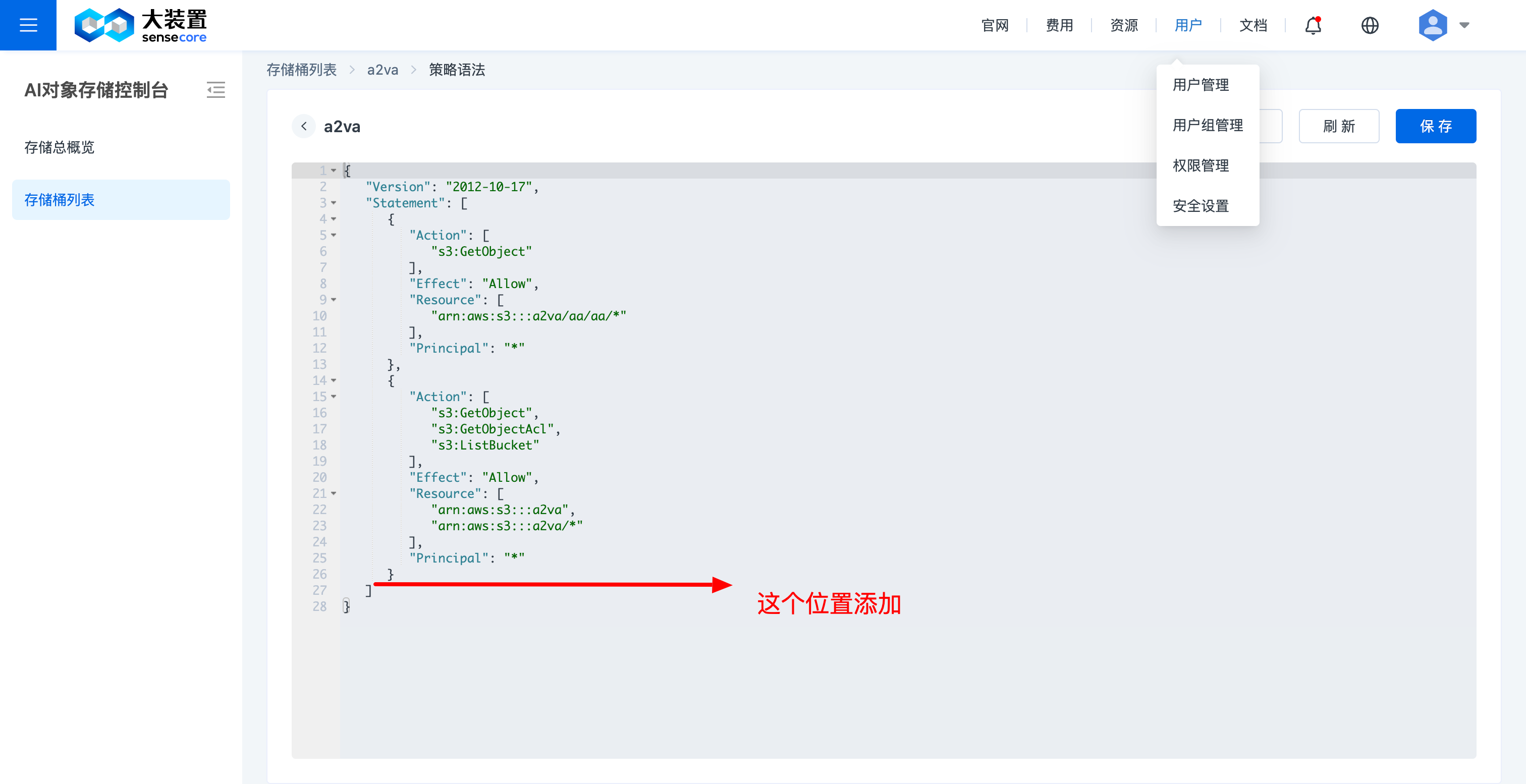
授予删除权限相关策略 3.1 赋予所有用户删除对象权限 (整段复制)
{
"Action": [
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
// 填写操作资源地址,bucket替换成桶名称;folder1替换成具体的路径;如有多个,以,分隔
"arn:aws:s3:::bucket/*",
"arn:aws:s3:::bucket/folder1/*"
],
"Principal": "*"
}
3.2 赋予指定用户删除对象权限 (整段复制)
{
"Action": [
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
//填写操作资源地址,bucket替换成桶名称;folder1替换成具体的路径;如有多个,以,分隔
"arn:aws:s3:::bucket/*",
"arn:aws:s3:::bucket/folder1/*"
],
"Principal": {
"AWS": [ //将其中【uid1】替换为指定用户ID
"arn:aws:iam:::user/uid1",
"arn:aws:iam:::user/uid2"
]
}
}
存储桶禁止外网访问
更新时间:2024.04.30
适用于01a(1.0)对象存储桶策略。 01b(2.0)对象存储需要提单支持。
本期主要操作方法为桶策略的语法策略方式。
主要是通过Condition的方式,定义除了内网网段的IP可以访问桶资源,其余IP判断为外网,拒绝访问。用户想要知道内网网段的IP信息,请联系与您对接的相关技术人员。
语法策略如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3:*",
"Effect": "Deny",
"Resource": [
"arn:aws:s3:::DOC-EXAMPLE-BUCKET",
"arn:aws:s3:::DOC-EXAMPLE-BUCKET/*"
],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": [
"X.X.X.X/8",
"X.X.X.X/12",
"X.X.X.X/16"
]
}
},
"Principal": "*"
}
]
}
f.对象存储桶安全管理(桶加密)
- 支持对已创建未加密的桶进行安全设置修改,可修改成已加密,支持服务端加密;不支持自定义密钥;
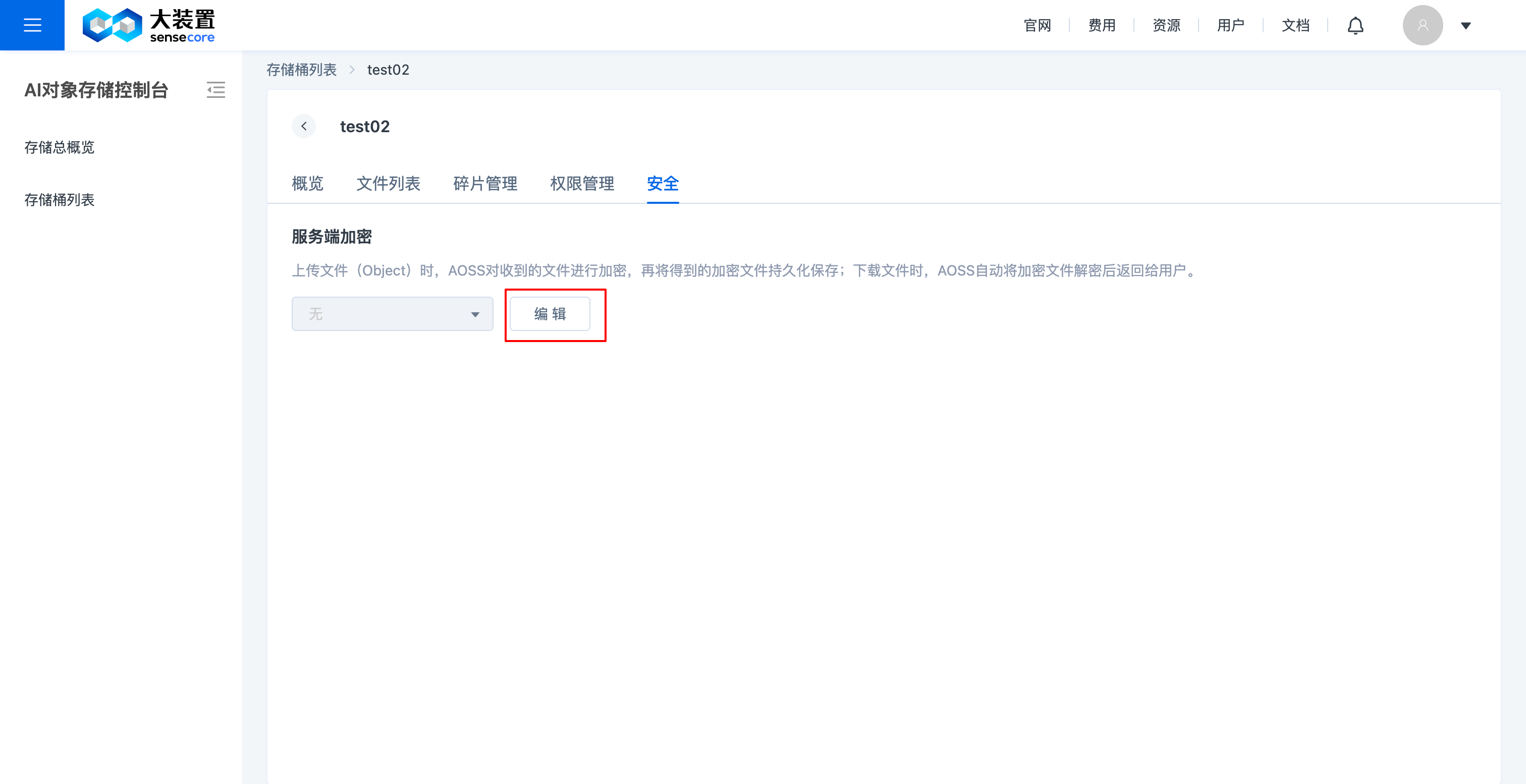
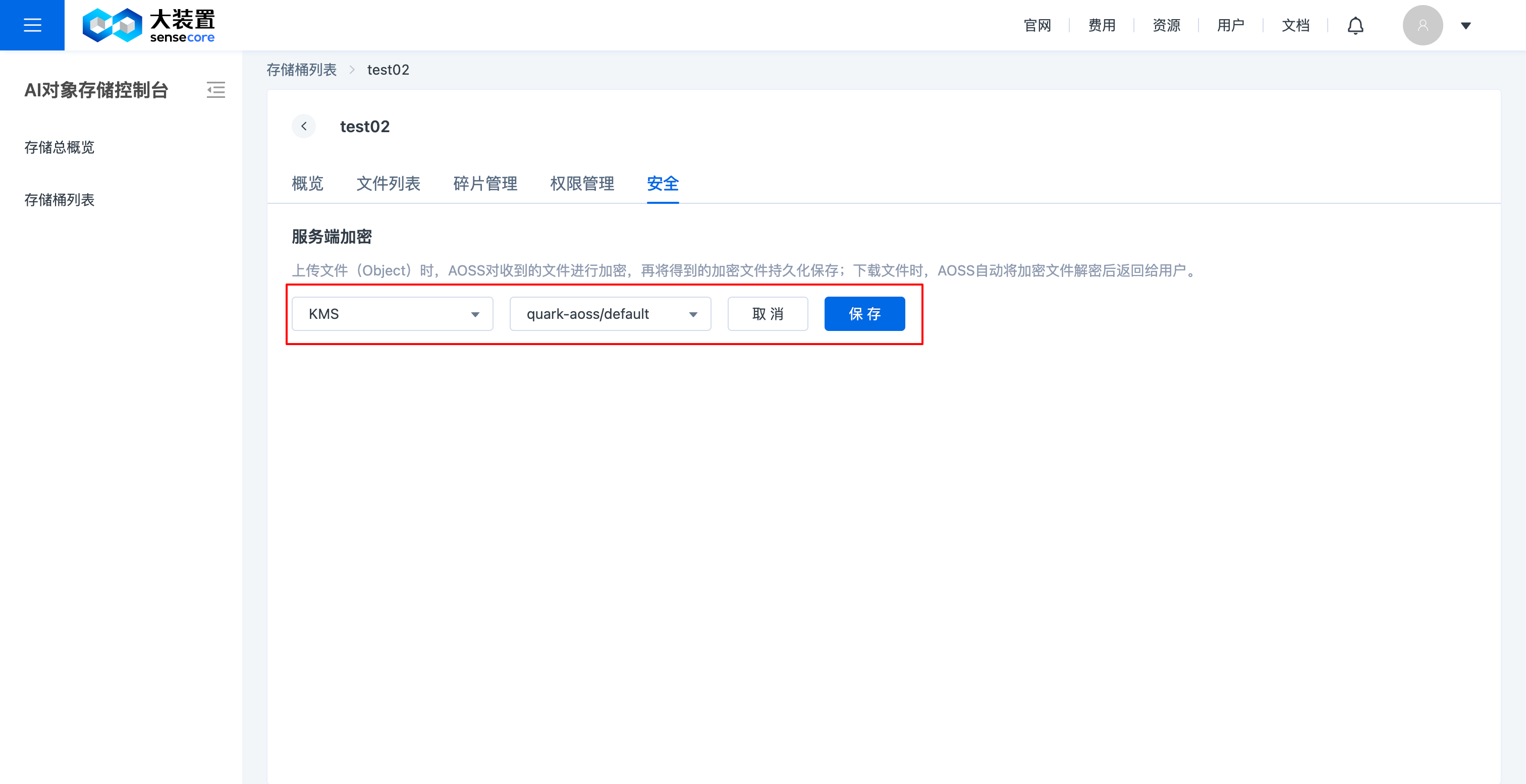
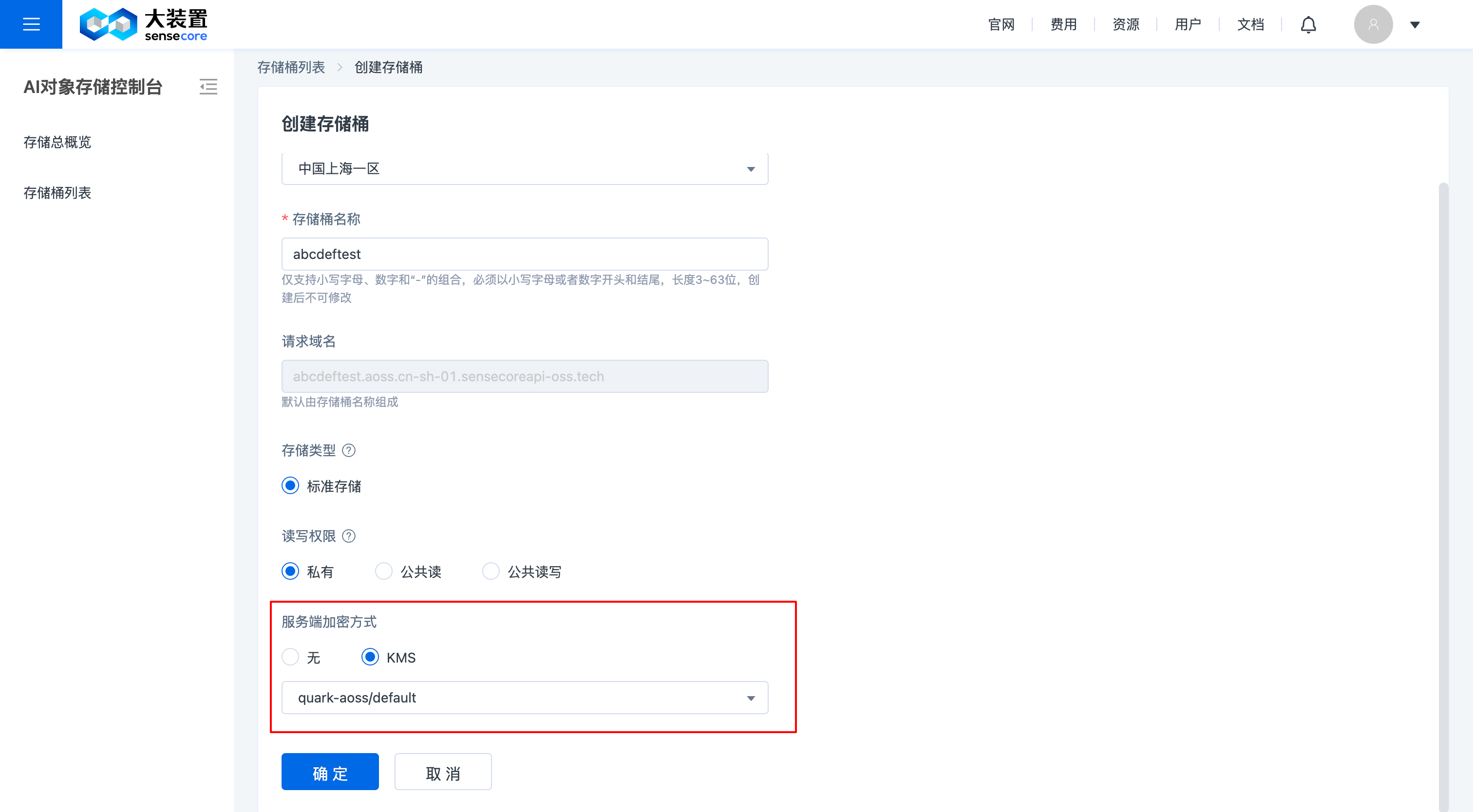
- 支持在创建桶时设置桶加密
3.对象存储桶内操作及对象操作
对象存储控制台支持对桶内对象进行操作
a.查看桶文件列表,在桶文件列表中,支持对桶内对象进行操作,包括:上传文件、下载文件、创建目录、搜索文件、查看文件详情、删除文件
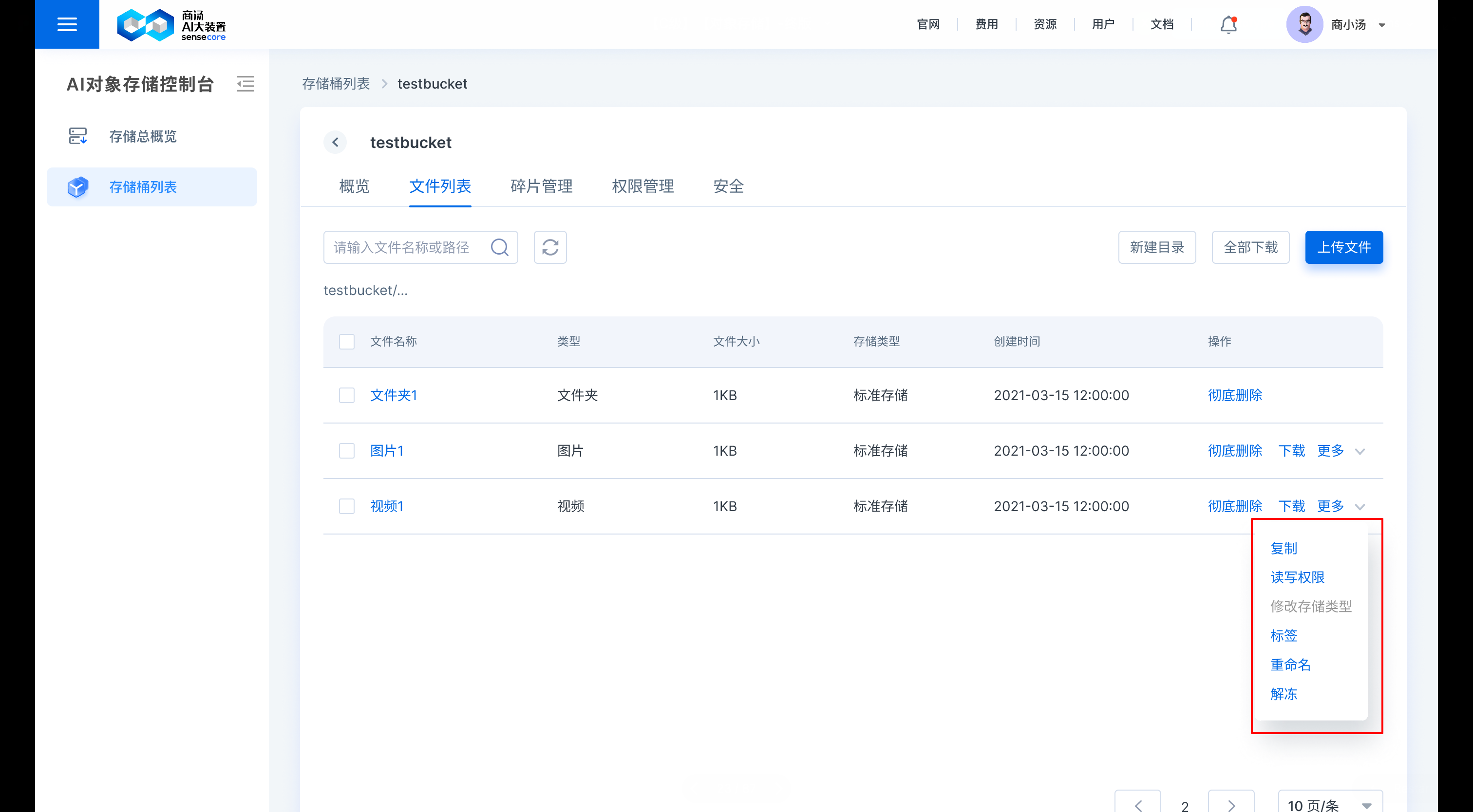
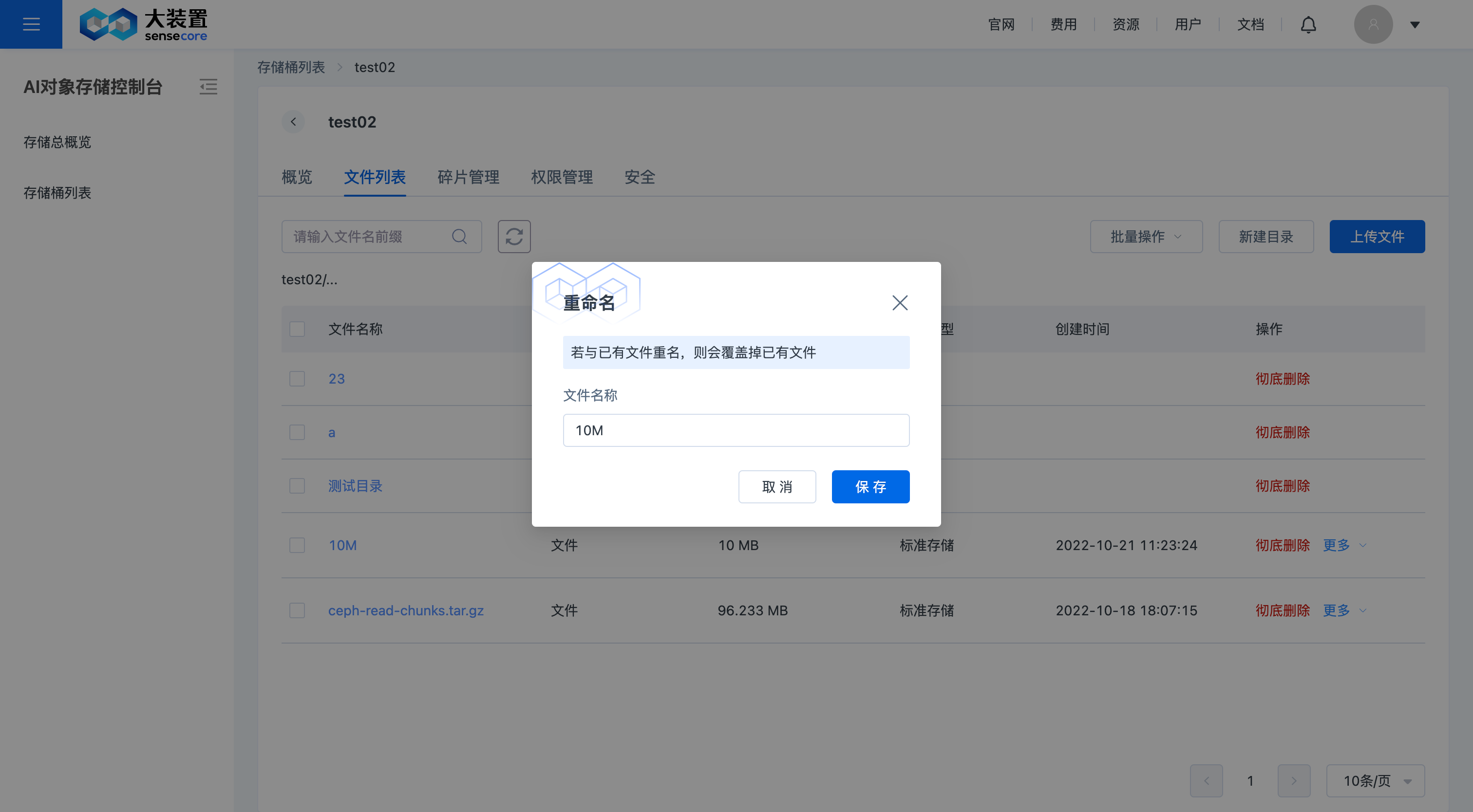
b.支持重命名文件
在需要修改的文件后,点击【更多】,选择【重命名】,即可重命名文件
b.支持为文件添加标签
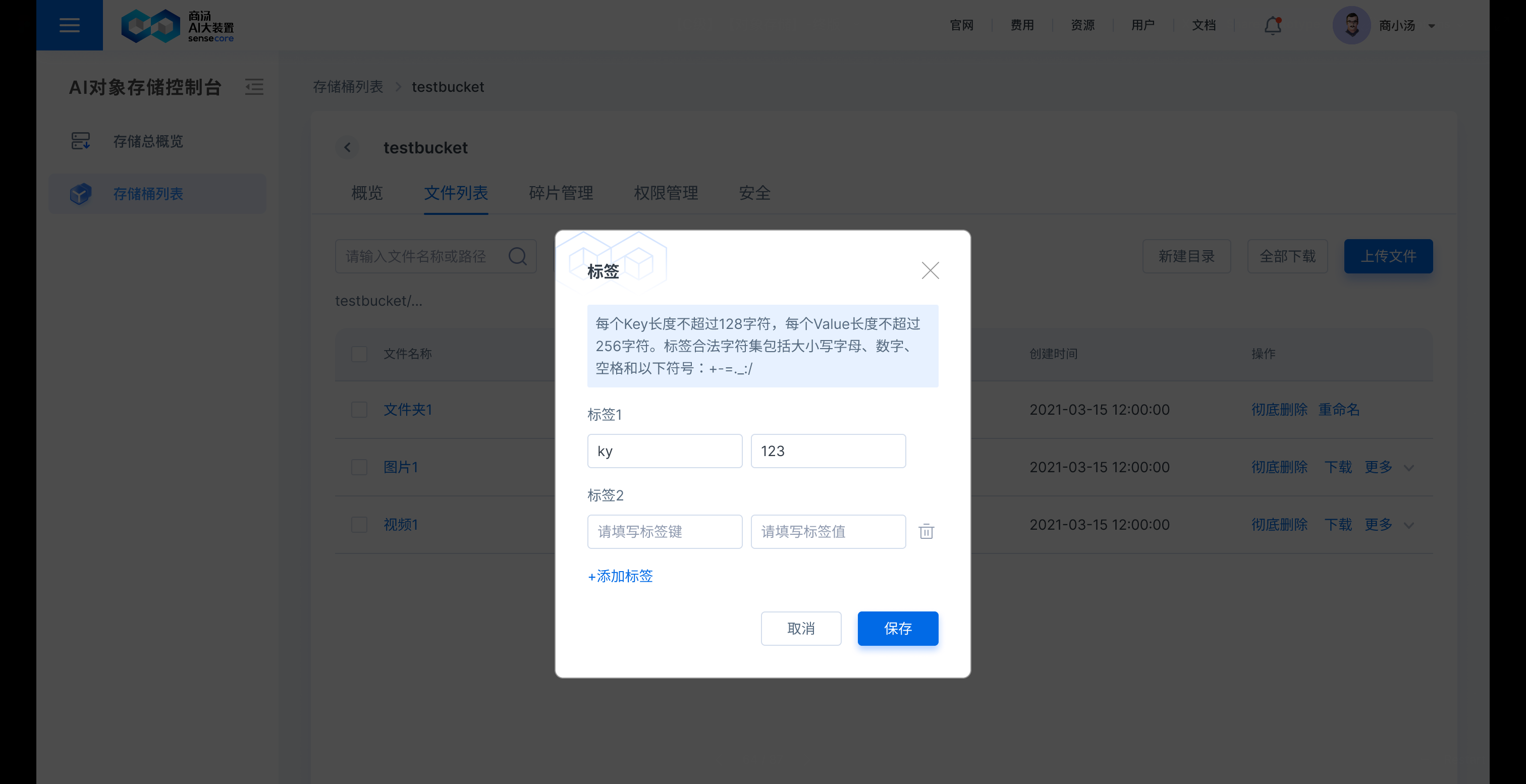
在需要添加标签的文件后,点击【更多】,选择【标签】,即可添加或修改文件标签,历史添加的标签也可以在此处查看、修改、删除
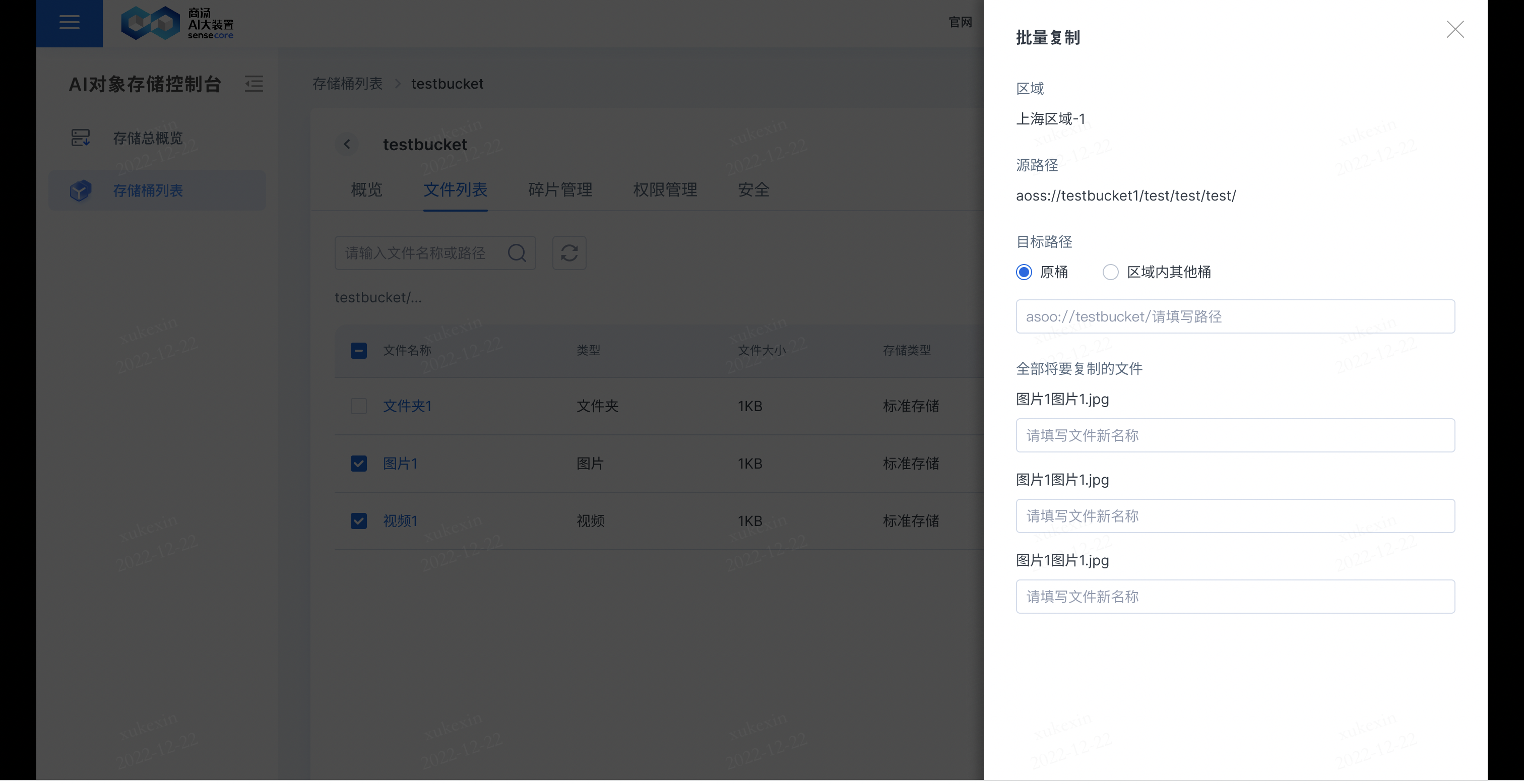
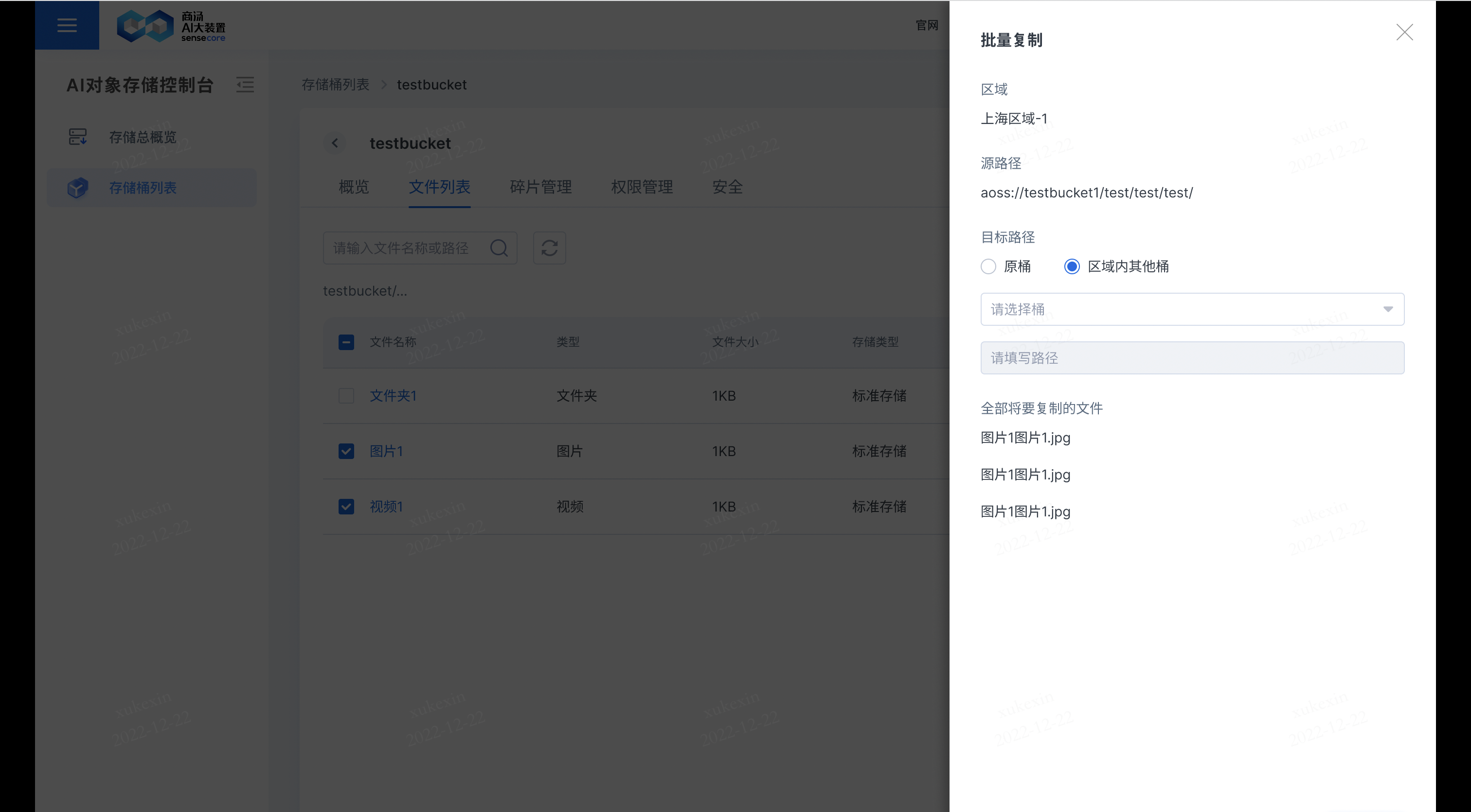
b.支持复制文件
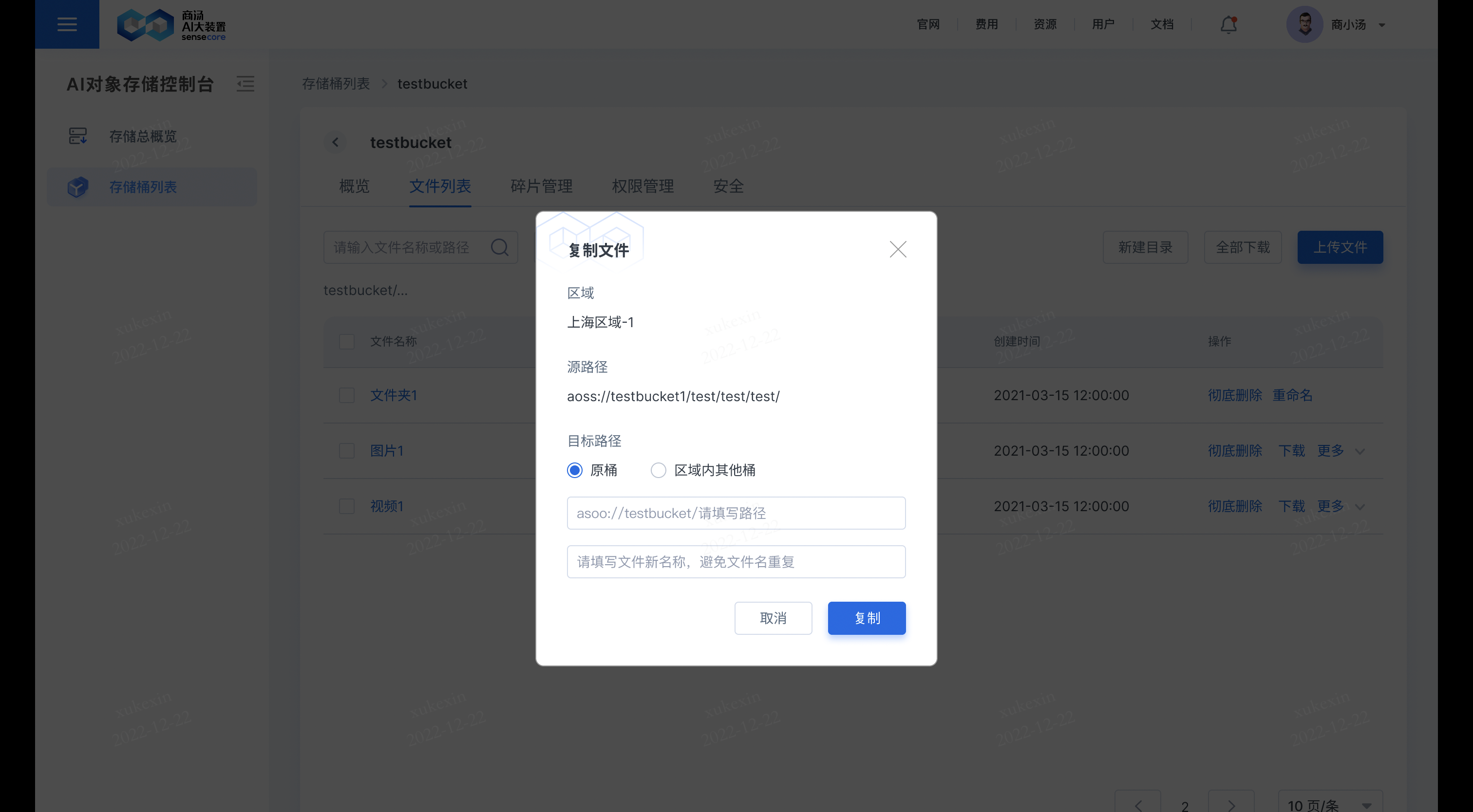
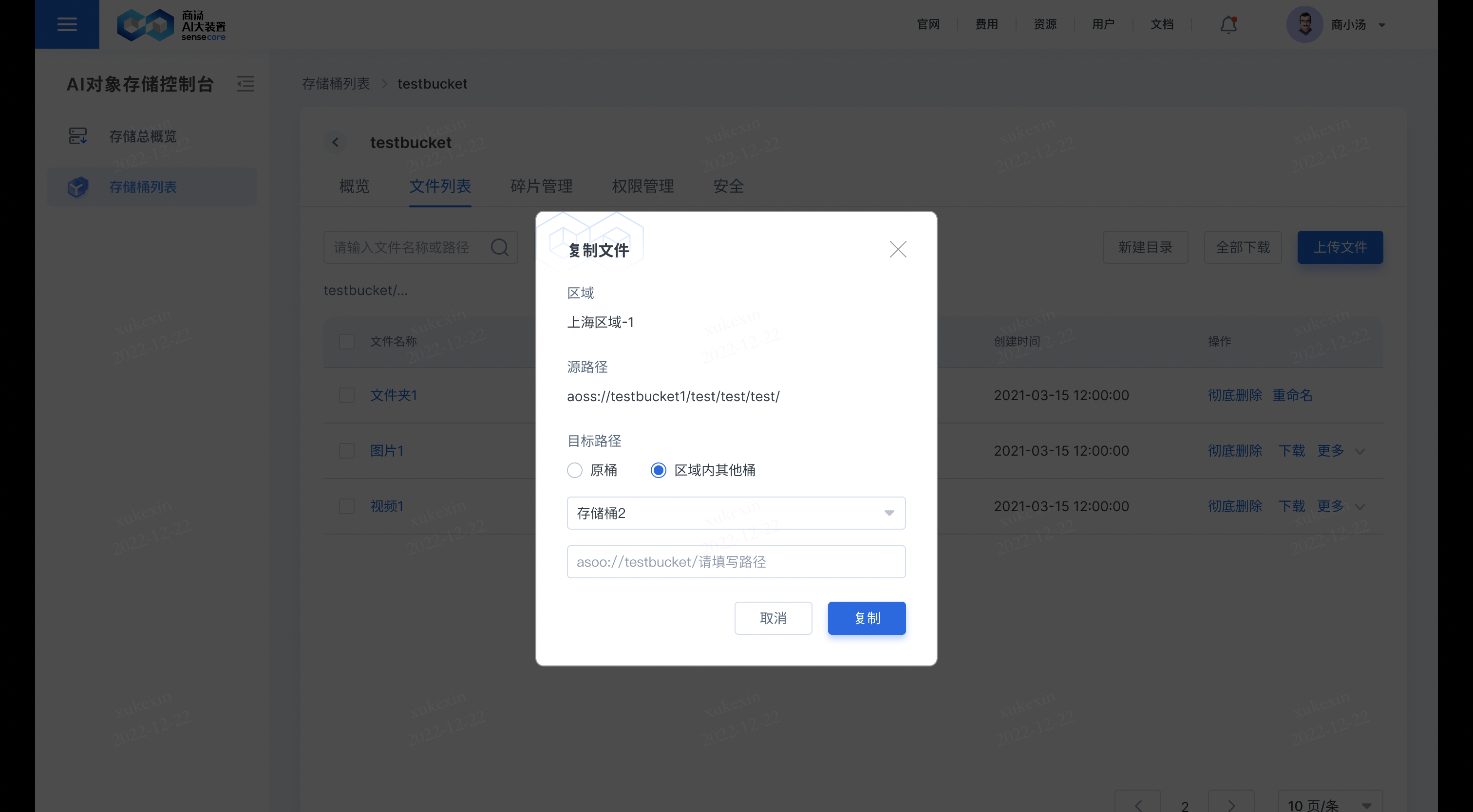
在需要复制的文件后,点击【更多】,选择【复制】,即可复制文件到其他桶或原桶;若复制到原桶,需要重新填写新的文件名;若复制到其他桶,其他桶存储同名文件,其他桶同名文件会被覆盖。
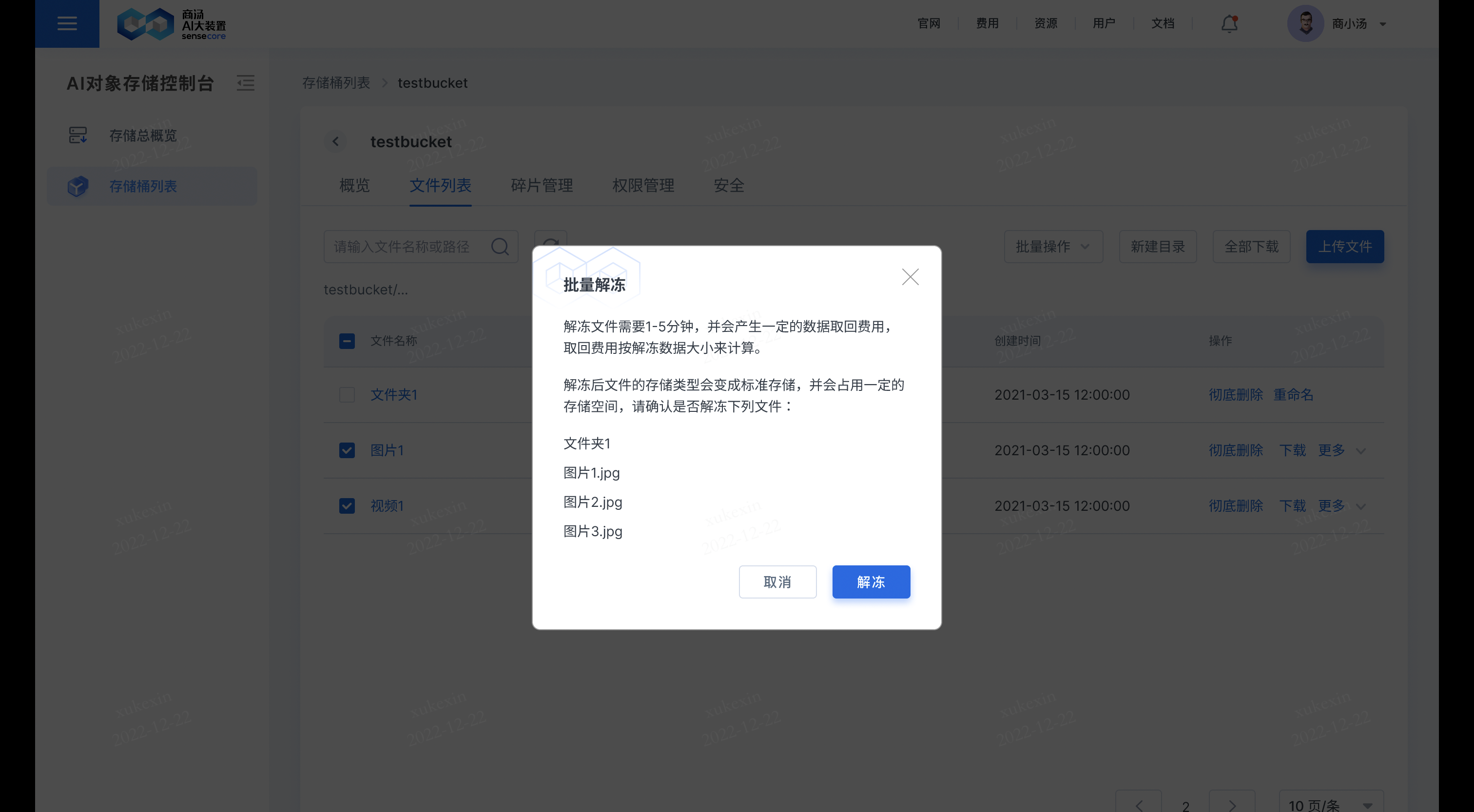
b.支持解冻归档类型的文件,解冻后一段时间内可读
在需要解冻的文件后,点击【更多】,选择【解冻】,即可解冻文件。
该功能仅存储类型为归档存储的文件支持;
点击解冻后,对应的文件原有的【解冻】会变成【解冻中】状态,解冻完成后即可下载。
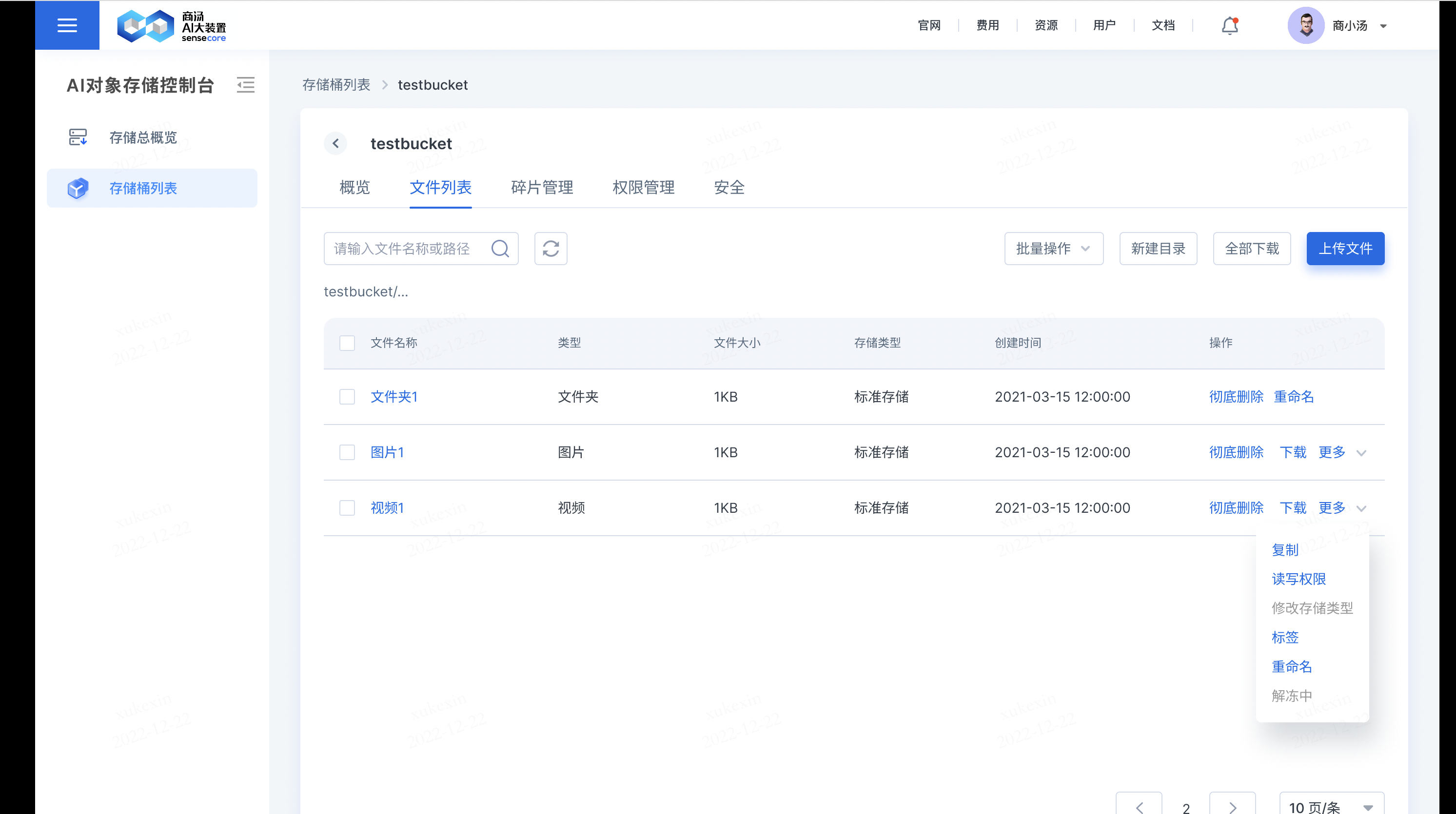
b.支持在文件列表中批量对文件进行操作
批量操作包括:批量删除、导出url列表、批量复制、批量下载、批量解冻
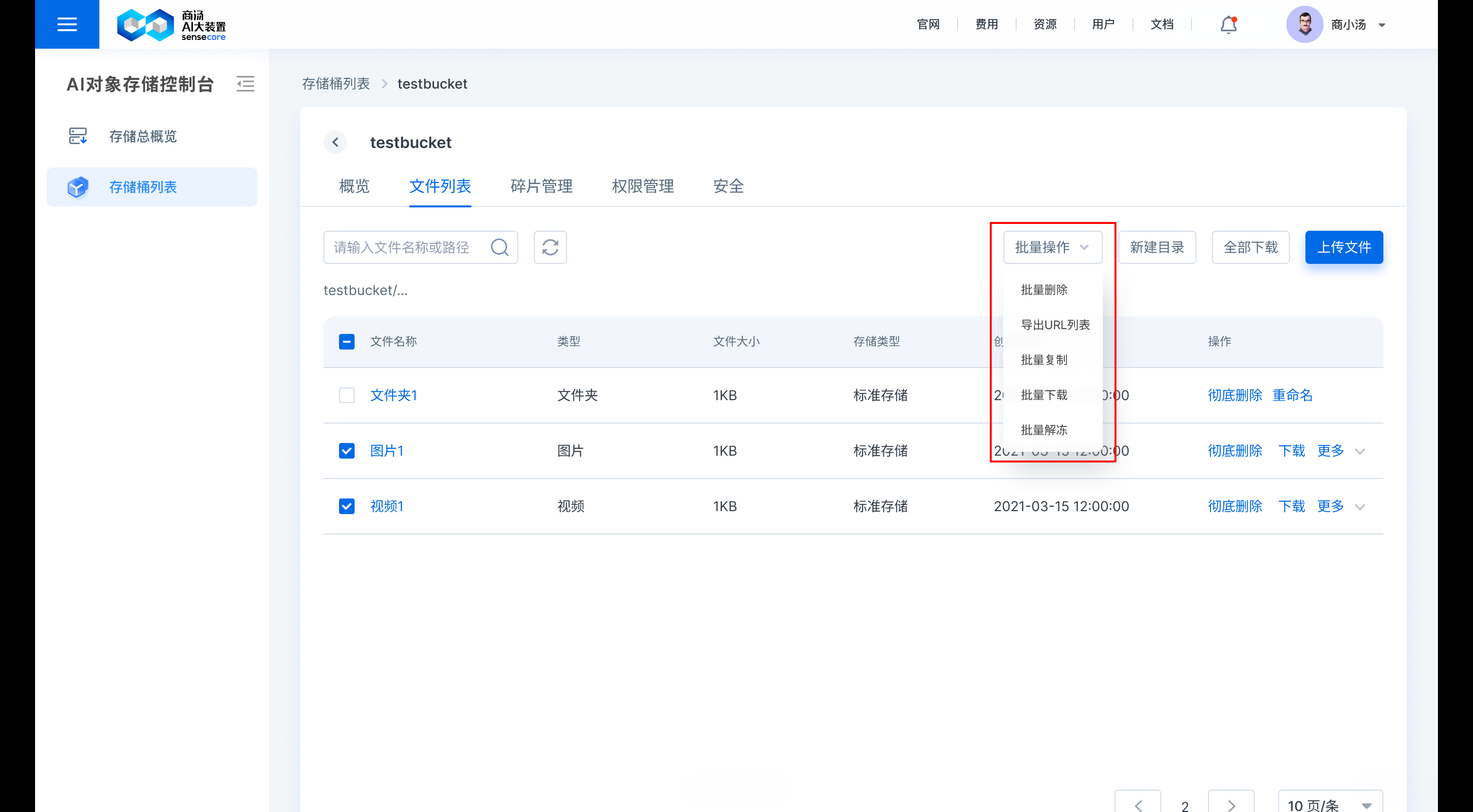
- 批量删除
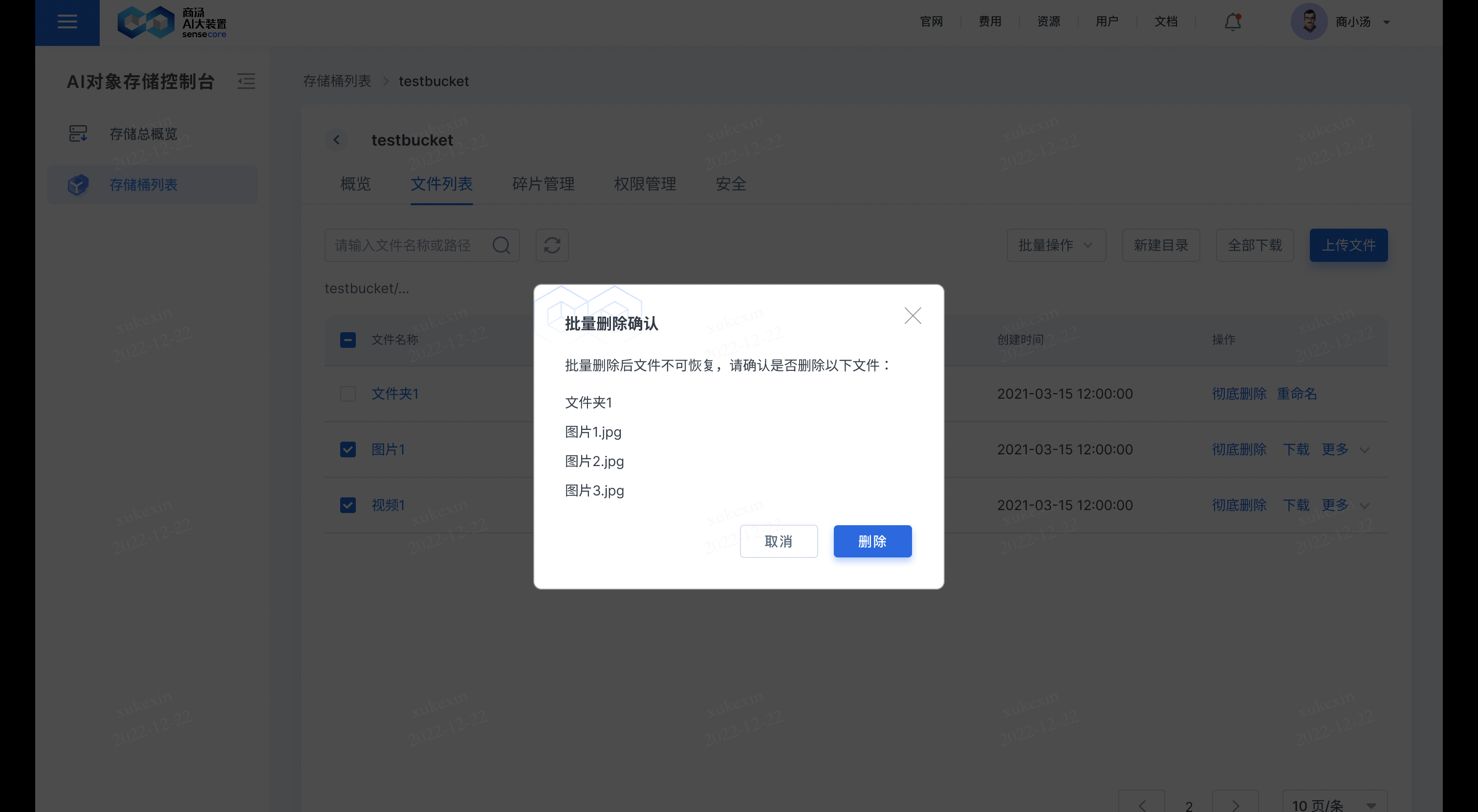
- 导出url列表
- 批量复制
- 批量解冻
b.支持为图片添加明文水印
支持添加平台明文水印
4.任务管理
任务管理入口
上传任务管理
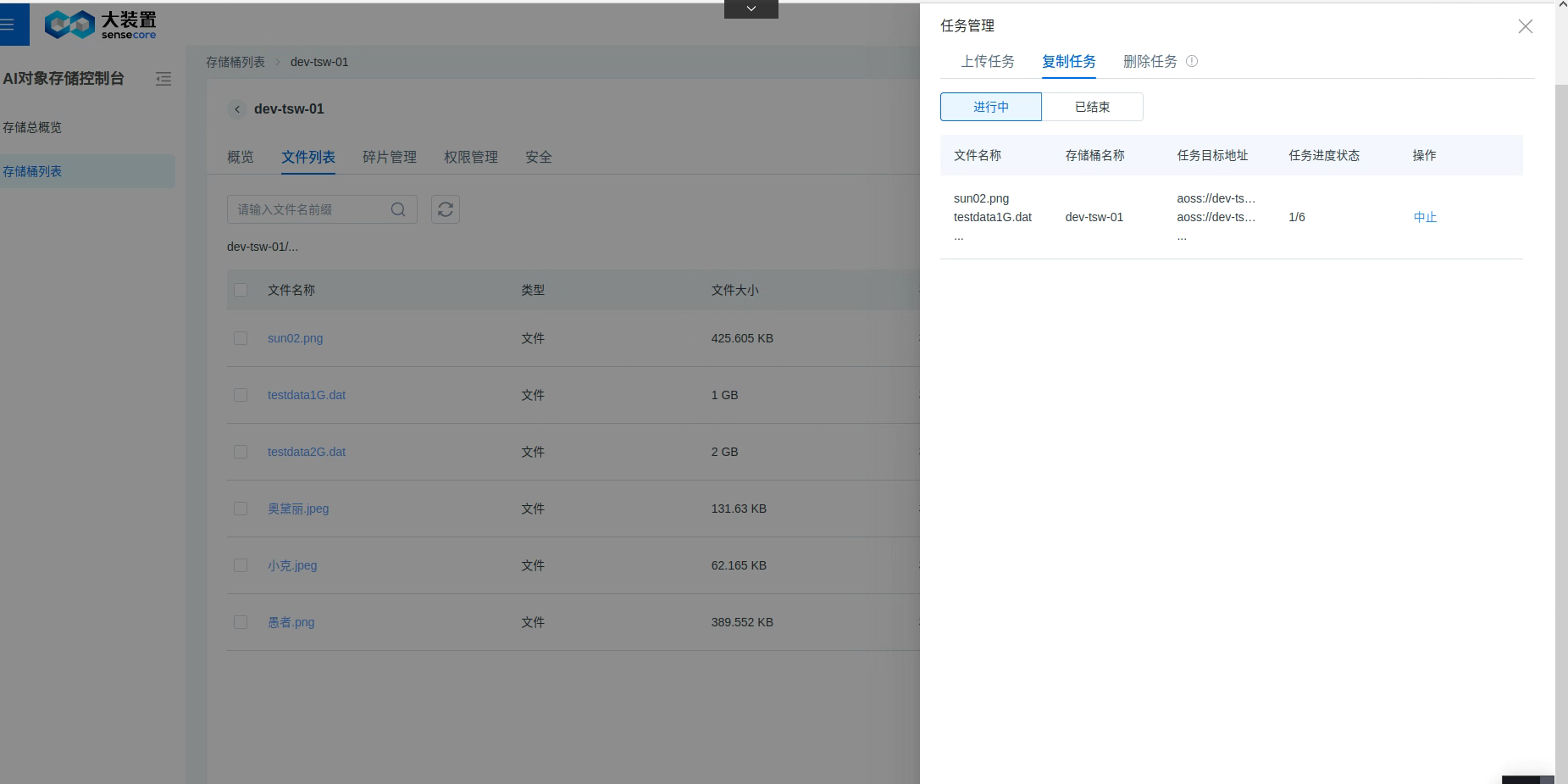
复制任务管理
删除任务管理
5.禁止用户创建桶权限管理
支持租户管理员禁止租户内的用户创建桶,禁止权限配置后,用户没有创建桶的权限
1.在控制台右上方【用户】下拉按钮选择【授权管理】并点击,进入授权页,点击右上角【添加授权】

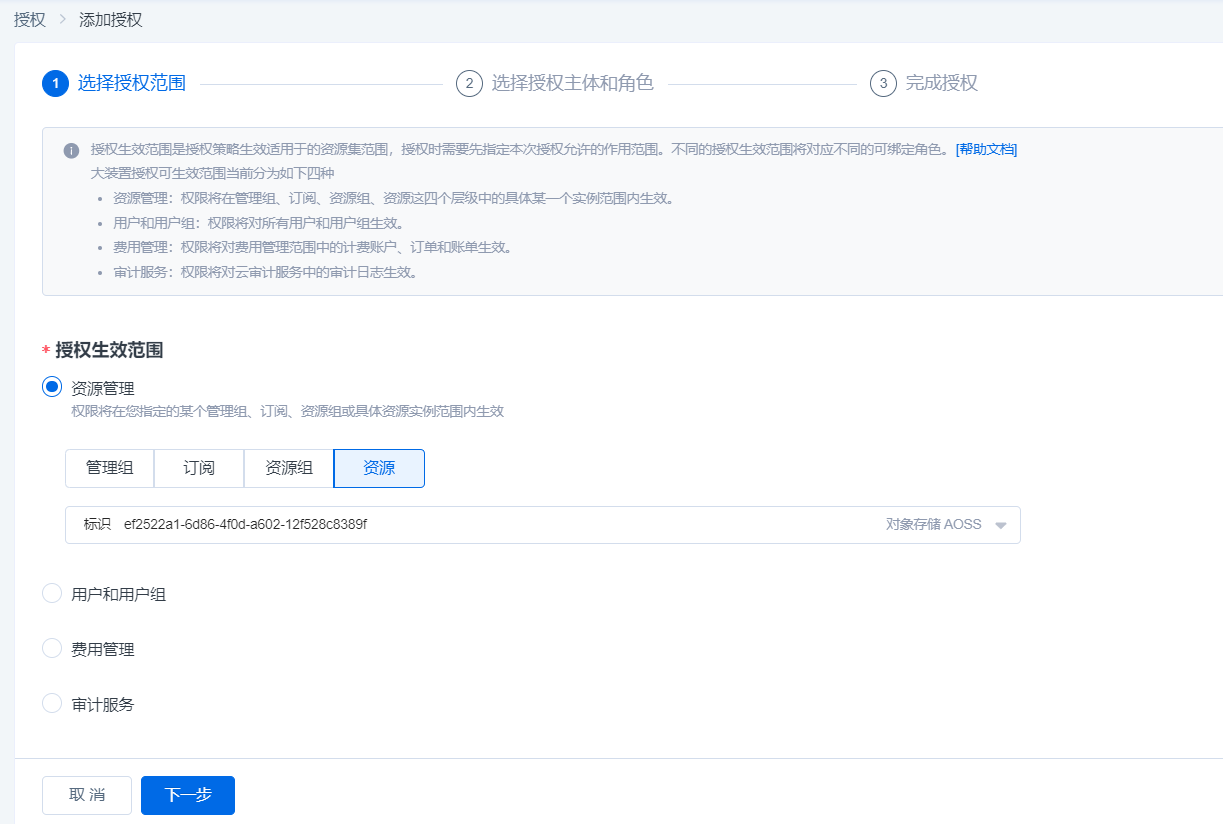
2.进入添加授权页,点击授权生效范围-资源管理-资源,选择创建的对象存储资源包,点击下一步
3.选择要授权的用户,并勾选禁止创建桶角色,点击确认授权后生效
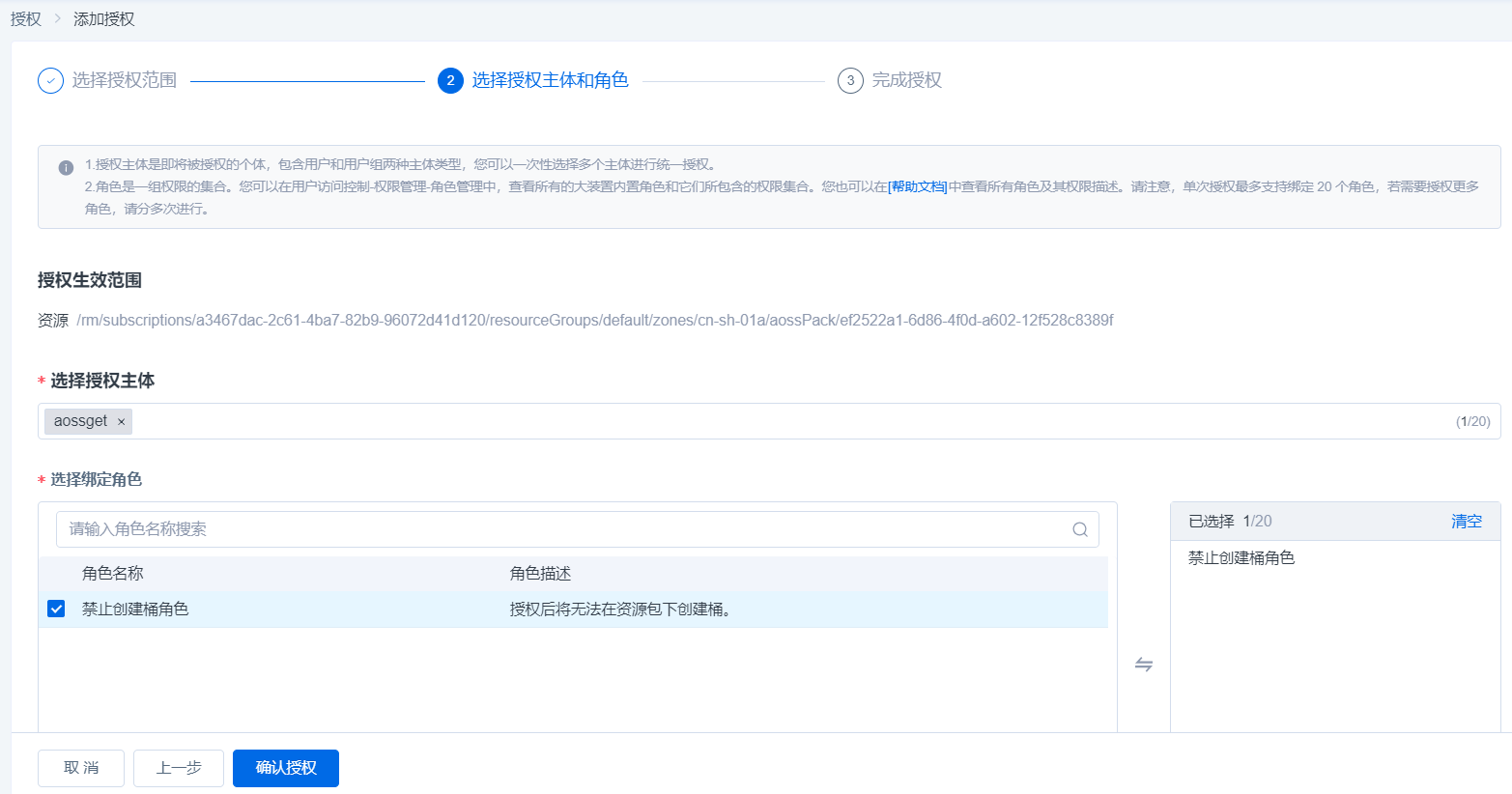
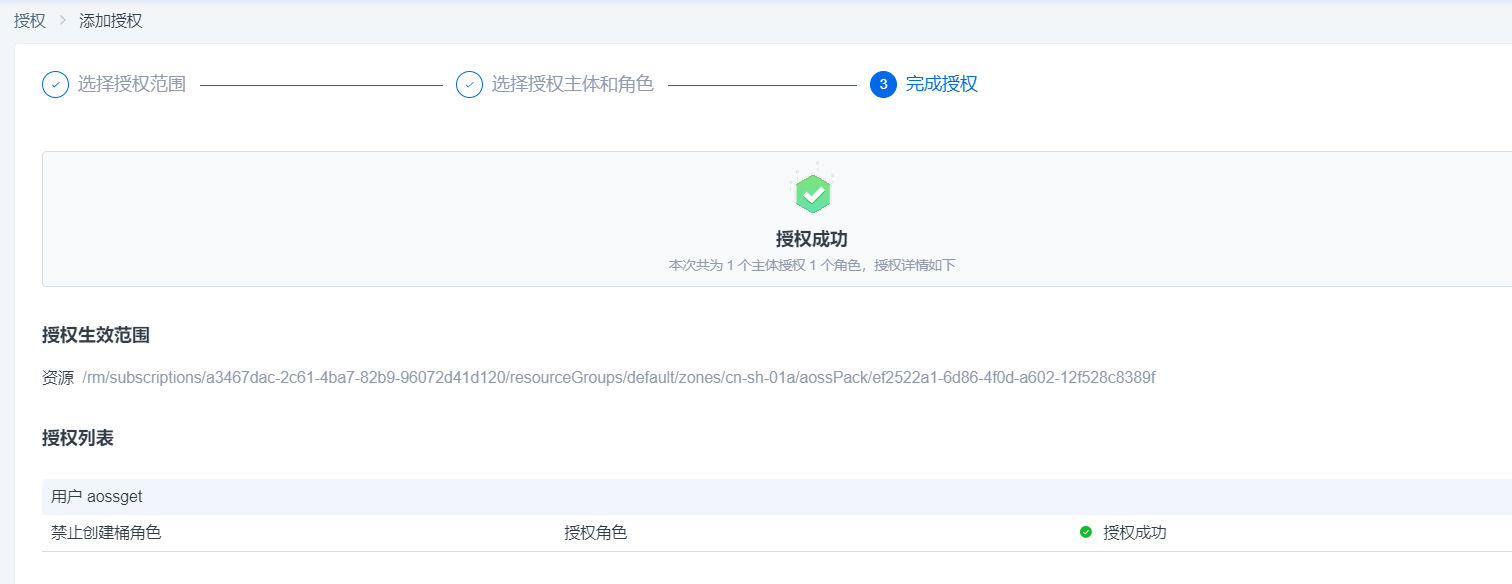
4.授权完成后,可以在用户-授权管理页进行权限管理(查看授权信息和进行授权内容移除)

6.桶加速功能
桶加速功能,短期开通方式,需要研发侧为需求用户开通桶加速功能进行使用。对接人:wangluwen@sensetime.com
或者:前端交付人员可以通过:需求+工单+sre操作的方式进行
7.存储桶数据删除工具使用方法
删除工具脚本aoss_delete_objects.py内容:
#!/bin/python3
import argparse
import boto3
import os
import sys
from botocore.exceptions import ClientError
"""
EXAMPLES:
python3 ./aoss_delete_objects.py testuser testuser http://127.0.0.1 testbucket5 "" 0.5 --dry-run
"""
def delete_files(*file_paths):
for file_path in file_paths:
if os.path.isfile(file_path):
try:
os.remove(file_path)
print(f"文件已删除: {file_path}")
except OSError as e:
print(f"删除文件失败 {file_path} : {e}")
def get_s3_client(access_key, secret_key, endpoint_url):
config = boto3.session.Config(
connect_timeout=600,
read_timeout=600,
retries={'max_attempts': 5})
return boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=endpoint_url, config=config)
def list_objects_v1(s3, bucket_name, prefix, marker=None, max_keys=1000):
try:
if marker:
response = s3.list_objects(Bucket=bucket_name, Prefix=prefix, Marker=marker, MaxKeys=max_keys)
else:
response = s3.list_objects(Bucket=bucket_name, Prefix=prefix, MaxKeys=max_keys)
except ClientError as e:
print(f"Fail to list_objects(): {e.response['Error']['Code']}", file=sys.stderr)
exit(1)
objects = []
for obj in response.get('Contents', []):
object_info = {'Key': obj['Key'], 'Size': obj['Size']}
objects.append(object_info)
return objects, response.get('IsTruncated', False), response.get('NextMarker', None)
def append_objects_to_file(objects, file_path):
with open(file_path, 'a', newline='') as file:
for obj in objects:
file.write('{} {}\n'.format(obj['Key'], obj['Size']))
def load_objects_from_file_in_chunks(file_path, marker, chunk_size=1000):
if not os.path.isfile(file_path):
print("No objects to delete")
exit(2)
with open(file_path, 'r', encoding='utf-8') as file:
objects = []
for line in file:
row = line.rsplit(' ', maxsplit=1)
if not marker or row[0] > marker:
objects.append({'Key': row[0], 'Size': int(row[1])})
if len(objects) == chunk_size:
yield objects
objects = []
if objects:
yield objects
def load_marker_from_file(file_path):
if not os.path.exists(file_path):
return None
if os.path.getsize(file_path) == 0:
return None
with open(file_path, 'rb') as file:
file.seek(-2, os.SEEK_END)
while file.tell() > 0 and file.read(1) != b'\n':
file.seek(-2, os.SEEK_CUR)
last_line = file.readline().decode().strip()
last_key = last_line.rsplit(' ', maxsplit=1)[0]
return last_key
def maximum_size_selection(objects, delete_ratio):
objects.sort(key=lambda x: x['Size'], reverse=True)
delete_count = int(len(objects) * delete_ratio)
return objects[:delete_count], objects[delete_count:]
def delete_objects(s3, bucket_name, objects):
response = None
delete_list = [{'Key': obj['Key']} for obj in objects]
try:
response = s3.delete_objects(
Bucket=bucket_name,
Delete={
'Objects': delete_list,
'Quiet': False
},
)
except ClientError as e:
print(f"Fail to delete objects: {e.response['Error']['Code']}", file=sys.stderr)
exit(1)
if response and 'Errors' in response:
for error in response['Errors']:
print(f"Key: {error['Key']}, Code: {error['Code']}, Message: {error['Message']}", file=sys.stderr)
def main(s3_client, bucket_name, prefix, delete_ratio, marker, resume, dry_run):
file_path = 'bucket_objects.aoss'
delete_log_path = 'deleted_objects.aoss'
retain_log_path = 'retained_objects.aoss'
# 清理环境
if not resume:
delete_files(file_path, delete_log_path, retain_log_path)
delete_marker = load_marker_from_file(delete_log_path)
is_delete_started = (delete_marker is not None) and resume
if is_delete_started:
print(f"Continue to delete from {delete_marker}")
# 1. 获取对象列表
if not is_delete_started:
print("start to list objects")
next_marker = load_marker_from_file(file_path)
if marker is None:
pass
elif next_marker is None:
next_marker = marker
elif marker > next_marker:
next_marker = marker
if next_marker:
print("Continue to list from marker ", next_marker)
while True:
new_objects, is_truncated, next_marker = list_objects_v1(s3_client, bucket_name, prefix, next_marker)
if len(new_objects) > 0:
append_objects_to_file(new_objects, file_path)
if not is_truncated:
break
# 2. 删除对象
print("start to delete objects")
for objects in load_objects_from_file_in_chunks(file_path, delete_marker, 1000):
if len(objects) < 1:
break
to_delete, to_retain = maximum_size_selection(objects, delete_ratio)
to_delete.sort(key=lambda x: x['Key']) # sort to ensure delete_marker ascending
if not dry_run:
delete_objects(s3_client, bucket_name, to_delete)
append_objects_to_file(to_delete, delete_log_path)
append_objects_to_file(to_retain, retain_log_path)
# 3. 提示用户不要 ls 或者删除桶
print("Warning: 如果是整桶删除,删除对象后,请注意不要尝试 ls 或者删除该桶,否则墓碑数据过多可能会引起集群震荡")
def restricted_float(x):
x = float(x)
if x < 0.01 or x > 0.99:
raise argparse.ArgumentTypeError(f"{x} not in range [0.01, 0.99]")
return x
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Delete a proportion of objects from an S3 bucket.')
parser.add_argument('access_key', help='access key')
parser.add_argument('secret_key', help='secret key')
parser.add_argument('endpoint_url', help='AOSS endpoint url, https://aoss.cn-sh-01.sensecoreapi-oss.cn etc.')
parser.add_argument('bucket_name', help='The name of the S3 bucket.')
parser.add_argument('prefix', help='The prefix path in the S3 bucket.')
parser.add_argument('delete_ratio', type=restricted_float, help='The ratio of objects to delete [0.01, 0.99].')
parser.add_argument('--marker', help='Start delete from specified marker.')
parser.add_argument('--resume', action="store_true", help="continue last job")
parser.add_argument('--dry-run', action='store_true', help="dry run, list bucket only, not actually delete objects")
args = parser.parse_args()
s3_client = get_s3_client(args.access_key, args.secret_key, args.endpoint_url)
main(s3_client, args.bucket_name, args.prefix, args.delete_ratio, args.marker, args.resume, args.dry_run)
工作原理
把需要删除的文件 list 出来并写入本地文件 bucket_objects.aoss
每次从 bucket_objects.aoss 中读取 1000 个 key,按照 size 从大到小选取指定比例的对象进行删除
把被选中的对象写入本地文件 deleted_objects.aoss 中
没有被选中的对象,会写入到本地文件 retained_objects.aoss 中
使用建议
- 单桶不超过 200万对象的 bucket,可以使用 awscli 或者 ads 直接删除
- 单桶对象数在 200万 - 1000万之间,需要跟 sre 确认后,判断能否直接删
- 单桶超过 1000 万对象的 bucket,建议使用本工具进行删除
使用方法
- 使用前,需要先安装 boto3
pip3 install boto3
或者
yum install python3-boto3.noarch
- --help 可以查看简单的帮助信息
# python3 aoss_delete_objects.py --help
usage: aoss_delete_objects.py [-h] [--marker MARKER] [--resume] [--dry-run]
access_key secret_key endpoint_url bucket_name
prefix delete_ratio
Delete a proportion of objects from an S3 bucket.
positional arguments:
access_key access key
secret_key secret key
endpoint_url AOSS endpoint url, https://aoss.cn-sh-01.sensecoreapi-
oss.cn etc.
bucket_name The name of the S3 bucket.
prefix The prefix path in the S3 bucket.
delete_ratio The ratio of objects to delete (0.0 to 1.0).
optional arguments:
-h, --help show this help message and exit
--marker MARKER Start delete from specified marker.
--resume continue last job
--dry-run dry run, list bucket only, not actually delete objects
- 参数解析
access_key: 用户的 access key
secret_key: 用户的 secret key
endpoint_url: 对象存储的访问地址,比如上海 01a 是 https://aoss.cn-sh-01.sensecoreapi-oss.cn
bucket_name: 桶名
prefix: 需要删除的对象前缀或者目录名。比如要删除目录 dir1,则传入 dir1/,指定一级目录时,注意前缀无须带上("/")。从根目录开始删除时,prefix 传入空字符串 ""
delete_ratio: 删除的比例,取值范围 [0.01, 0.99]。为了避免批量删除产生大量连续的墓碑,导致 bucket ls 变慢,因此现阶段不建议客户做全量删除,删除比例取值范围限制为 1% - 99%
可选参数:
--marker 指定开始 list-objects 的位置。如果 prefix 无法满足需求,可以配合 marker 使用
--resume list-objects 或者 delete-objects 阶段任务中断时,可以使用 resume 参数继续任务
--dry-run 只 list-objects 并模拟删除,并不会真正删除对象
- 示例整桶删除 99%
python3 ./aoss_delete_objects.py testuser testuser https://aoss.cn-sh-01.sensecoreapi-oss.cn testbucket "" 0.99
- 如果在 list-objects 或者 delete-objects 阶段异常退出或者主动中断,可以通过参数 --resume 继续执行
python3 ./s3_delete_objects.py testuser testuser https://aoss.cn-sh-01.sensecoreapi-oss.cn testbucket "" 0.99
注意事项
- 使用 --resume 的时候,marker 和桶名需要跟上一次保持一致
- 如果 bucket 中对象比较多,建议分多次分目录删除,单次删除的对象数控制在 2 亿内
查看当前删除进度
1.查看需要删除的对象数
ratio=0.95
echo "$(cat bucket_objects.aoss | wc -l) * ${ratio}" | bc
2.查看已删除的对象数
wc -l deleted_objects.aoss
8.boto3 sdk常用用例说明
本文档提供一些基础用例帮助客户快速了解boto3的使用方法,更详细使用说明参见官方文档 https://boto3.amazonaws.com/v1/documentation/api/1.23.0/index.html
使用方法
- 使用前,需要先安装 boto3
pip3 install boto3
- 创建桶
import logging
import boto3
from botocore.exceptions import ClientError
def create_bucket(bucket_name, region=None):
try:
if region is None:
s3_client = boto3.client('s3', endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",aws_access_key_id="xxx",aws_secret_access_key="xxx")
s3_client.create_bucket(Bucket=bucket_name)
except ClientError as e:
logging.error(e)
return False
return True
create_bucket("test-boto1")
- 桶列表展示
import boto3
s3_client = boto3.client('s3', endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",aws_access_key_id="xxx",aws_secret_access_key="xxx")
response = s3_client.list_buckets()
# Output the bucket names
print('Existing buckets:')
for bucket in response['Buckets']:
print(f' {bucket["Name"]}')
- 指定桶创建路径
import boto3
s3_client = boto3.client('s3', endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",aws_access_key_id="xxx",aws_secret_access_key="xxx")
s3_client.put_object(
Bucket='bucket-name',
Key='test-folder/'
)
- 上传文件到指定路径
import boto3
s3_client = boto3.client('s3', endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",
aws_access_key_id="xxx",
aws_secret_access_key="xxx")
with open("test.py", "rb") as f:
s3_client.upload_fileobj(f, "osschenxi", "test-folder/test.py")
- 下载object
import boto3
s3_client = boto3.client('s3', endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",
aws_access_key_id="xxx",
aws_secret_access_key="xxx")
with open('download.py', 'wb') as f:
s3_client.download_fileobj('osschenxi', 'test-folder/test.py', f)
- 实现指定目录批量文件下载
import boto3
import os
def download_s3_folder(bucket_name, s3_folder, local_dir):
s3 = boto3.client('s3',endpoint_url="http://aoss.cn-sh-01.sensecoreapi-oss.cn",aws_access_key_id="xxx",aws_secret_access_key="xxxx")
# 确保本地目录存在
if not os.path.exists(local_dir):
os.makedirs(local_dir)
objects = []
next_marker = None
while True:
if next_marker:
response = s3.list_objects(Bucket=bucket_name, Prefix=s3_folder,
Marker=next_marker)
else:
response = s3.list_objects(Bucket=bucket_name, Prefix=s3_folder)
if 'Contents' in response:
objects.extend(response['Contents'])
# 检查是否还有更多对象
if response.get('IsTruncated'): # 检查是否有更多的对象
next_marker = response.get('NextMarker')
else:
break
for obj in objects:
# 获取对象的 Key
s3_key = obj['Key']
# 去掉末尾为 /,size为0的特殊对象
if s3_key.endswith('/') and obj['Size'] == 0:
continue
# 生成本地文件路径
local_file_path = os.path.join(local_dir, os.path.relpath(s3_key, s3_folder))
# 确保本地目录存在
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
# 下载文件
s3.download_file(bucket_name, s3_key, local_file_path)
print(f'Downloaded {s3_key} to {local_file_path}')
# 使用示例
download_s3_folder('osschenxi', 'CTS/', '/tmp/test2/')
AOSS支持API列表
兼容S3接口,提供RESTful API,支持通过HTTP/HTTPS请求调用,实现创建、修改、删除桶,上传、下载、删除对象等操作
关于Service操作
| API | 描述 |
|---|---|
| ListBuckets | 返回请求者拥有的所有存储空间(Bucket) |
关于Bucket操作
| 分类 | API | 描述 |
|---|---|---|
| 基础操作 | PutBucket | 创建Bucket |
| DeleteBucket | 删除Bucket | |
| GetBucket | 列出Bucket中所有文件(Object)的信息 | |
| 权限控制(ACL) | PutBucketAcl | 设置Bucket访问权限 |
| GetBucketAcl | 获取Bucket访问权限 | |
| 生命周期(Lifecycle)(未实现) | PutBucketLifecycle | 设置Bucket中Object的生命周期规则 |
| GetBucketLifecycle | 获取Bucket中Object的生命周期规则 | |
| DeleteBucketLifecycle | 删除Bucket中Object的生命周期规则 | |
| 授权策略(Policy) | PutBucketPolicy | 设置Bucket Policy |
| GetBucketPolicy | 获取Bucket Policy | |
| DeleteBucketPolicy | 删除Bucket Policy | |
| 标签(Tags)(未实现) | PutBucketTags | 添加或修改Bucket标签 |
| GetBucketTags | 查看Bucket标签信息 | |
| DeleteBucketTags | 删除Bucket标签 | |
| 加密(Encryption) | PutBucketEncryption | 配置Bucket的加密规则 |
| GetBucketEncryption | 获取Bucket的加密规则 | |
| DeleteBucketEncryption | 删除Bucket的加密规则 |
关于对象操作
| 分类 | API | 描述 |
|---|---|---|
| 基础操作 | PutObject | 上传Object |
| GetObject | 获取Object | |
| DeleteObject | 删除单个Object | |
| DeleteMultipleObjects | 删除多个Object | |
| HeadObject | 只返回某个Object的meta信息,不返回文件内容 | |
| 分片上传(MultipartUpload) | InitiateMultipartUpload | 初始化一个Multipart Upload事件 |
| UploadPart | 根据指定的Object名和uploadId来分块(Part)上传数据 | |
| CompleteMultipartUpload | 在将所有数据Part都上传完成后,您必须调用CompleteMultipartUpload接口来完成整个文件的分片上传 | |
| AbortMultipartUpload | 取消Multipart Upload事件并删除对应的Part数据 | |
| ListMultipartUploads | 列举所有执行中的Multipart Upload事件,即已经初始化但还未完成(Complete)或者还未中止(Abort)的Multipart Upload事件 | |
| ListParts | 列举指定uploadId所属的所有已经上传成功Part | |
| 权限控制(ACL) | PutObjectACL | 修改Object的访问权限 |
| GetObjectACL | 查看Object的访问权限 | |
| 标签(Tags) | PutObjectTagging | 设置或更新对象标签 |
| GetObjectTagging | 获取对象标签信息 | |
| DeleteObjectTagging | 删除指定的对象标签 |
对象存储域名信息
标准对象: 01a域名: 外网访问(Endpoint):aoss.cn-sh-01.sensecoreapi-oss.cn
内网访问(Endpoint):aoss-internal.cn-sh-01.sensecoreapi-oss.cn
存储桶域名信息(外网访问):< bucket name>.aoss.cn-sh-01.sensecoreapi-oss.cn
存储桶域名信息(内网访问):< bucket name>.aoss-internal.cn-sh-01.sensecoreapi-oss.cn
01b域名:
外网访问(Endpoint):aoss.cn-sh-01b.sensecoreapi-oss.cn
内网访问(Endpoint):aoss-internal.cn-sh-01b.sensecoreapi-oss.cn
存储桶域名信息(外网访问):< bucket name>.aoss.cn-sh-01b.sensecoreapi-oss.cn
存储桶域名信息(内网访问):< bucket name>.aoss-internal.cn-sh-01b.sensecoreapi-oss.cn
归档对象:
外网访问(Endpoint):archive-aoss.cn-sh-01.sensecoreapi-oss.cn
内网访问(Endpoint):archive-aoss-internal.cn-sh-01.sensecoreapi-oss.cn
存储桶域名信息(外网访问):< bucket name>.archive-aoss.cn-sh-01.sensecoreapi-oss.cn
存储桶域名信息(内网访问):< bucket name>.archive-aoss-internal.cn-sh-01.sensecoreapi-oss.cn
注:
1.SenseCore的计算产品访问对象存储时推荐使用内网域名访问。
2.内外网支持http(s)访问。
推荐使用工具
AOSS SDK
推荐在训练场景中通过SDK使用对象存储,通过SDK可以便捷地从对象存储中读写数据,快速完成常见操作,如创建存储空间(Bucket)、上传文件(Object)、下载文件等。
兼容性:
- 操作系统:
- MAC(64位)
- windows(64位)
- Linux,包含CentOS、Ubuntu、Rocky等64位主要发行版本
- Python版本:
- 支持python3.9以下的python版本。
- 不支持python2
Boto3 SDK [推荐使用]
使用示例请参考帮助中心内容: 8.boto3 sdk常用用例说明
Python SDK 下载
Python SDK 使用手册
AWS CLI工具
兼容性:
- 操作系统:
- MAC(64位)
- windows(64位)
- Linux,包含CentOS、Ubuntu、Rocky等64位主要发行版本,例如:centos 7.X ubuntu 16\18\20 rocky8.6
- Python版本:
- awscli 可在python2、python3下安装
- awscli 1.16 不可在python3.9使用
AWS CLI软件下载
AWS CLI工具安装手册
数据传输工具
2.或者使用ads-cli(大装置开发),使用方法请到:控制台-文档-存储数据同步工具ADS 查看帮助文档。
Linux:https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/ads-cli/release/v1.9.0/ads-cli
Windows:https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/ads-cli/release/v1.9.0/ads-cli.exe
MacOS:https://quark.aoss.cn-sh-01.sensecoreapi-oss.cn/ads-cli/release/v1.9.0/ads-cli.macos
常见问题
什么是对象存储AOSS?
对象存储AOSS是一种分布式无树形结构存储系统,用户可以使用AOSS方便快捷地对海量图片、音视频数据进行处理和访问。
什么是【桶】【对象】?
【桶】对象存储系统内的一个虚拟的存储空间,桶内只有一层目录结构。 【对象】对象是对象存储桶内基本的存储单元,由元数据(描述对象数据的数据)和对象数据构成。
桶的数量是否有上限?
1.0版本桶的数量为2亿限制,2.0版本桶的数量没有上限。如:推荐使用的01B可用区对象存储为2.0版本,桶的数据量不限制。
标准存储和归档存储有什么区别?
二者为不同类型的存储,适用场景不同。标准存储适用于AI数据搜集、标注、大数据分析等业务场景;归档存储适用于数据长期保存的业务场景。