数据管理平台 AIDMP
产品概述
面向海量训练数据,提供开放、易用、高效的 数据管理平台(Git for AI Data),满足 AI 开发者数据管理和企业资产管理的需求。
- 百亿级数据管理:提供管理百亿级非结构化数据的平台,助力 AI 大模型的训练推理;
- 秒级检索挖掘:提供大规模非结构化数据的检索,达到秒级返回,可快速挖掘出新样本;
- 保障数据安全:提供 AI 场景下数据安全的整套解决方案,保障 AI 数据的隐私合规;
- 优质公开数据集:提供高质量业内公开数据集,使用 PythonSDK 工具快速加载数据。
产品优势
基于商汤大规模 AI 数据管理的多年沉淀,提供符合 AI 开发者习惯、满足企业资产管理和合规诉求的 数据管理平台。
- Git for AI Data:覆盖数据产生、数据获取、检索分析、可视化、数据使用、合规审核等各个环节,提升数据管理的效率和便利性,严格的访问控制,确保数据安全;
- 安全合规 :数据管理的每个环节,都有着安全措施,权限控制、数字水印、数据脱敏、合规授权等,为数据的安全保驾护航;
- 即见即用 :数据集即见即用,无需下载到本地,可通过一行脚本直接加载数据集,搭配 AI 缓存服务加速,助力高速 AI 训练;
- AI for AI:利用 AI 大模型的能力,使用自然语言检索非结构化数据,达到秒级返回,挖掘有价值可利用的业务数据。
产品功能
打造 Git for AI Data,提供高效的 AI 数据工具,可快速检索挖掘数据,在界面上做数据的可视化。
- Git for AI Data :打造 Git for AI Data,从数据导入、数据处理到数据使用的全生命周期,提供数据迭代的版本管理、分支协同、数据集共享功能;
- AI 数据工具:通过 SDK 工具可单行脚本加载数据集助力模型高速训练,通过 CLI 工具可实现版本、分支管理掌控数据迭代;
- 检索挖掘:提供基于大模型的自然语言检索图片功能,基于元数据、标注数据、预测数据和自定义标签,可灵活检索样本数据;
- 数据可视化:在 Web 端可以便捷地可视化多模态数据和标注数据,快速查看数据集概览,进行 Web 端的文件操作。
应用场景
提供大规模非结构化 AI 数据的管理能力,加快模型迭代和数据迭代,支撑 AI 应用快速落地。
1、企业级数据管理:管理企业内的大规模非结构化数据,适合多人协作共享,基于版本管理,快速迭代数据,不断提升数据质量;
2、数据集获取使用:检索获取各种场景的企业内数据集、公开数据集,通过数据概览、文件、可视化等方式了解数据集,使用 SDK 工具使数据集可以开箱即用;
3、大模型数据集:大模型训练应用中相应的数据管理,提供公开数据集,如 LAION5B 、LAION-400M、CCNews 等,对业务微调数据集,做数据的全生命周期管理;
4、样本检索挖掘:结合样本属性、标注、预测、自定义标签等,检索分析数据,基于大模型的自然语言检索能力,筛选质量更高、更有针对性的训练数据;
5、数据安全合规:保障企业内数据的隐私安全,严格的访问控制、数据授权、数字水印、数据脱敏等措施,确保数据不泄漏,保证数据的合规安全。
角色和权限
| 角色 | 主要职责 | 权限范围 |
|---|---|---|
| 数据空间创建者 | 可以购买创建数据空间 | 购买创建数据空间 |
| 数据空间管理员 | 管理相应数据空间的所有数据集、用户 | 数据空间的数据集所有权限、数据空间管理员增加或删除 |
| 数据空间用户 | 进入相应数据空间的必要条件 | 进入相应数据空间,具备所有数据集的使用者功能权限 |
| 数据集管理者 | 管理某个数据集 | 数据集的增、删、改、查和配置,以及成员增加或删除 |
| 数据集使用者 | 使用某个数据集 | 数据集的使用 |
| 数据集访客 | 预览某个数据集 | 数据集的预览 |
基本概念
- 数据空间:租户在数据管理平台内所有功能、业务对象和数据的一个最小集合。一个租户在SenseCore内可以有多个数据空间。
- 数据包:数据空间的计费单位,一个数据包含100万个对象,购买数据包越多,可以管理的文件数越多。
- 数据集:管理数据的基本管理单元,一个数据集内包含了特定用途的、去冗余的文件,可以由多人贡献和操作。
- 分支:数据迭代和开发的基本单元,一般包含多个版本的,分支实现数据集的多人操作,互不影响。
- 版本:记录和管理分支内的文件的变化,一个分支内有多个版本,版本通过增删该文件操作而产生。
计费说明
数据空间的购买,通用SaaS计费方式,支持续订、补订,购买越多单价越便宜,大客户支持议价折扣。
计费项
平台版本基础费用:
使用平台基础费用,正式版本最低3万/月。
数据包个数:
平台可以管理文件的数量,一个数据包为100万个文件数据量。
计费模式
| 规格 | 正式版 |
|---|---|
| 基础价格 | ¥3万/月、¥30万/年 |
| 数据包价格 | 125元/月、1500元/年 |
| 数据集数量限制 | 不限制 |
- 基础费用价格30万元/年、3万元/月,赠送200个数据包;
- 存储计费按照对象存储的计费标准另外计费;
- 数据包正式版价格1500元/年。
快速开通
开通前准备
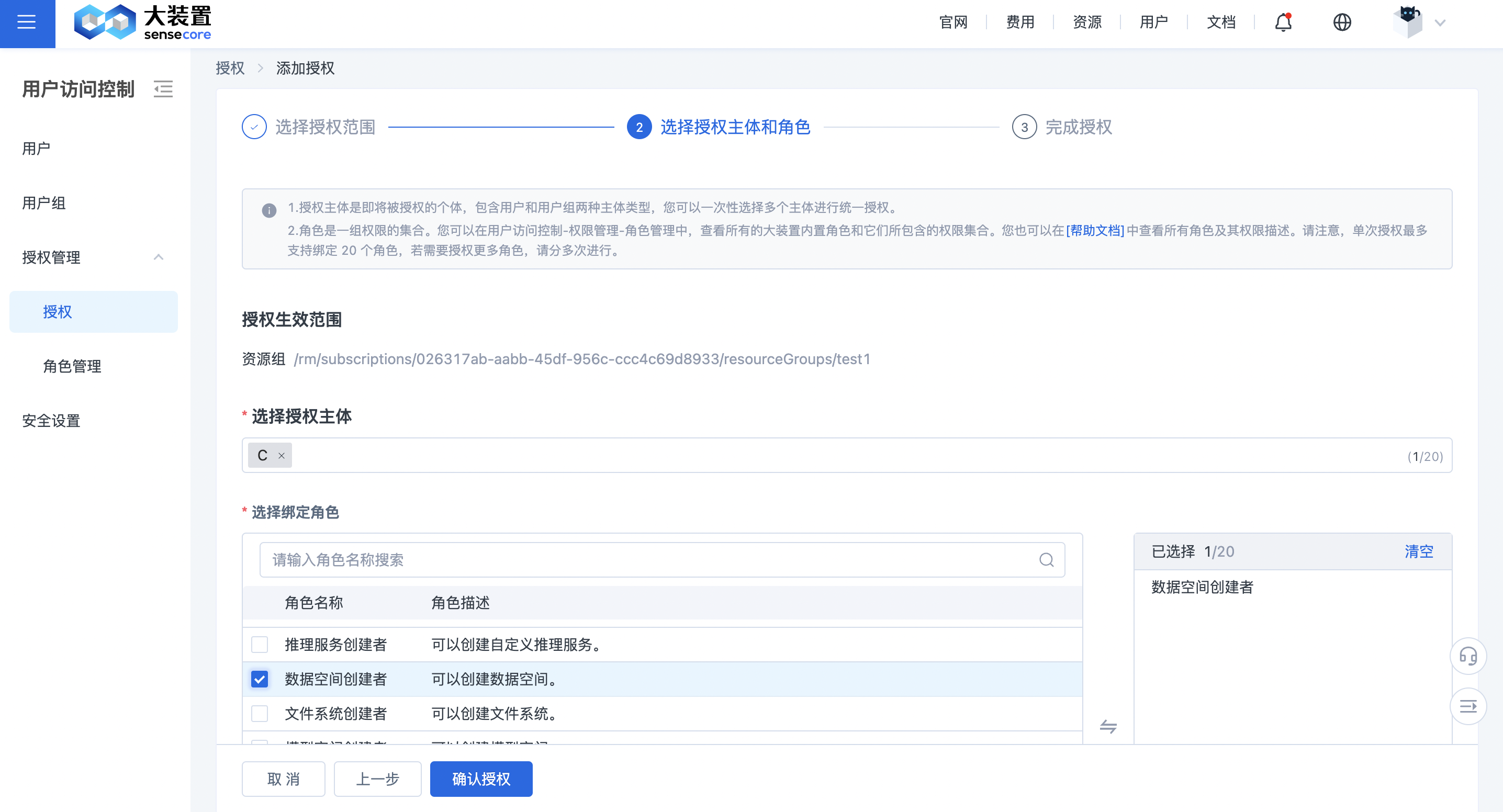
开通前,请确保您具备数据空间创建者权限。
请参考如何为用户授权 步骤,需要租户管理员为您添加数据空间创建者角色。
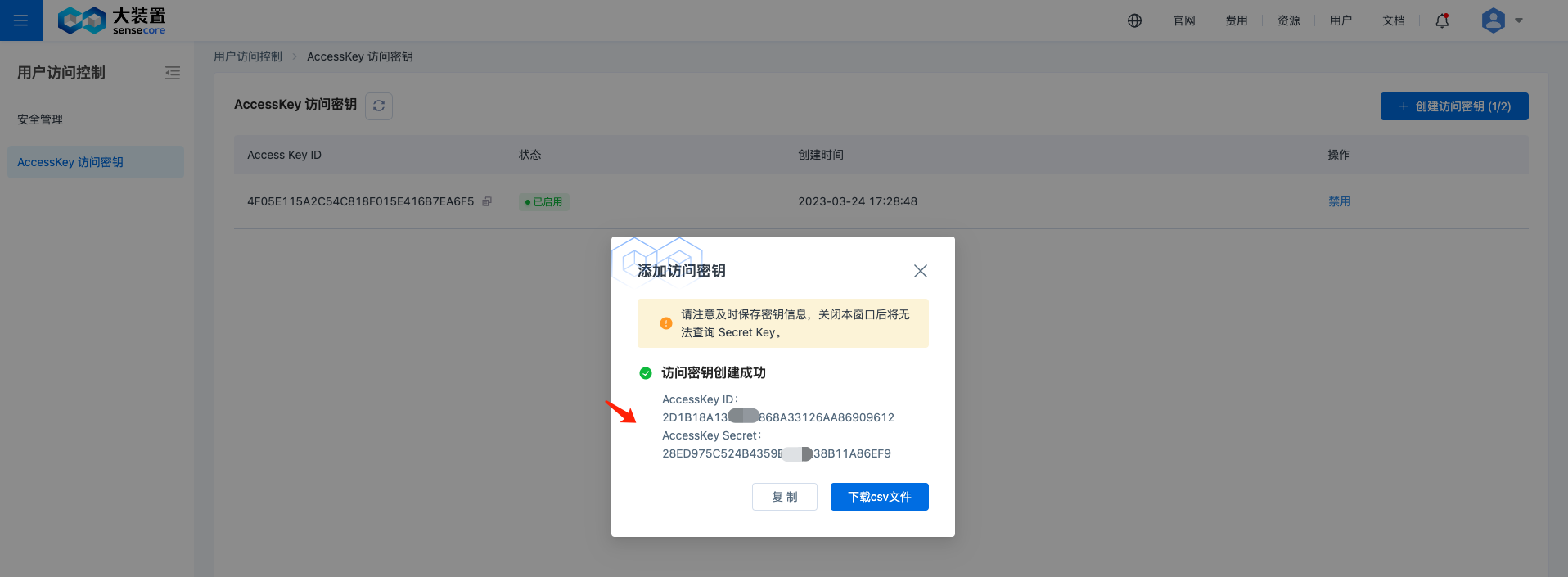
之后前往创建 AccessKey 访问秘钥,请妥善保存您的 AccessKey ID 和 AccessKey Secret,用于后续的使用。
开通数据管理平台
准备就绪后,进入SenseCore控制台首页,点击数据管理平台AIDMP,进下公开数据集页面,可以查看平台上提供的公开数据集。 点击左侧的首页或者数据集或者下拉选择左侧顶部的数据空间,可以点击前往购买 数据管理平台。
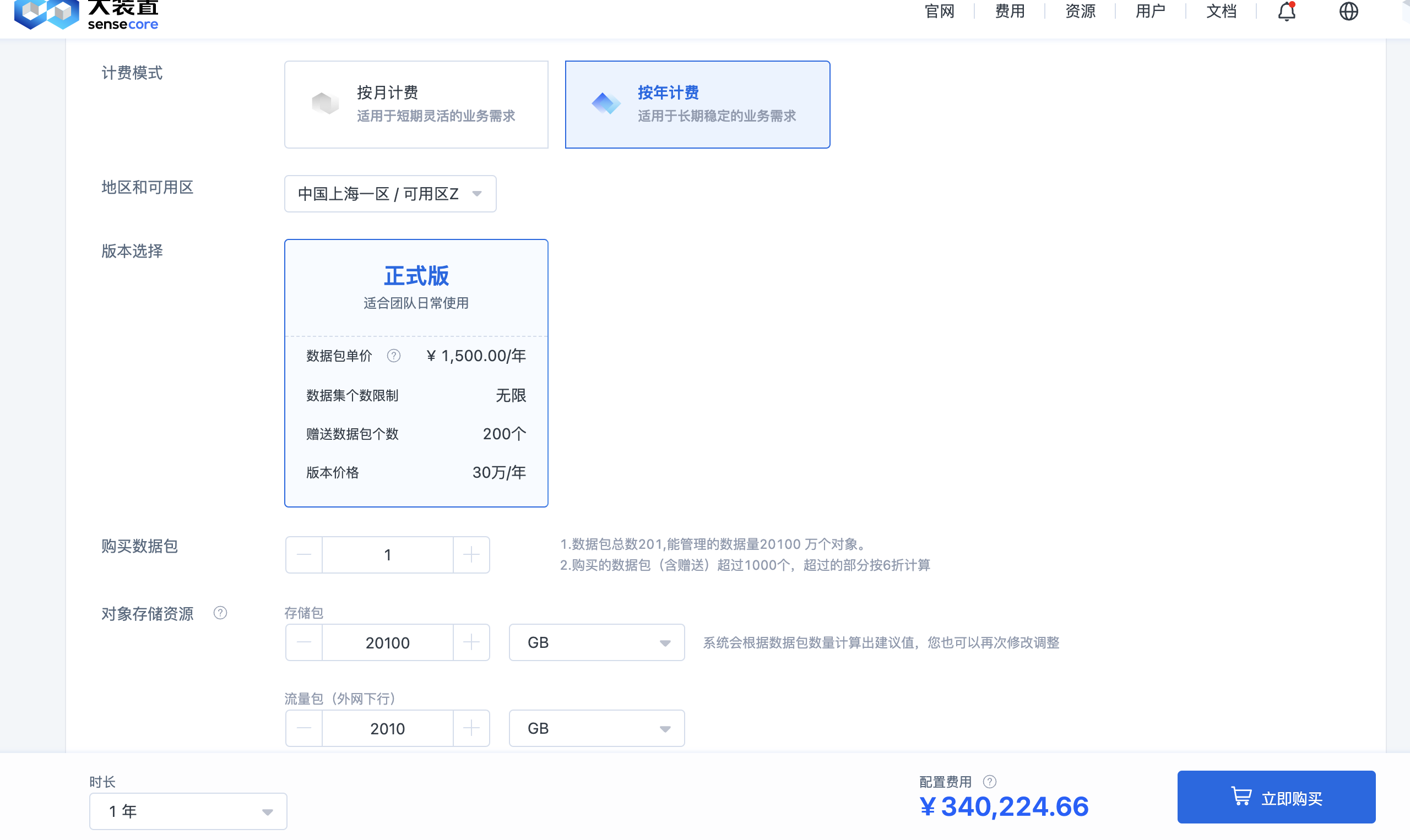
- 在计费模式栏,可以选择按月计费或者按年计费。
- 在购买数据包栏,可以按需购买数据包,正式版赠送200个数据包,其中一个数据包可以管理100万个文件。
- 在对象存储资源栏,可以按需购买对象存储资源,存储包、流量包(外网下行)和请求包,我们根据数据包数量给您推荐了建议值,您也可以再次修改调整。
- 在基本信息栏,可以选择提前创建的订阅和资源组,以及数据空间名称,便于后续资源的管理和查看。
补充其他信息,提交订单,支持成功后,等待创建成功,再次点击数据管理平台 AIDMP,即可进入相应的数据空间。
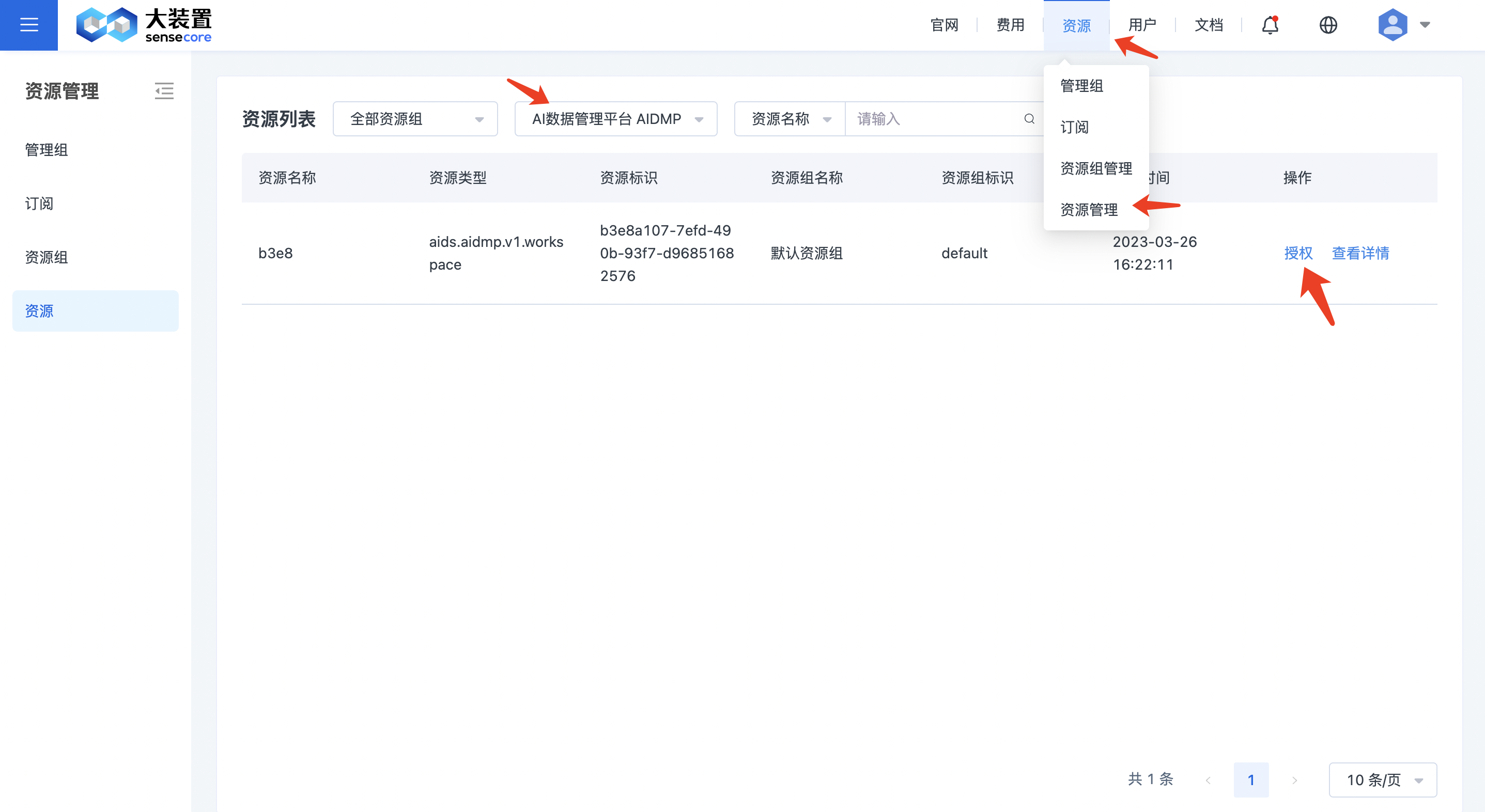
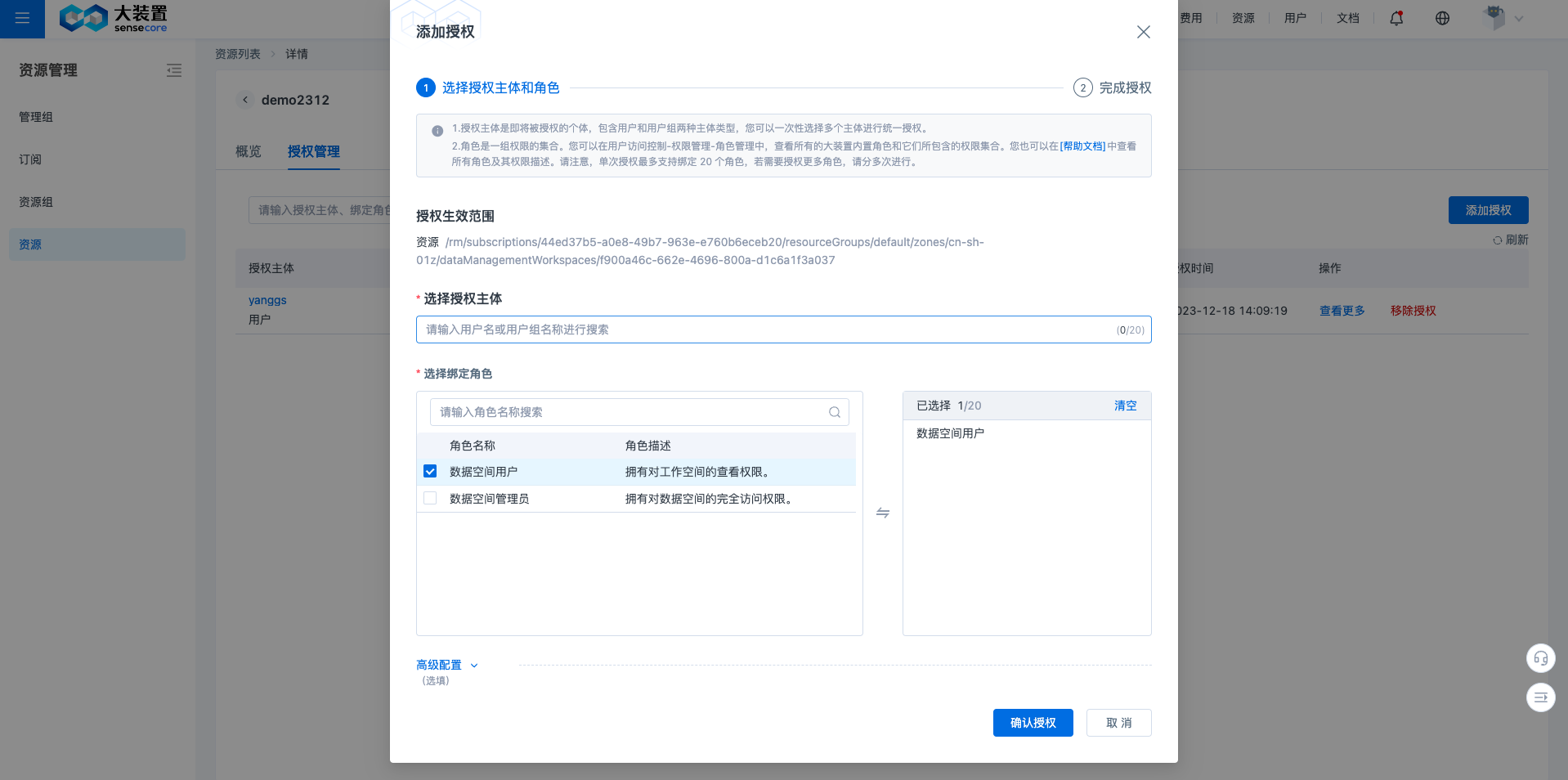
购买后,您将自动成为该数据空间的管理员,拥有数据空间管理员角色,您可以在资源管理界面把其他用户添加为数据空间管理员角色或者是数据空间用户角色。在资源列表,过滤出数据管理平台AIDMP找到对应的资源,点击授权操作。
数据集
数据集创建
数据空间创建成功后,该数据空间的数据空间管理员角色或者是数据空间用户角色,都可以创建数据集。
数据集是管理数据集的基本单位,创建后即可在数据集中添加文件、创建分支版本。
进入数据管理平台,选择相对应的数据空间,在数据集列表页,点击右上角创建数据集,在创建数据集页面,选择数据空间,输入数据集名称、数据集URL标识和数据集的描述,点击确定,即可创建一个新的数据集。
- 数据集名称必须在数据空间内唯一,不能重复。
- URL标识在数据空间内也必须是唯一;URL标识用来生成数据集URL,用于 CLI 和 SDK 的数据集使用。
数据集创建后,即可进入数据集使用向导页面。此向导页面指引如何新建文本文件、上传文件以及使用 CLI 上传文件。
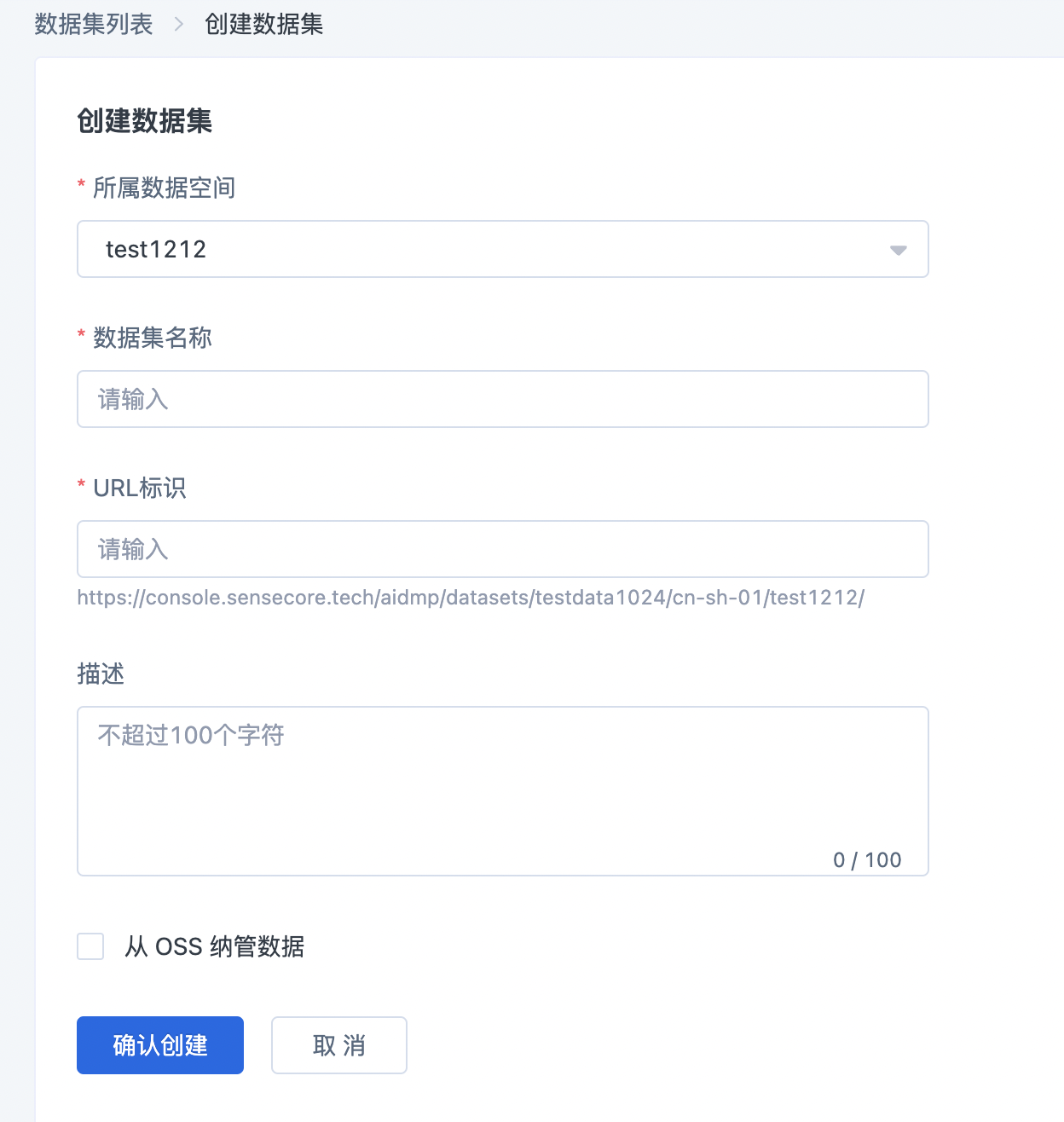
同时,我们可以勾选从 OSS 纳管数据,支持对 OSS 数据进行纳管操作。 纳管的数据做为数据集后,数据集的分支和版本唯一,在此数据集上做的改动,和 OSS 的原始目录同步变动。 原始 OSS 的数据变动后,可以在设置中,选择同步数据,进行数据集的数据同步工作。
文件操作
通过 Web 上传本地文件或者 OSS 文件
可以通过WEB上传本地文件或者 OSS 文件,OSS 来源当前支持 大装置 AOSS、Amazon OSS、百度云 OSS、华为云 OSS、阿里云 OSS。
点击进入文件页面之后,可以选择不同的分支以及不同的文件路径,上传本地文件或者 OSS 文件
点击加号,再点击上传按钮,即可打开导入文件功能。
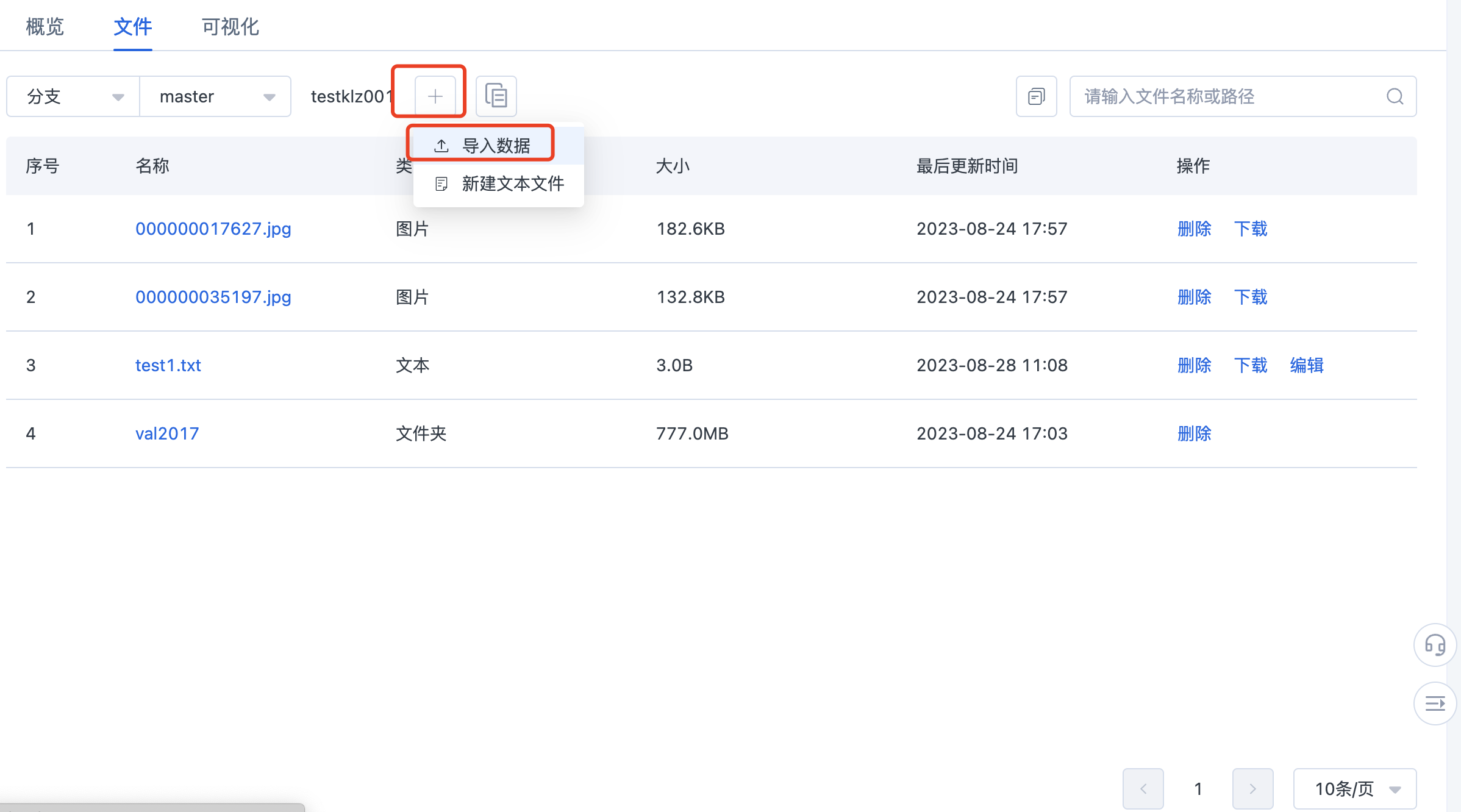
可以选择在当前路径下再创建子路径,可以选择本地上传(支持拖拽文件夹进行上传)或者是从 OSS 导入,可以自行改动编辑提交信息(commit message)。
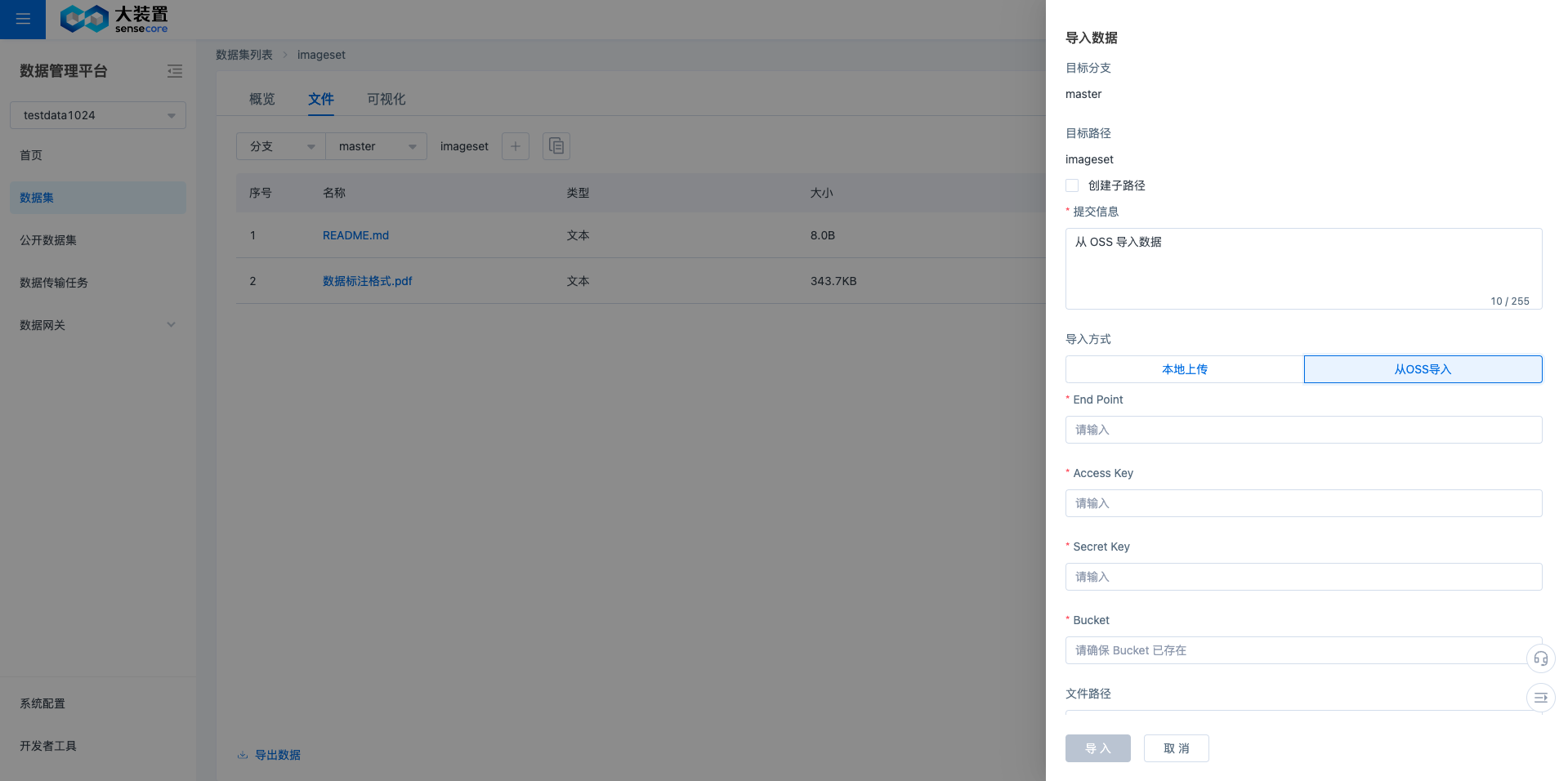
点击导入数据后,可以随时收起,异步查看管理导入任务。
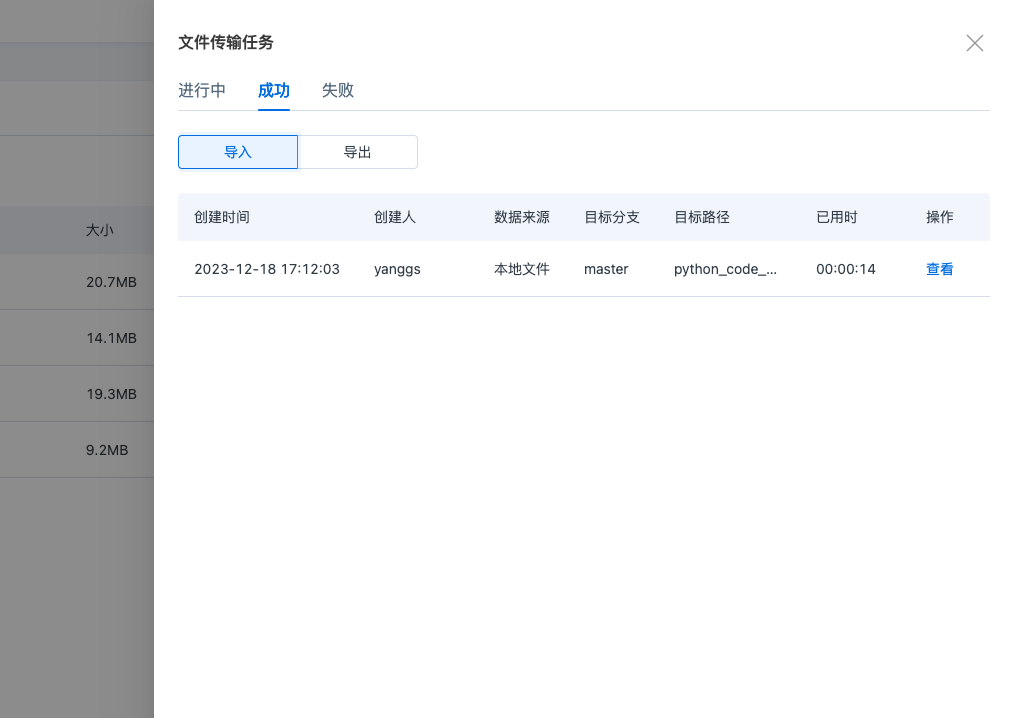
同时,也可以在数据传输任务界面,查看到自己导入的相对应数据
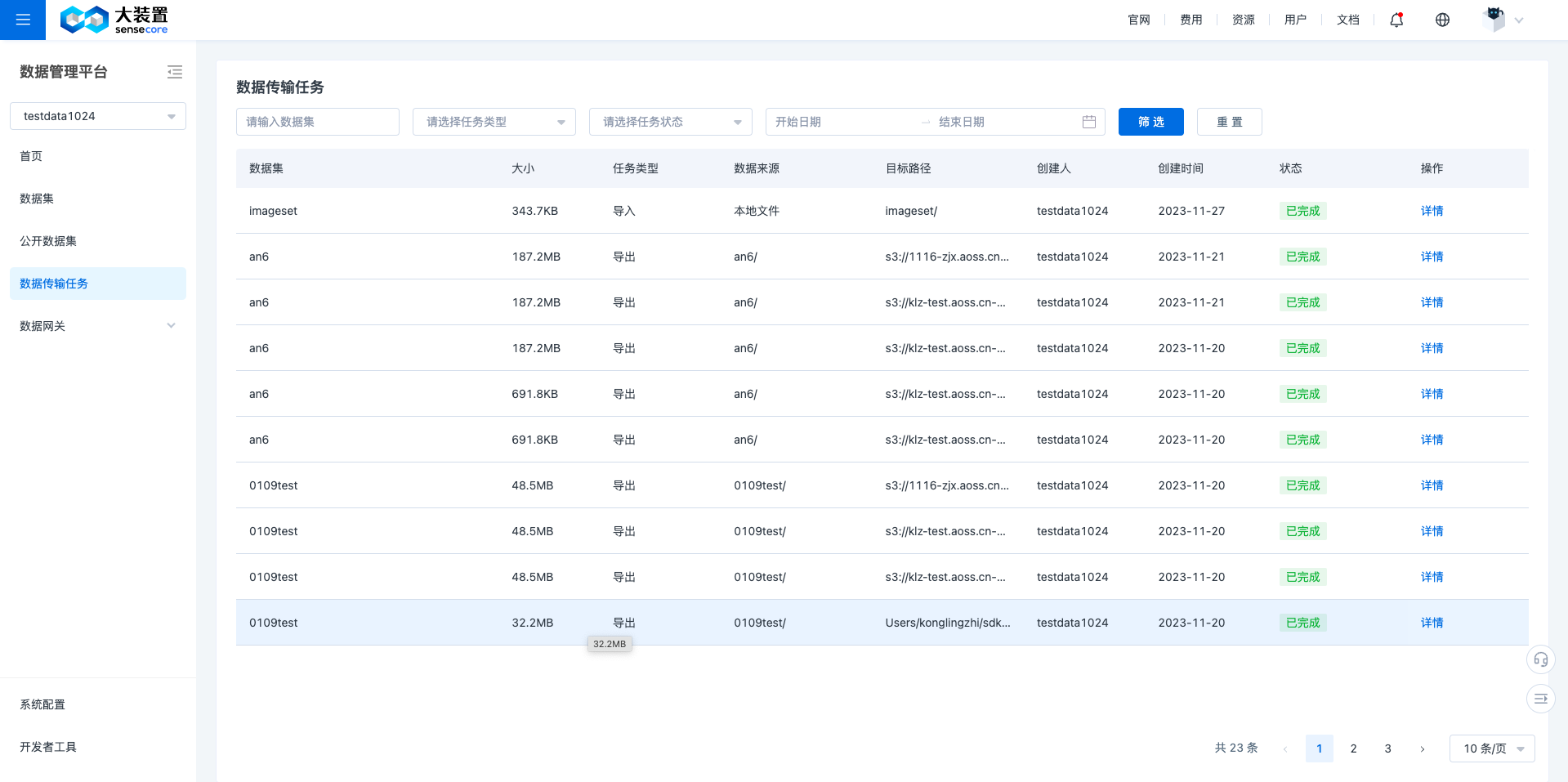
注:如果上传文件中有相应的问题会报错告知,比如 README.md 文件不符合校验、Annotation_config.json 文件不符合校验,请依据相应报错指引解决。
通过 CLI 添加文件
您可以通过CLI工具向数据集中添加文件,通过CLI的可以方便的把分散在不同地方的数据回流到数据管理平台。
在添加数据前,您需要获取到数据集地址和您的用户的AKSK。
数据集地址可以在数据集列表页或者是在数据集详情页中获取得到,
添加文件步骤:
配置 AKSK:
$ grav config AccessKeyID <AccessKeyID>
导入本地数据或者 OSS 数据:
$ grav upload <oss_path/local_path> <url>
例如:
grav upload ./data https://console.sensecore.cn/aidmp/Demo/cn-sh-01/repos/Demo.grav
grav upload s3://bucket1.aoss-internal.cn-sh-01.sensecoreapi-oss.cn/data https://console.sensecore.cn/aidmp/Demo/cn-sh-01/repos/Demo.grav
详细的 CLI 使用,请参考CLI使用指南
新建文本文件
文件栏中,可以点击添加按钮,点击新建文本文件,就可以新增指定分支、指定目录的文本文件。给文本文件命名,以及给一个相应的提交信息。
如果是 markdown 格式的文本文件,则可以预览查看相对应的格式效果。
概览页的初始化页面,也可以直接点击新建README.md,从而新增相对应的 README.md 文件,生成概览页面。
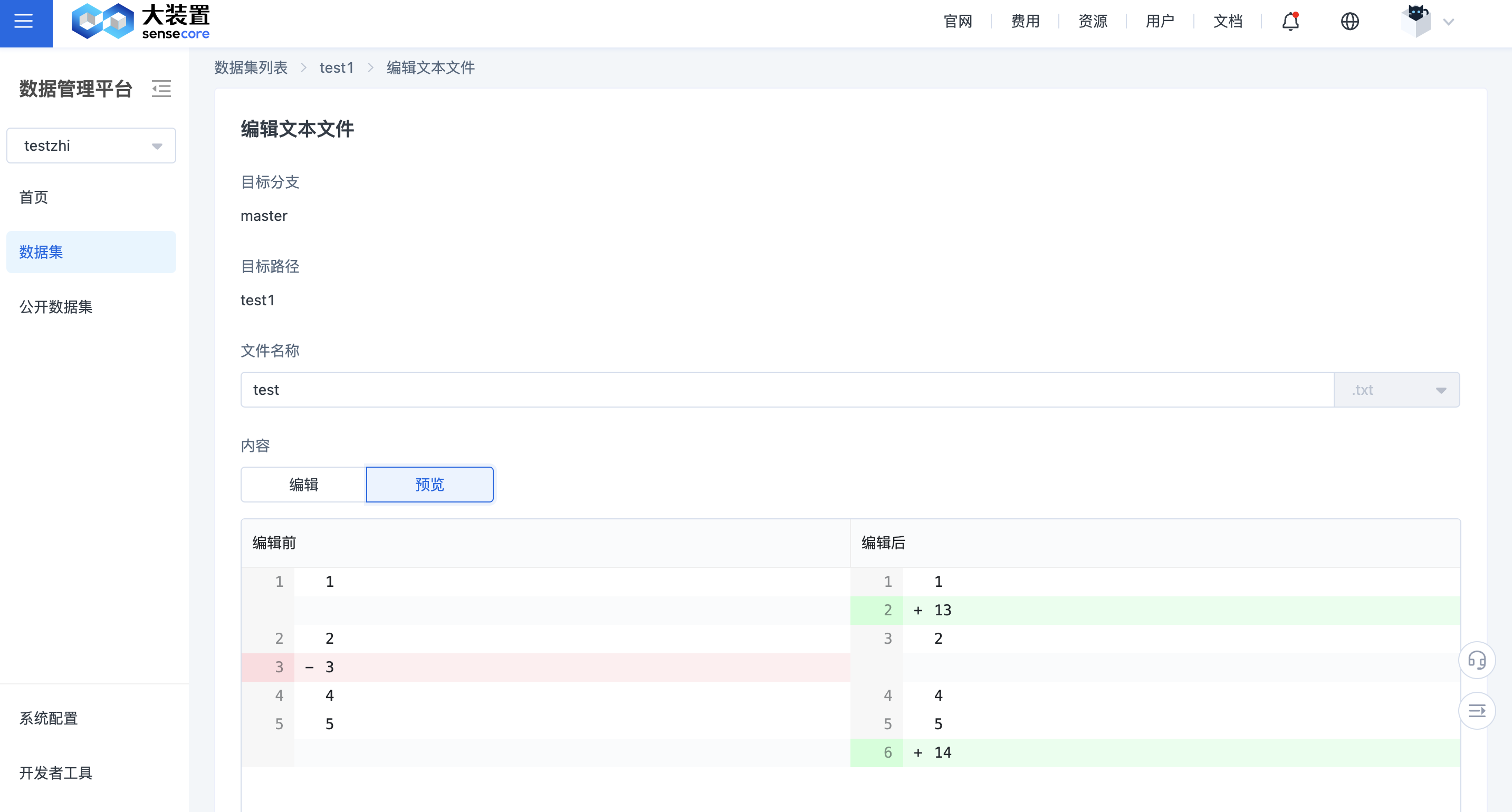
编辑文本文件
文件栏中,对于文本文件,可以点击编辑。正常的文本文件,可以预览,查看编辑前后的对比情况。如果是markdown 格式的文本文件,则可以预览查看相对应的格式效果。
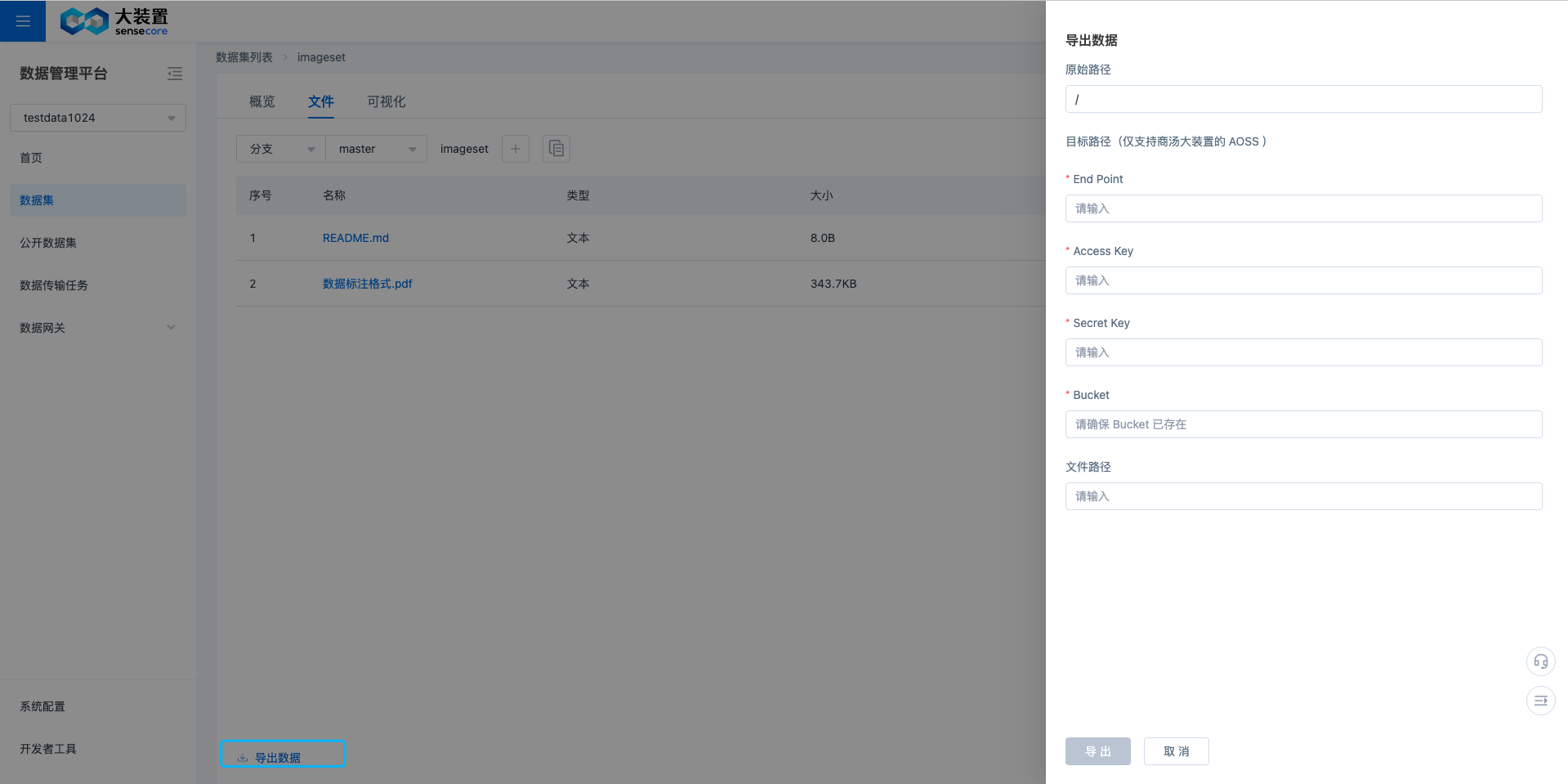
导出数据文件
数据集的文件列表页面,支持导出数据到大装置的 AOSS 当中,填写大装置 AOSS 的相应信息,可以导入数据到 AOSS 相应路径,同时,可以在数据传输任务处进行异步查看任务进度。
删除文件
文件列表中,对于所有文件,以及文件夹,都可以点击删除,删除时有相应的二次确认,并且用户可以写相应的提交信息。
数据集概览
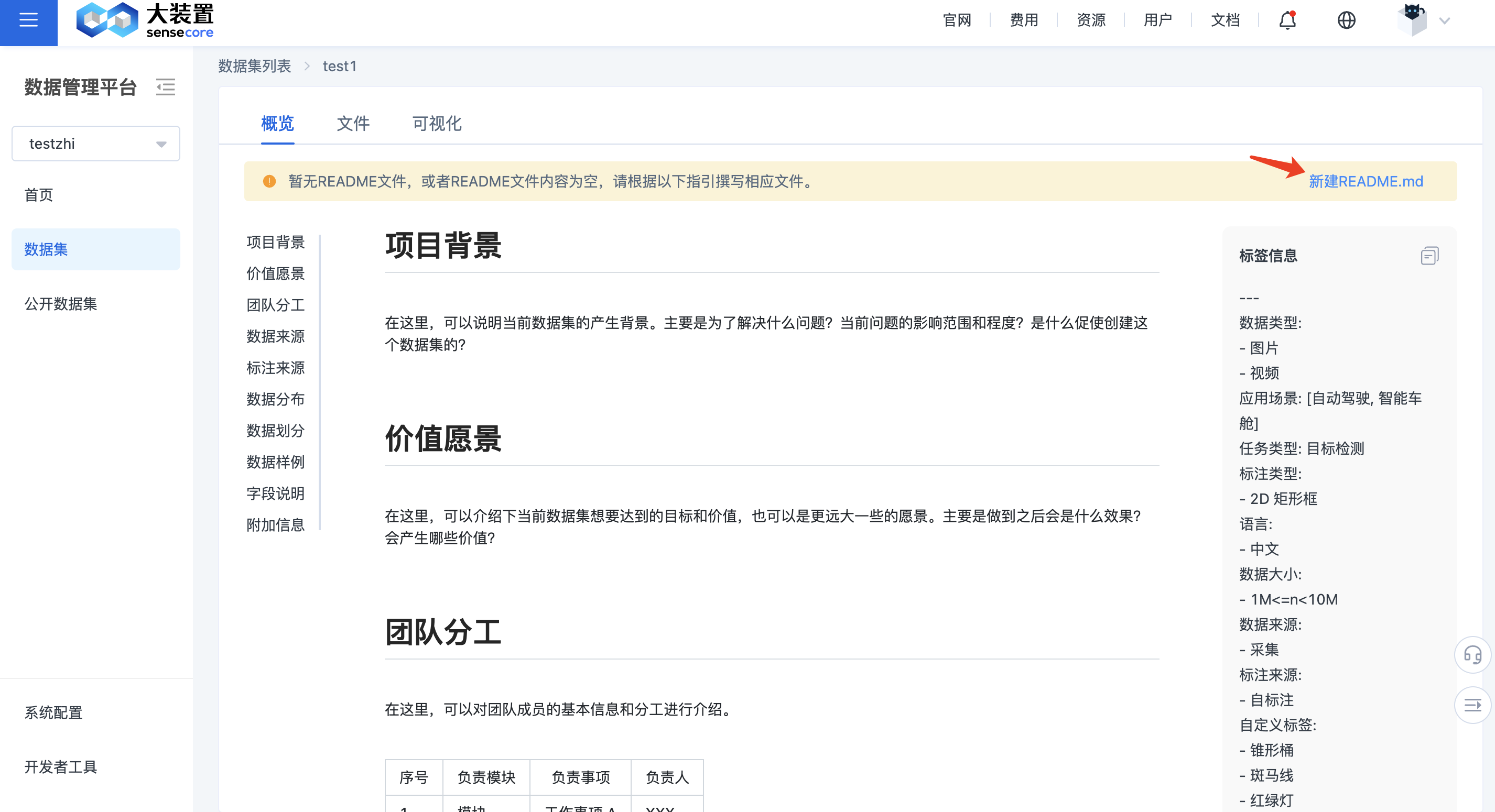
在数据集列表页,点击数据集名称,进入数据集详情展示页面,点击进入此数据集的概览页。
按照此页面的操作指引,可以新增 README.md 文件,并且撰写相应的标签信息,即可展示出所撰写的概览页内容。
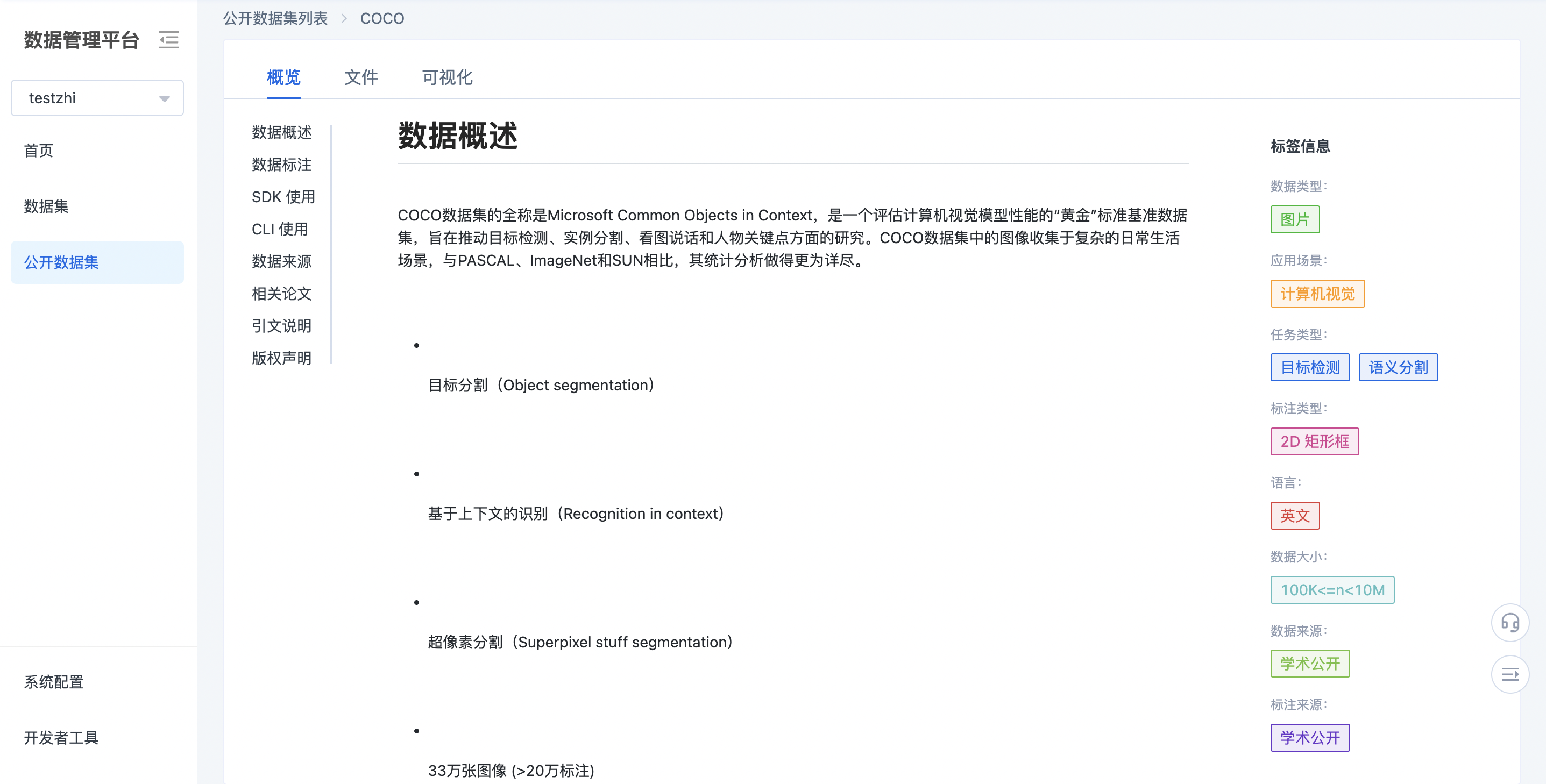
如下所示,为点击概览页的初始化页面和示例页面。
数据可视和检索挖掘
数据集级的标签检索
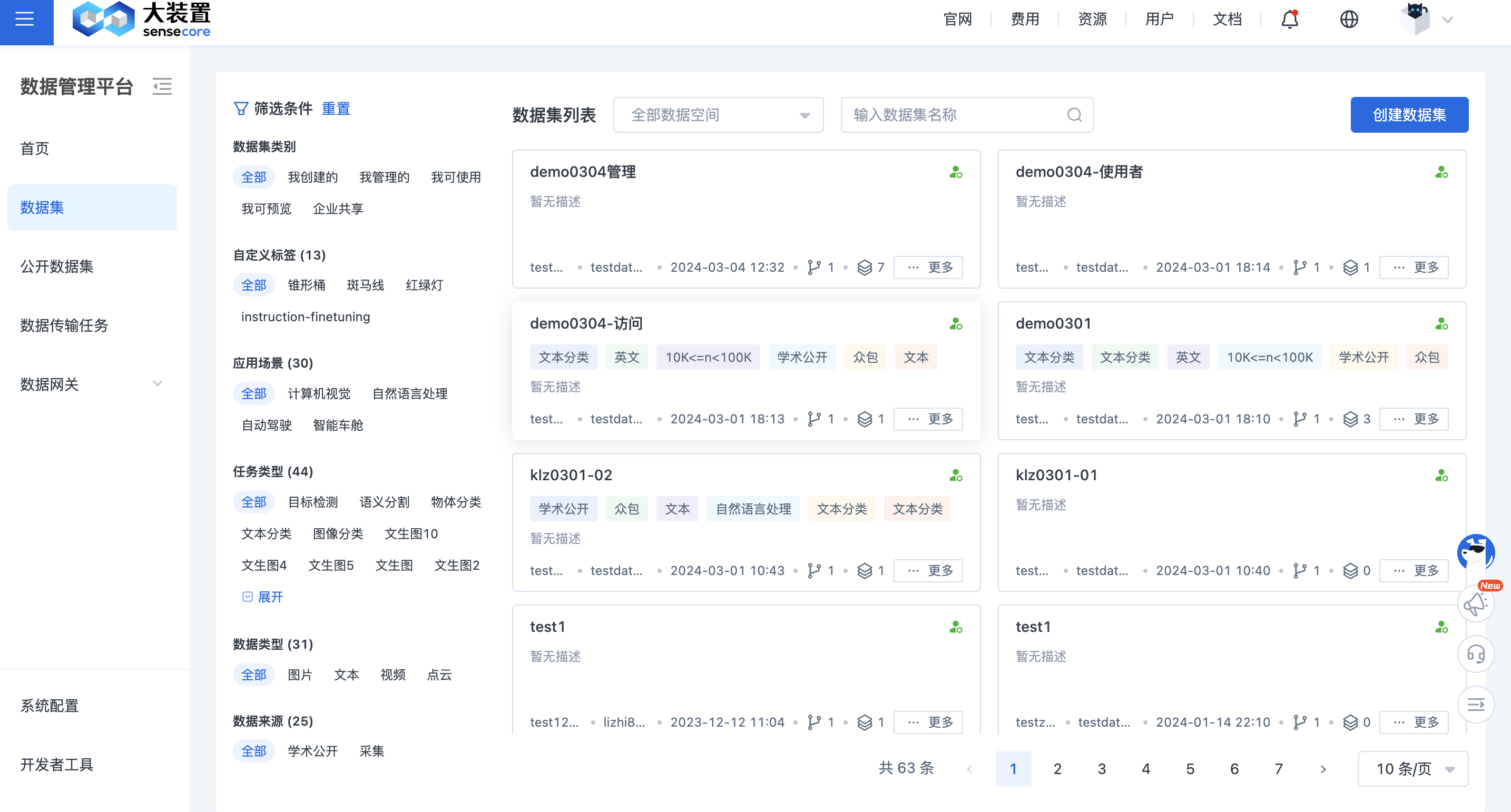
点击进入数据管理平台,左侧点击数据集,即可进入数据管理平台的数据集列表页。
当存在多个数据集时,可以通过数据集名称或数据集标签进行筛选。
查看文件
在数据集列表页,点击数据集名称,进入数据集文件详情页面。可以在文件查看页面,可以切换分支、版本和文件路径。
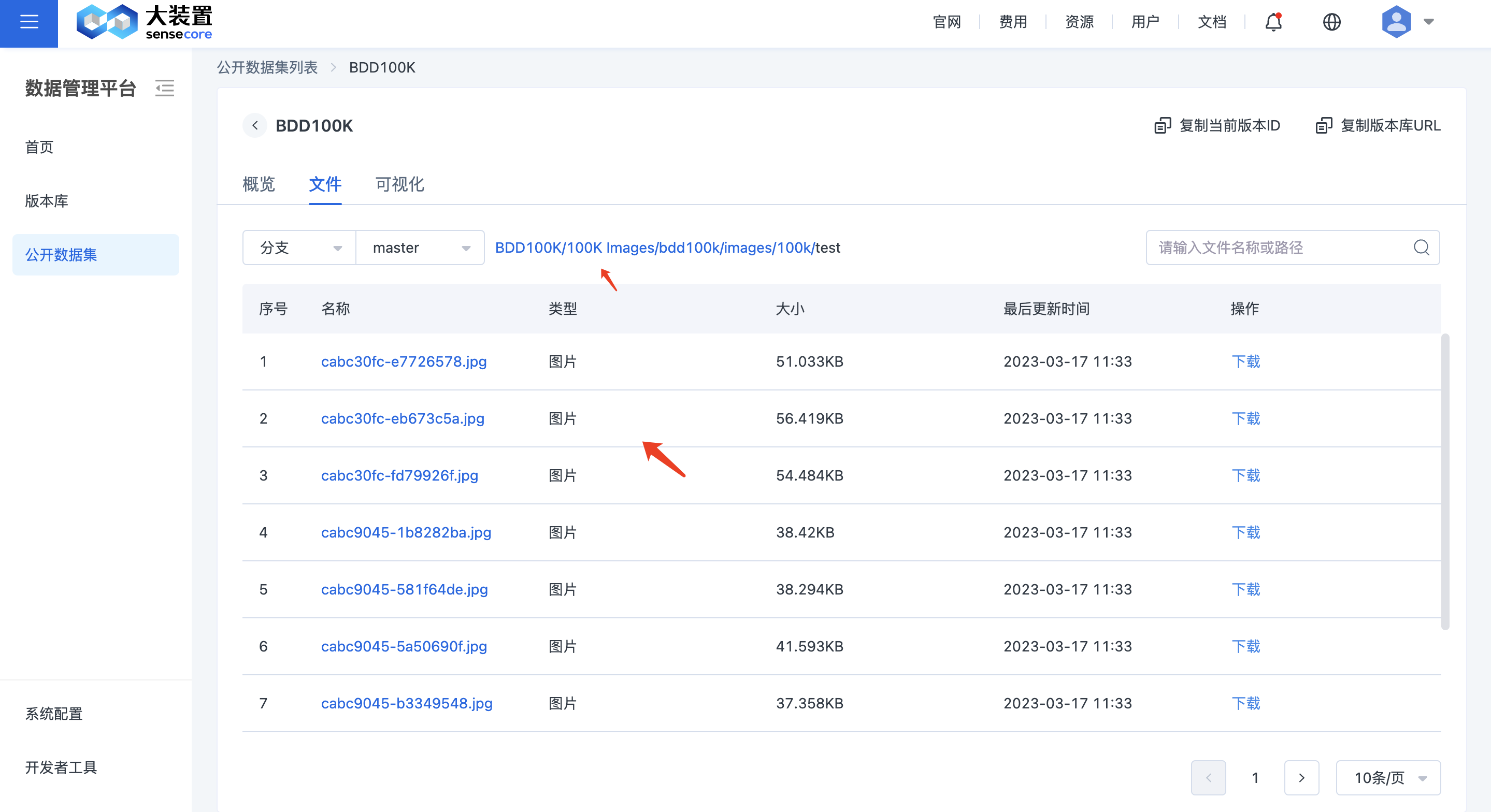
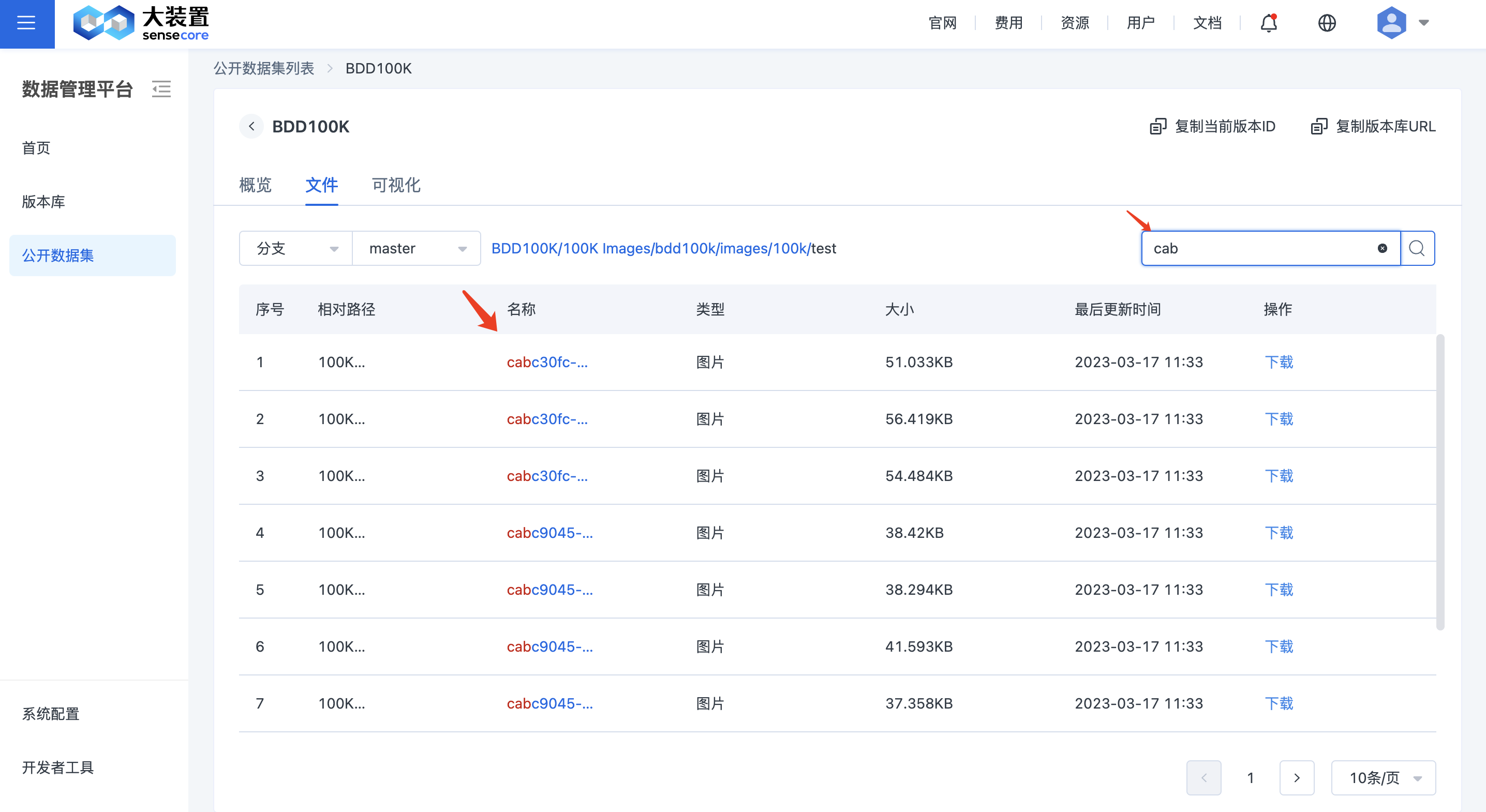
您可以根据文件名称,模糊检索文件,查看文件的路径。
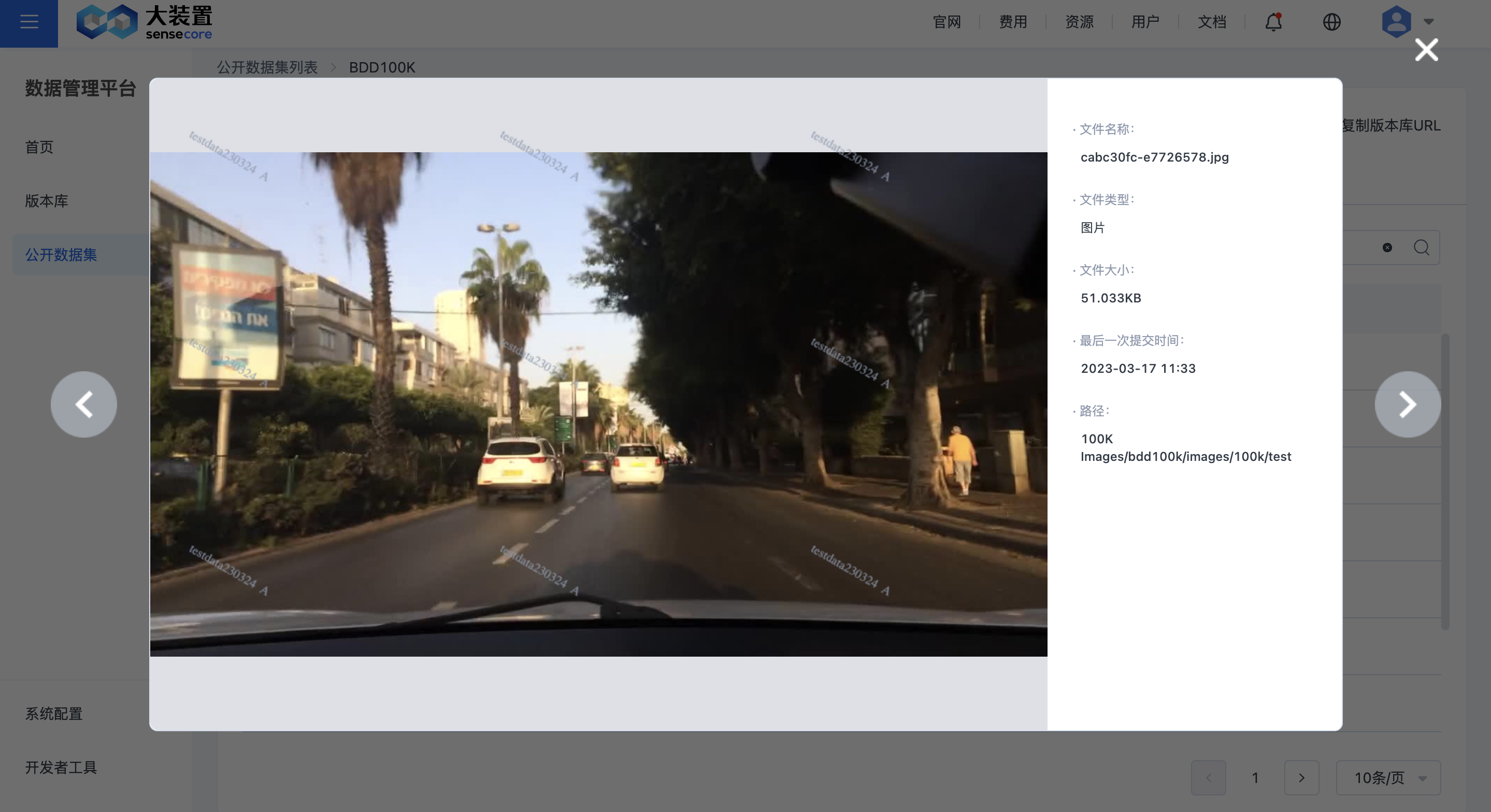
点击文件名称,即可预览文件详情,为了包含数据隐私,文件预览会打上明文水印。
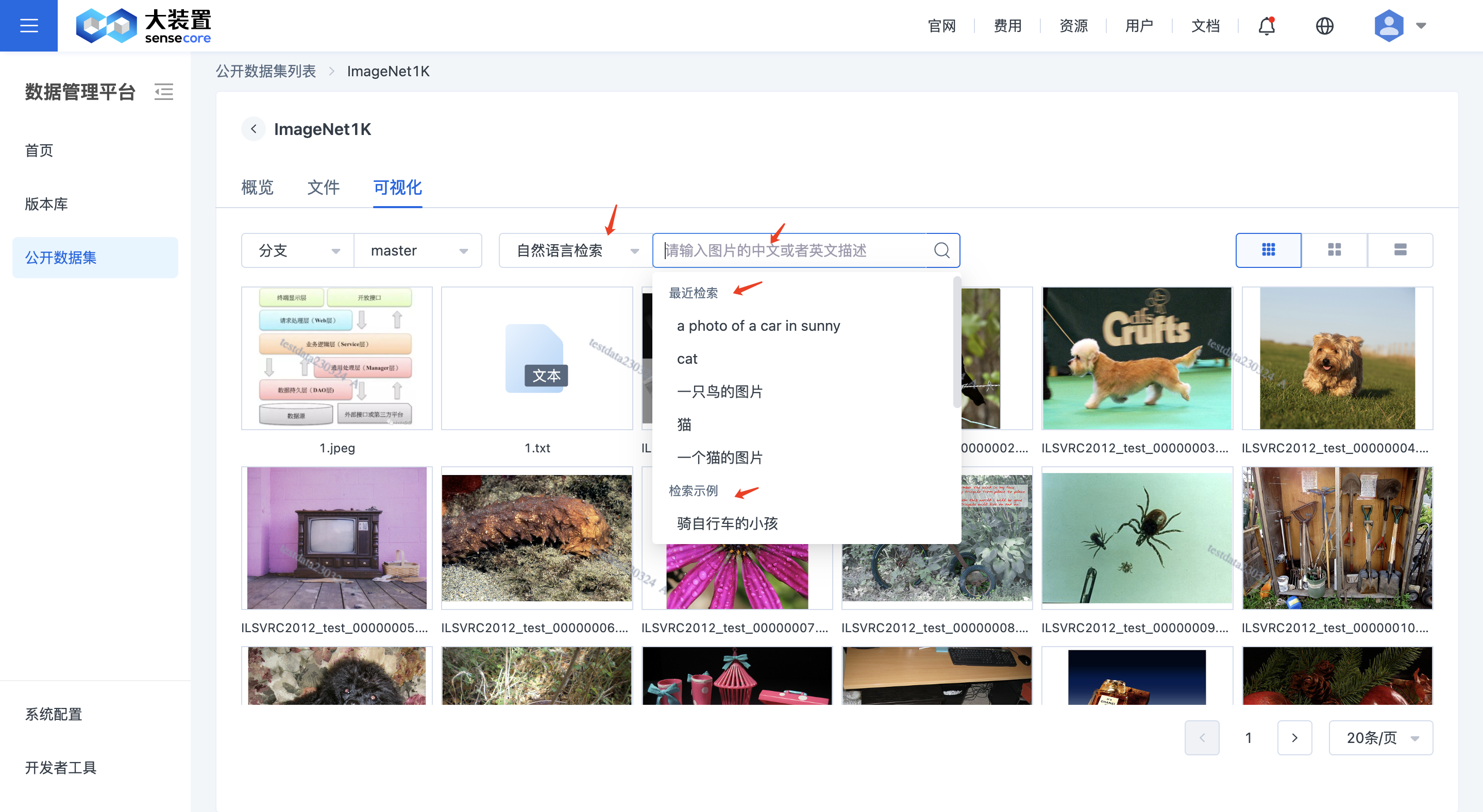
图片自然语言检索
进入数据集,在可视化页,切换到自然语言检索模式。
检索示例:繁忙的红绿灯,村庄雾霾的早晨等。
说明:自然语言检索基于优化后的CLIP模型,支持中英文语言输入,展示结果仅支持图片。数据集新增图片后,提取特征非实时,因此新增图片的检索有一定的时延。
标注可视化
查看标注,即对标注文件可视化,在数据集列表页,点击数据集名称,进入数据集可视化详情页面。在CLI或者Web上传标注文件和标注配置文件后,即可在可视化页面查看标注信息,如果您配置了多个标注单元,可以把标注单元作为筛选条件,在界面选择一个或者多个标注单元。效果如下:
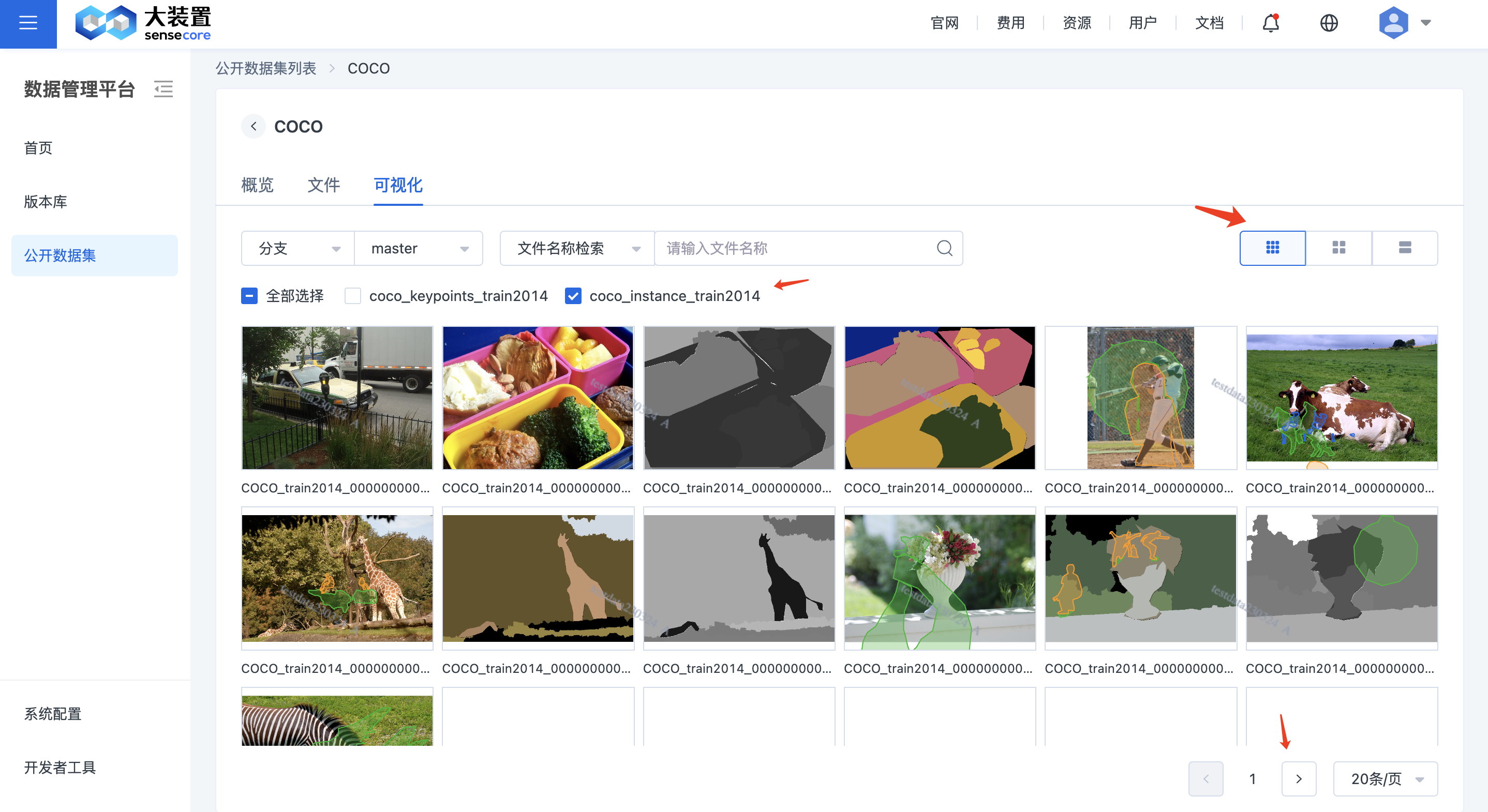
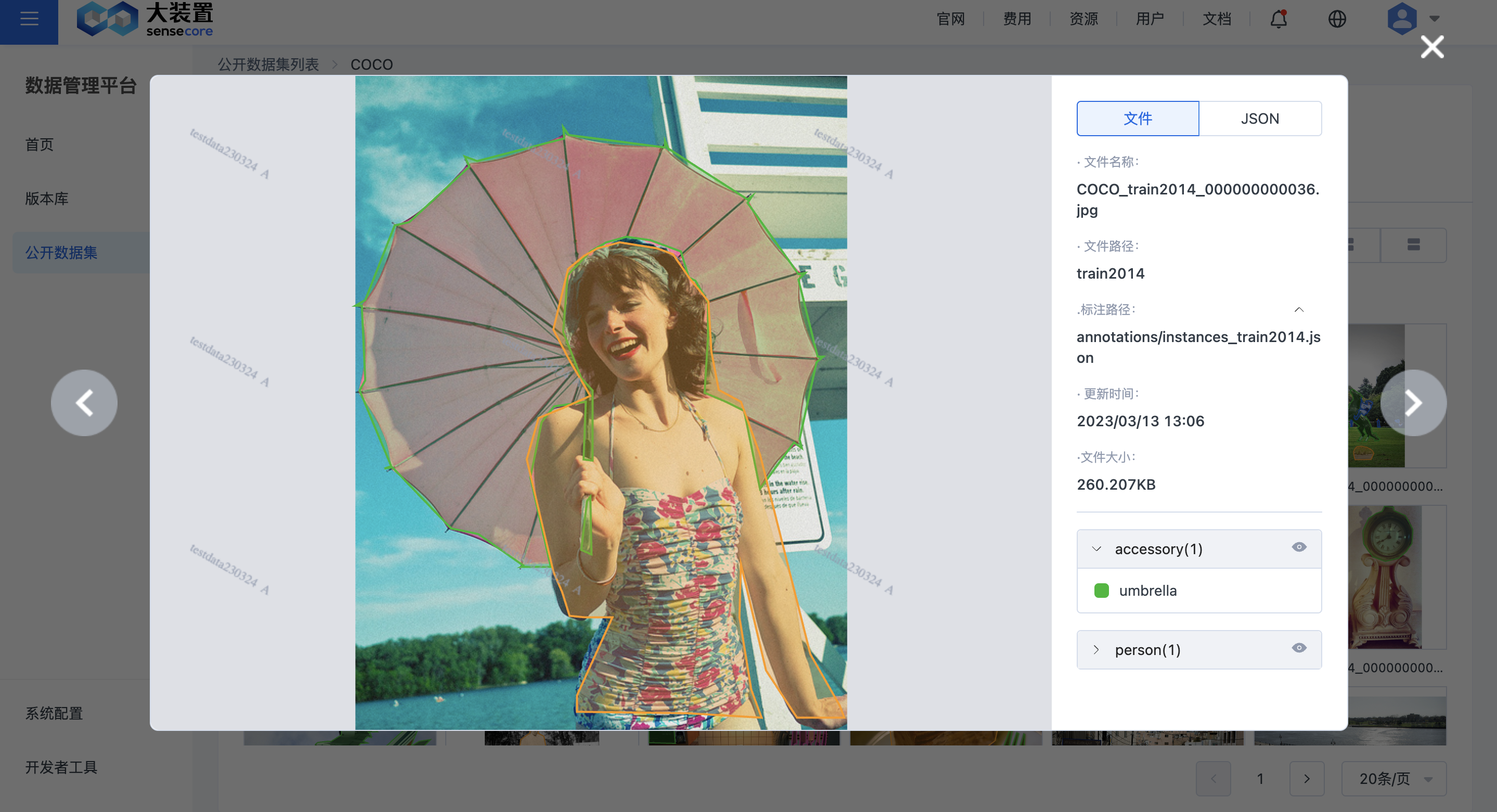
标注可视化整体要求
标注可视化需要满足如下要求,才能在WEB前端正常的展示:
1)原文件和标注文件分别放在不同的路径,并且其中一个路径不能包含另外一个路径。
2)标注配置文件Annotation_config.json放在数据集的一级目录,满足校验要求,如果不能满足校验要求,则无法上传成功。
3)标注格式目前支持 COCO、SenseBee 格式,后续会逐步支持其他格式。
4)其他标注格式,需要先把标注格式转换为COCO格式或者是 SenseBee 格式,才能对标注文件进行可视化。
标注配置文件
标注配置文件Annotation_config.json用来指定标注文件和原文件的关系,配置文件由若干个标注单元组成,每个标注单元表示一组标注信息,标注单元可以根据您的实际情况定义。
每个标注单元包含4个字段,系统会在您通过CLI或者Web界面上传的过程中校验,确保上传的配置文件正确,下表是校验规则。如果您上传的配置文件不正确,会在您上传的过程中给与提示。
| 字段名称 | 字段含义 | 校验方式 |
|---|---|---|
| annotation_name | 用来区分不同的标注单元,一个标注文件路径为一个标注单元 | 一个标注配置文件内不能重复,字段不能包含特殊字符和中文 |
| annotation_path | 表示标注文件存放的路径 | 一个标注配置文件内不能重复,路径必须存在 |
| annotation_format | 用来区分不同的标注格式,如COCO、SenseBee 等,目前支持 COCO、SenseBee | 值必须为“COCO” 或者是“SenseBee” |
| media_path | 表示媒体文件存放的路径 | 一个标注配置文件内可以重复,路径必须存储 |
Annotation_config.json数据结构和示例
Annotation_config.json数据结构:
[
{
"annotation_name" : str, //标注来源/批次名称
"annotation_path" : str, //标注文件路径
"annotation_format" : str, //标注格式类型,目前支持 COCO、SenseBee
"media_path" : str //媒体文件路径
},
{
...
}
]
Annotation_config.json配置示例:
coco_instance、coco_segmentation、coco_instance_2分别配置了训练数据目标检测的标注、训练数据实例分割的标注、测试数据目标检测的标注。
[
{
"annotation_name":"coco_instance",
"annotation_path":"annotations/instance_train.json",
"annotation_format":"COCO",
"media_path":"COCO2017/train_2017"
},
{
"annotation_name":"coco_segmentation",
"annotation_path":"annotations/segmentation_train.json",
"annotation_format":"COCO",
"media_path":"COCO2017/train_2017"
},
{
"annotation_name":"coco_instance_2",
"annotation_path":"annotations/instance_val.json",
"annotation_format":"COCO",
"media_path":"COCO2017/val_2017"
}
]
COCO格式样例数据集下载
您可以通过样例数据集,快速理解标注可视化的要求和相关配置,点击下载样例。
SenseBee 格式样例下载 SenseBee 格式标注工具的标注格式详细请下载附件查看 点击下载样例。 。
数据集使用
您可能会在模型训练中需要用到数据集的数据。可以直接使用 SDK 的 load_dataset 命令,加载数据集,用于训练。
from gravdataset import load_dataset
from torch.utils.data import DataLoader
dataset = load_dataset(<data_space_name/repo_name>, access_key_id=<YOUR_ACCESS_KEY_ID>, access_key_secret=<YOUR_ACCESS_KEY_SECRET>)
dataloader = DataLoader(dataset, batch_size=32, num_workers=4)
详细使用参考SDK使用指南。
可以通过 CLI 的 download 命令,把数据集分支数据下载到开发环境中。
grav download repo_url
详细使用参考CLI使用指南。
另外,您也可以很方便在 Web 页面上,对数据集进行可视化查看、文件操作和数据的检索挖掘。
数据管理平台首页
点击进入数据管理平台,左侧点击首页,即可进入数据管理平台的首页。
在此页面可以查看数据集个数、数据集文件数、用户数量、数据集存储量、本月外网下行流量、本月请求次数和数据包使用率。
同时可以查看数据集文件数的趋势图,可以选择时间区间,默认为最近一个月的时间区间。
同时,可以在首页,新购数据空间,以及对当前空间进行扩容操作。
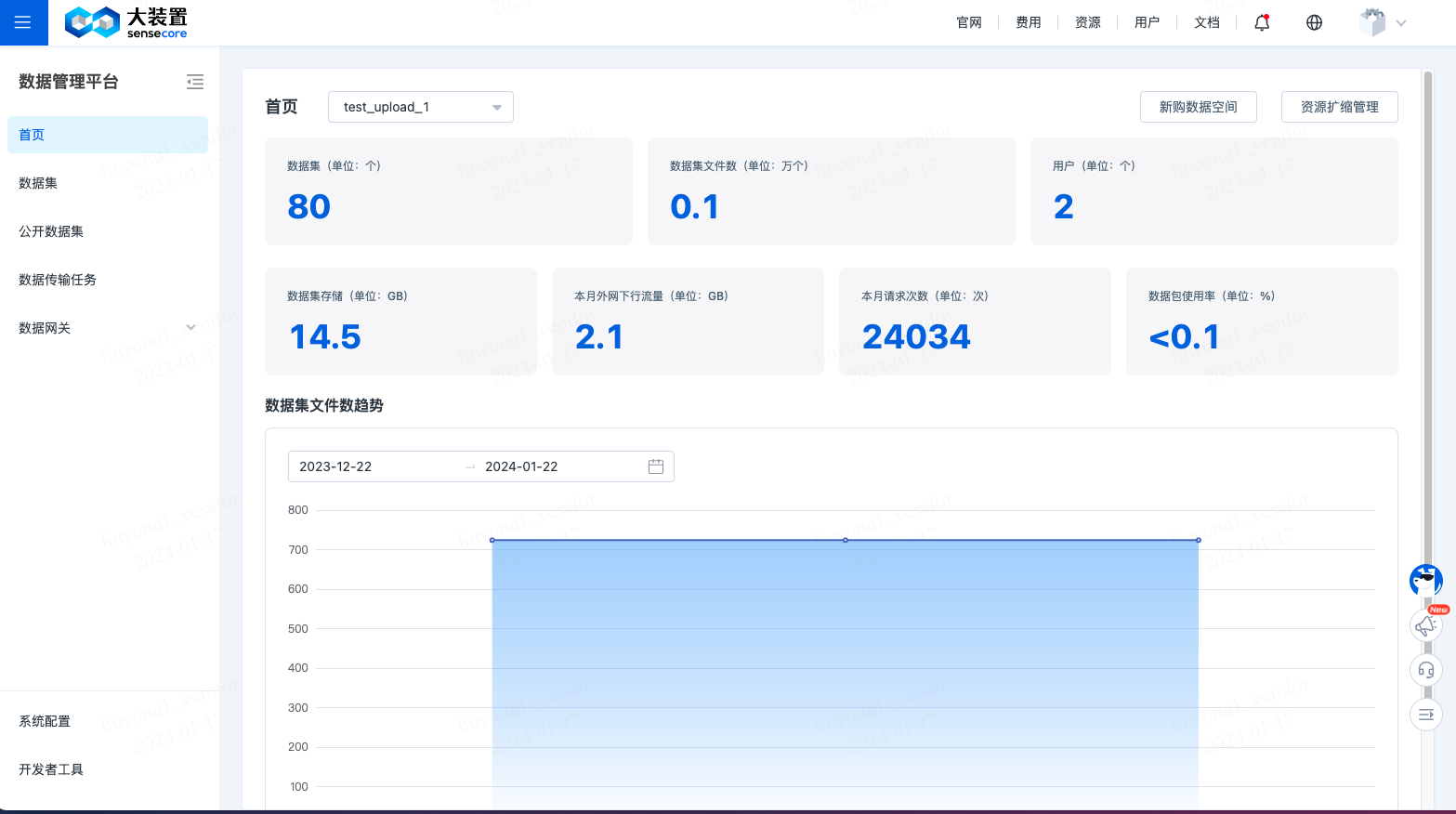
数据集的操作设置
权限设置
如需添加成员一起管理或者查看使用数据集,可以在通过权限设置添加或删除成员、用户组来实现数据集的成员管理。
进入数据集-设置-权限界面,点击添加成员,在对话框中,选择成员或者用户组,输入要添加的成员名称和用户组名称,选择角色,点击添加即可。
如果有想要共享到全体租户的数据集,可以选在用户- All Employees ,租户全体员工,进行相应数据集权限的分配操作。
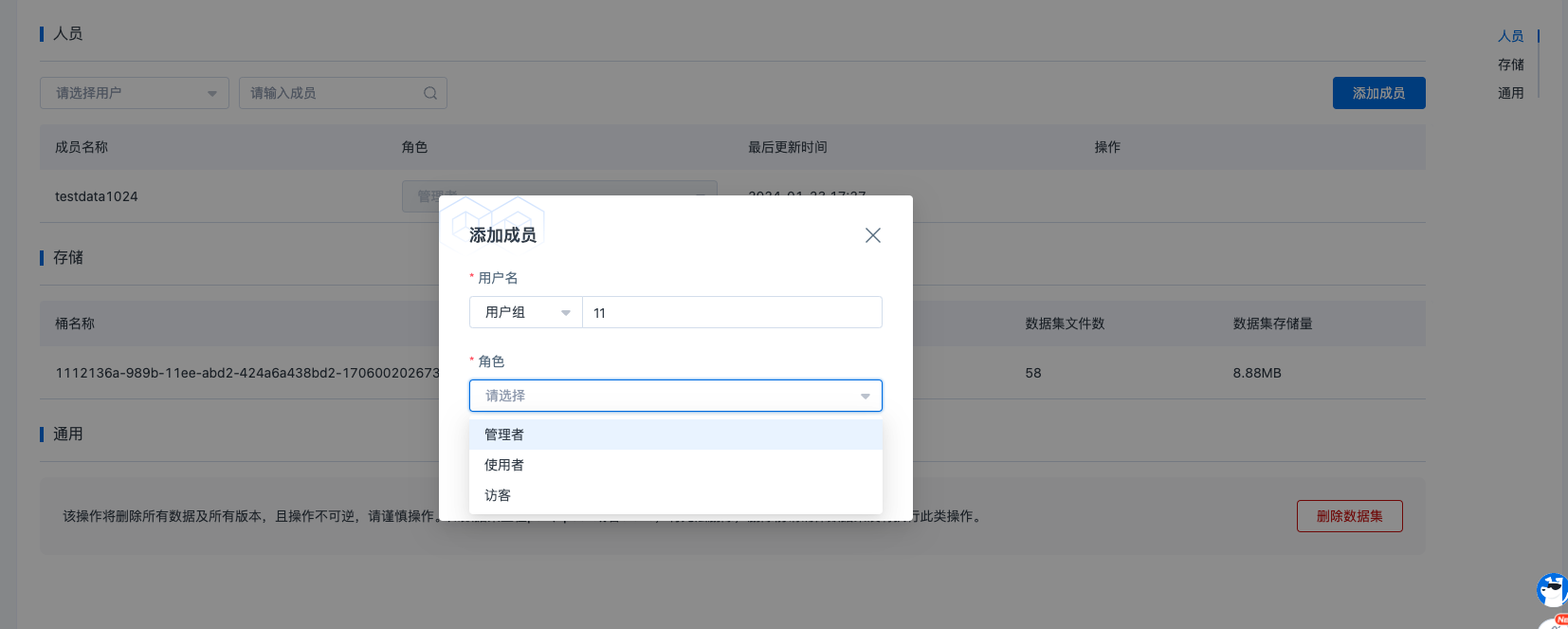
添加的成员必须先自己创建好 AccessKey,用户访问系统存储,否则会添加失败。被添加成员创建 AccessKey。
如需删除成员,选择对应的成员,点击删除,确认即可。
删除数据集
进入数据集-设置-通用界面,点击删除数据集,二次确认即可删除。
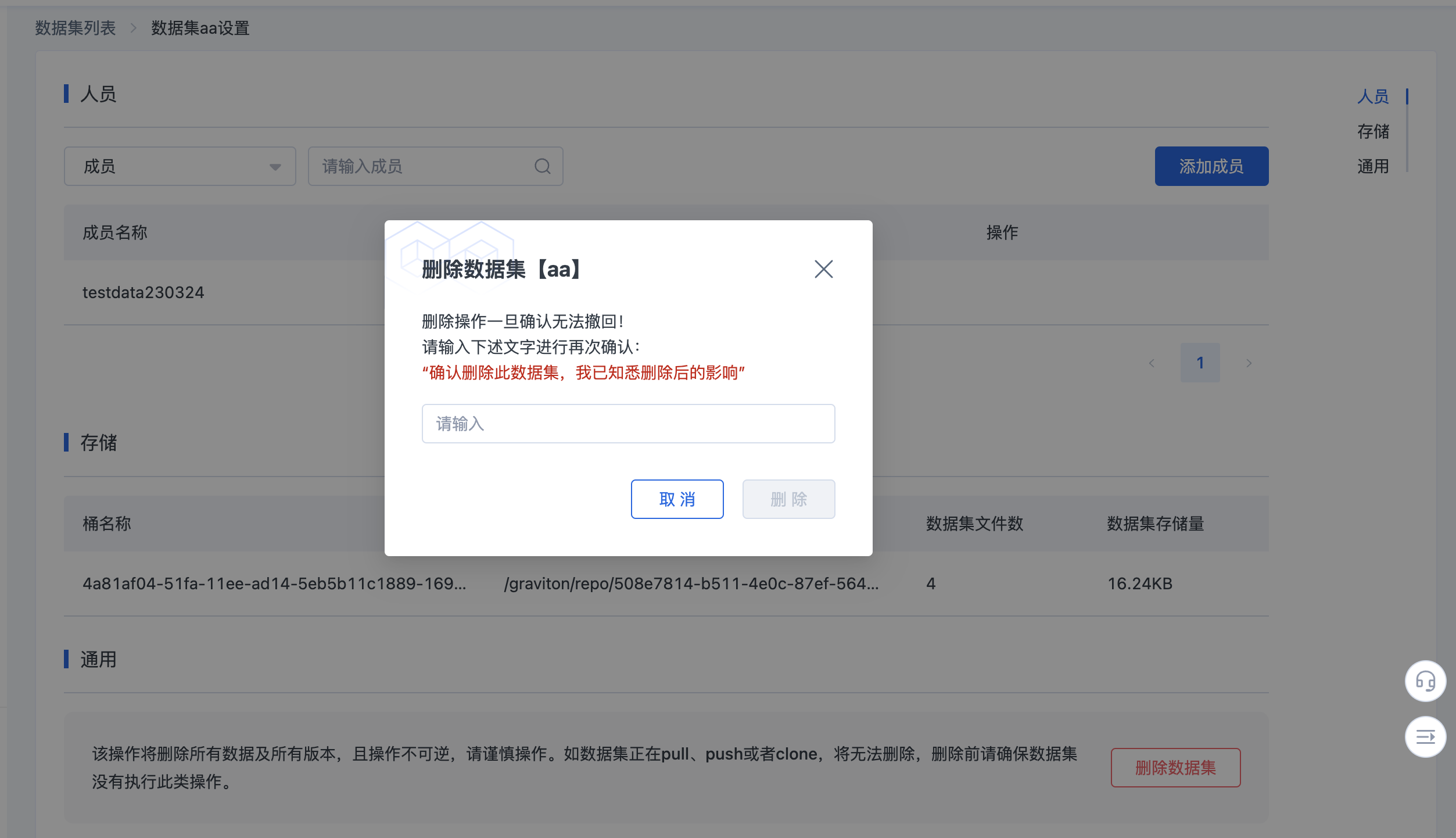
数据集删除后,数据集和相应数据无法恢复,请务必谨慎操作。
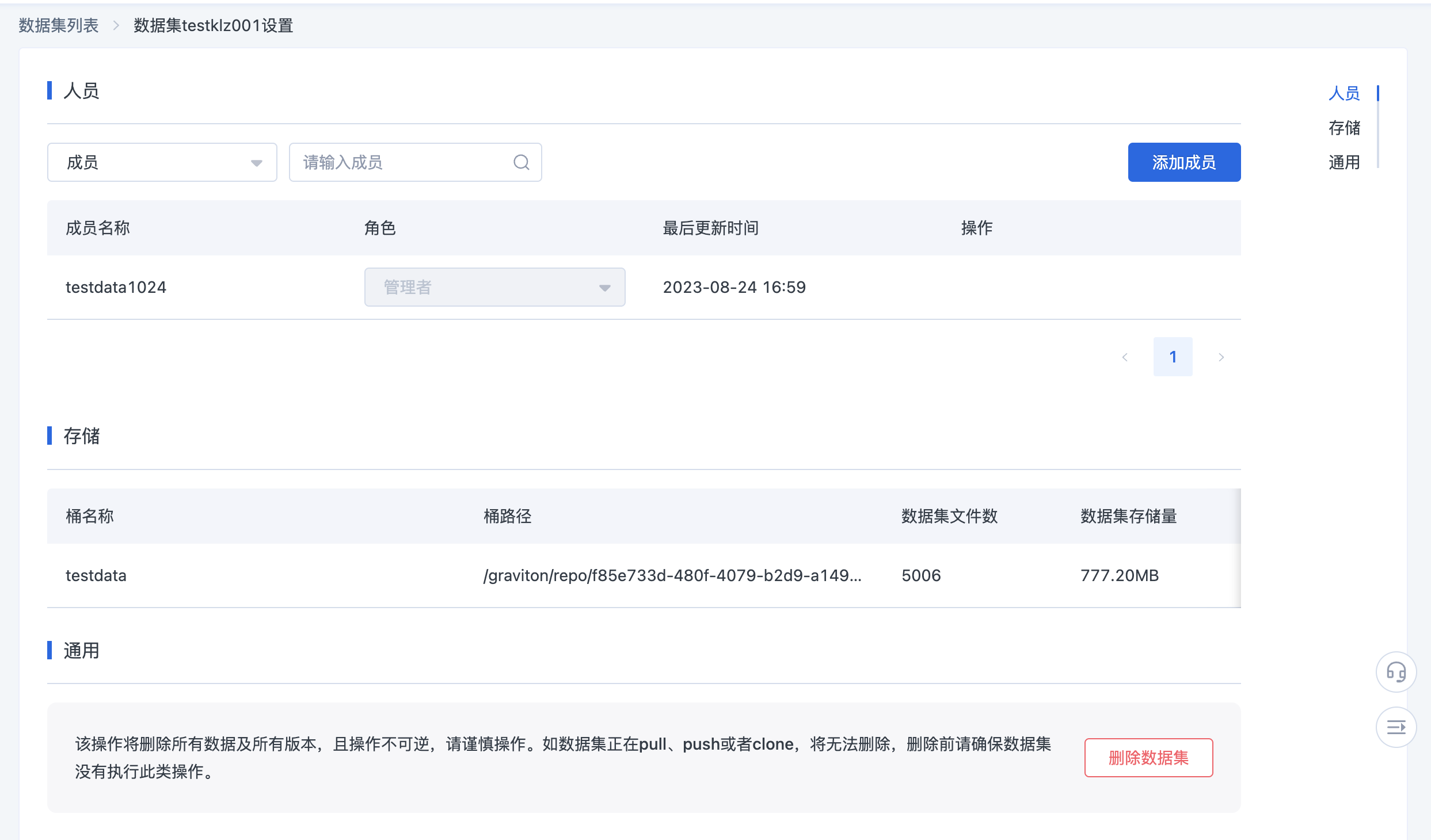
数据集的存储信息
进入数据集-设置-存储界面,即可以查看此数据集的详细存储信息。
如果想要使用 SenseCore 的 AI 缓存服务(ACS),可以将数据集的桶名称和桶路径进行加速,方便数据集的多次调用。ACS 的详细使用可参考AI 缓存服务 ACS。
公开数据集
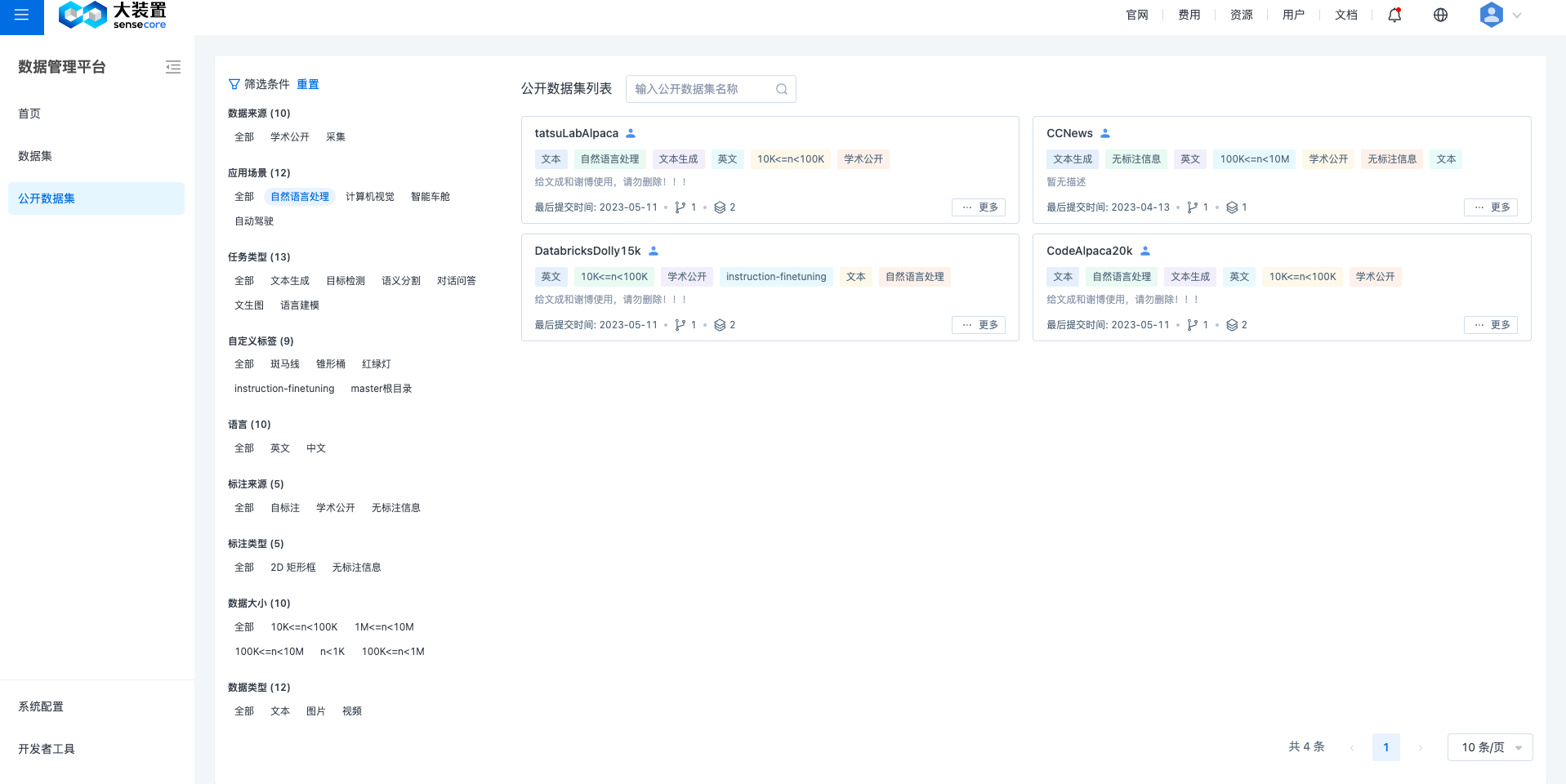
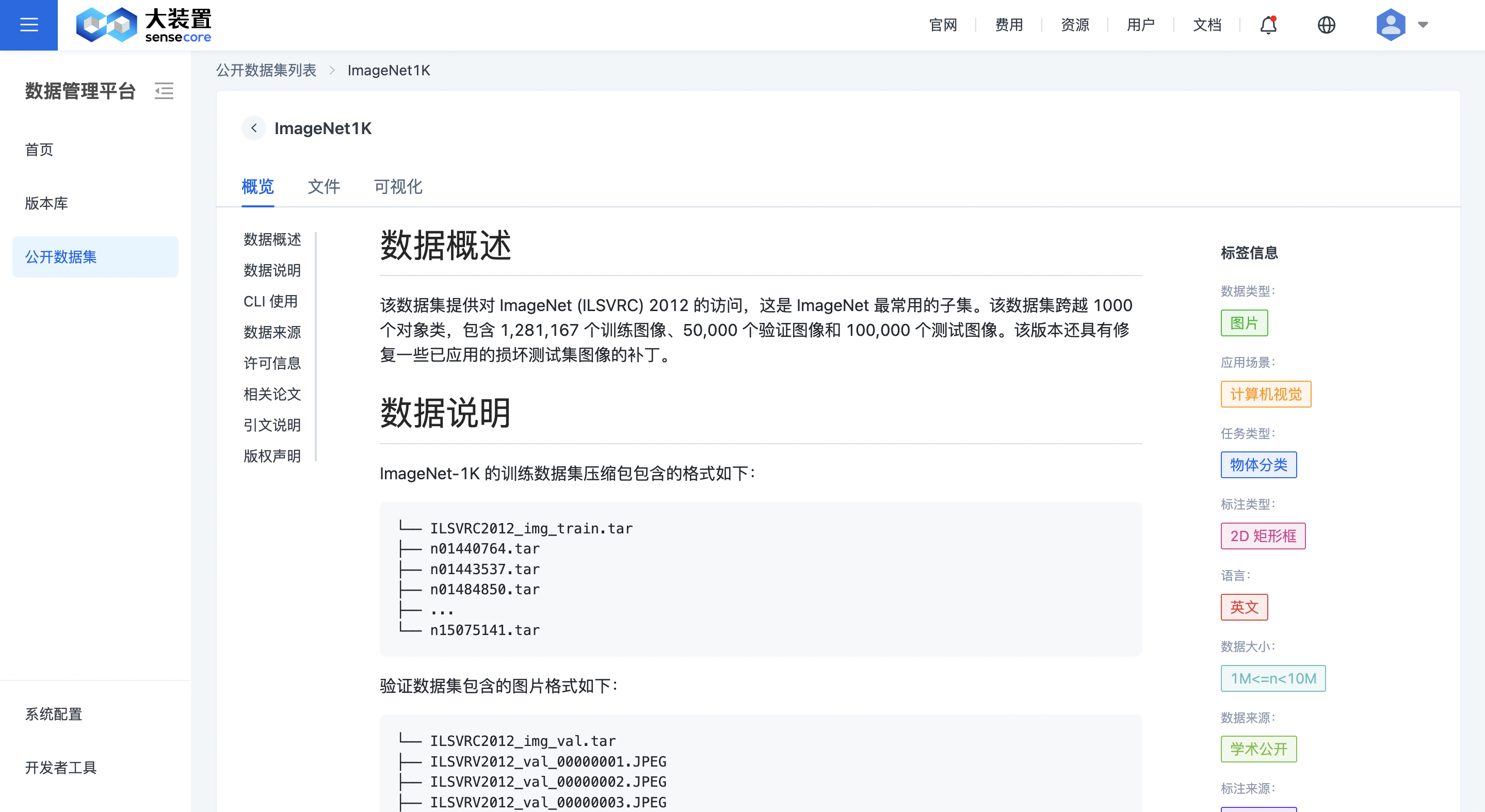
公开数据集检索查看
无需事先开通数据管理平台,公开数据集可即开即用。在左侧菜单栏,选择公开数据集,即进入公开数据集列表。
当前公开数据集免费访问,在 SenseCore 产品体系内免费使用,请注意,后续版本可能会收取一定费用
可以通过公开数据集名称或标签进行筛选。
注:每个租户看到的公开数据集一样,由系统提供,并且会定期添加或更新公开数据集。
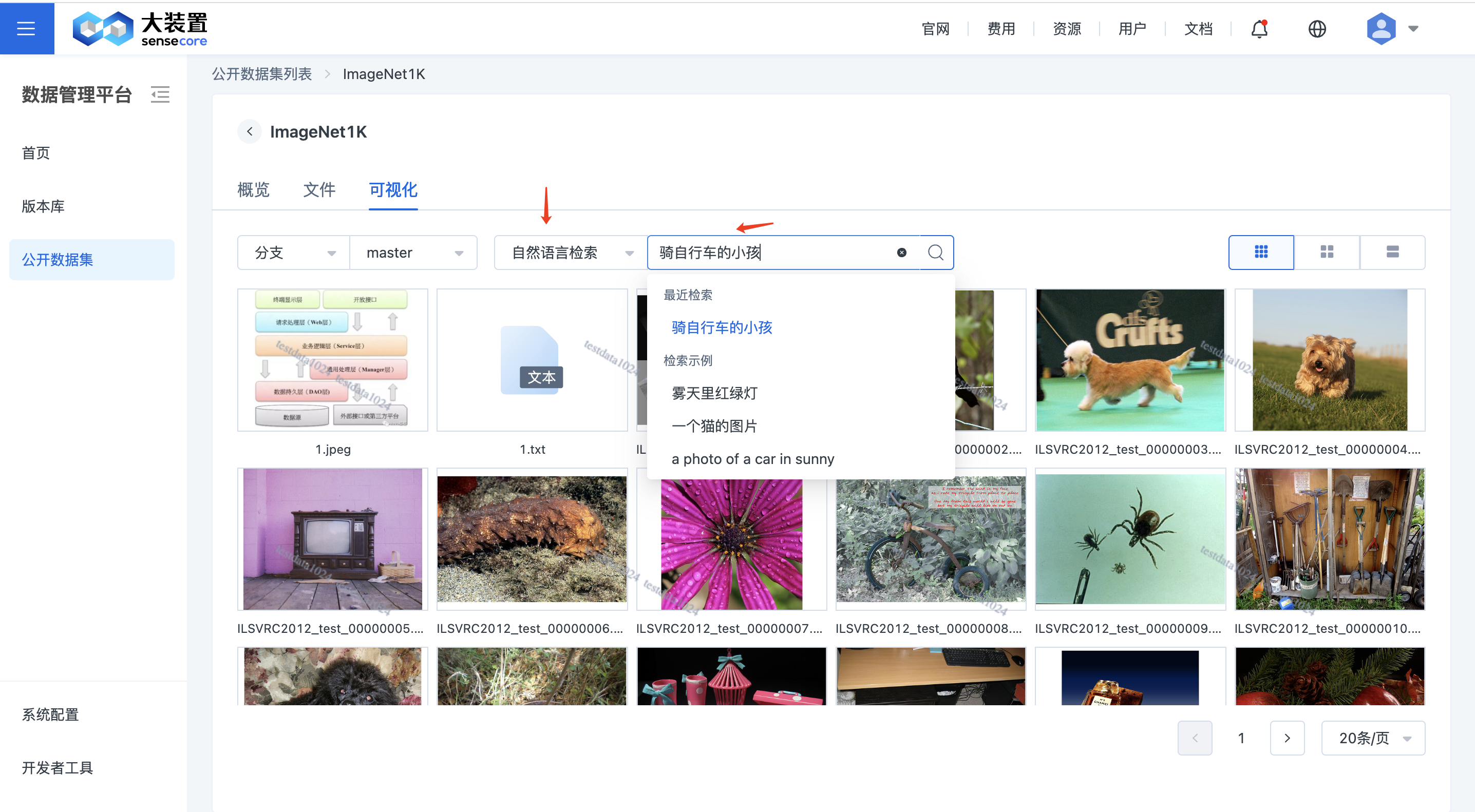
公开数据集图片自然语言检索
进入公开数据集,在可视化页,切换到自然语言检索模式。
检索示例:繁忙的红绿灯,村庄雾霾的早晨等。
说明:自然语言检索基于优化后的CLIP模型,支持中英文语言输入,展示结果仅支持图片。
公开数据集的使用
对于数据管理平台提供的公开数据集,可以采用 PythonSDK 的 load_dataset 方式加载数据集,用于训练,示例如下。
from gravdataset import load_dataset
from torch.utils.data import DataLoader
dataset = load_dataset("OpenDataSet/ImageNet1K", access_key_id=<YOUR_ACCESS_KEY_ID>, access_key_secret=<YOUR_ACCESS_KEY_SECRET>)
dataloader = DataLoader(dataset, batch_size=32, num_workers=4)
详细使用参考SDK使用指南。
可以通过 CLI 的 download 命令,把数据集分支数据下载到开发环境中。
grav download repo_url
详细使用参考CLI使用指南。
配置说明
README.md 撰写说明
README 文档,主要目的是: 说明清楚此 Repo 的创建背景、目标价值,并且介绍当前 Repo 的详细情况。 以便于快速了解此 Repo 的相关信息,有利于团队之间高效合作。 下面是给出的一种格式示例,供参考使用。同时也可直接下载样例修改:点击下载 README.md 样例
项目背景
在这里,可以说明当前 Repo 的产生背景。主要是为了解决什么问题?当前问题的影响范围和程度?是什么促使创建这个 Repo 的?
价值愿景
在这里,可以介绍下当前 Repo 想要达到的目标和价值,也可以是更远大一些的愿景。主要是做到之后会是什么效果?会产生哪些价值?
团队分工
在这里,可以对团队成员的基本信息和分工进行介绍。
| 序号 | 负责模块 | 负责事项 | 负责人 |
|---|---|---|---|
| 1 | 模块一 | 工作事项 A | XXX |
| 2 | 模块二 | 工作事项 B | XXX |
| 3 | 模块三 | 工作事项 C | XXX |
| … | … | … | … |
数据来源
在这里,描述数据的来源,即最初创建数据的人员或系统。例如外部采集、互联网爬取、AI 生成、专家生成等。
标注来源
在这里,说明标注是由人类生成的,还是由机器生成的。描述最初创建标注的人员或系统,及其标注的标准。例如:外部采集、互联网爬取、众包、自标注、AI 生成、专家生成等。
数据分布
在这里,描述当前数据的分布情况。如数据的整体类型分布是什么样的?文件大小分布是什么样的?
数据划分
在这里,请描述并命名 Repo 中数据的不同划分,如训练集、测试集和验证集。提供每个划分的数据量大小,以及这么划分的原因。
数据样例
在这里,提供数据的示例和简要说明。如果可用,请提供指向更多示例的链接。
字段说明
在这里,列出并描述 Repo 中存在的字段,以及它们的数据类型,说明它们的具体含义。
附加信息
在这里,描述附加需要额外说明的信息。
Repo 标签信息撰写说明
撰写位置
Repo 的标签信息文本内容放在 README.md 文件的开头,并且用特殊标示作为一个标签信息块来区分开
撰写模板
---
数据类型: # 图片、视频、音频、文本、点云、其它
- 图片
- 视频
应用场景: [自动驾驶, 智能车舱] # 自动驾驶、科研、智能车舱、智慧城市、智慧医疗、自定义(任何输入的字段都可以)
任务类型: 目标检测 # 目标检测、图像分类、语音识别、视频分类、图像生成、自定义(任何输入的字段都可以)
标注类型: # 2D 矩形框、2D 关键点、语义分割图、多标签分类、自定义(任何输入的字段都可以)
- 2D 矩形框
语言: # 中文、英文、其它
- 中文
数据大小: # n<1K、1K<=n<10K、10K<=n<100K、100K<=n<1M、1M<=n<10M、10M<=n<100M、100M<=n<1B、1B<=n<10B、n>=10B、未知
- 1M<=n<10M
数据来源: # 采集、互联网爬取、AI 生成、专家生成、自定义(任何输入的字段都可以)
- 采集
标注来源: # 采集、互联网爬取、众包、自标注、AI 生成、专家生成、自定义(任何输入的字段都可以)
- 自标注
自定义标签: # 锥形桶、斑马线、红绿灯、自定义(任何输入的字段都可以)
- 锥形桶
- 斑马线
- 红绿灯
---
校验规则
当前支持的标签名称和相对应的标签内容如下表所示:
| 数据集标签 | 支持范围 | 备注 |
|---|---|---|
| 数据类型 | 图片、视频、音频、文本、点云、其它 | 支持多选 |
| 应用场景 | 自动驾驶、科研、智能车舱、智慧城市、智慧医疗、自定义(任何输入的字段都可以) | 支持多选 |
| 任务类型 | 目标检测、图像分类、语音识别、视频分类、图像生成、自定义(任何输入的字段都可以) | 支持多选 |
| 标注类型 | 2D 矩形框、2D 关键点、语义分割图、多标签分类、自定义(任何输入的字段都可以) | 支持多选 |
| 语言 | 中文、英文、其它 | 支持多选 |
| 数据大小 | n<1K、1K<=n<10K、10K<=n<100K、100K<=n<1M、1M<=n<10M、10M<=n<100M、100M<=n<1B、1B<=n<10B、n>=10B、未知 | 单选 |
| 数据来源 | 采集、互联网爬取、专家生成、AI 生成、其它 | 支持多选 |
| 标注来源 | 采集、互联网爬取、众包、自标注、专家生成、AI 生成、其它 | 支持多选 |
| 自定义标签 | 锥形桶、斑马线、红绿灯、自定义(任何输入的字段都可以) | 支持多选 |
版本记录
| 版本名称 | 功能描述 | 发布时间 |
|---|---|---|
| 数据管理平台 GA 版 v1.0.0 | 新增 SDK 加载数据集功能,新增自然语言检索图片功能,新增数据集标签检索功能,新增大批量文件 Web 端上传的功能。 | 2023-3-31 |
| 数据管理平台 GA 版 v1.1.0 | 支持大模型相应的大数据集,上线到公开数据集,可供平台查看和使用。支持公开数据集即开即用,无需事先开通数据管理平台,为用户提供更好便利性。拆出 SDK 操作指南、CLI 操作指南,使文档具备更好的可读性。 | 2023-4-28 |
| 数据管理平台 GA 版 v1.2.0 | CLI 支持大规模数据集的导入,帮助企业更好地管理大模型相关的数据资源。 | 2023-5-31 |
| 数据管理平台 GA 版 v1.3.0 | 实现与AI对象存储服务(AOSS)生命周期统一,并且支持资源超量降级处理,以及支持灵活扩容。将数据集的存储地址置于公开可见,从而支持AI缓存服务缓存数据集,使得SDK可以更快速地读取数据. 整体优化前端界面体验,全面提升用户的操作体验。 | 2023-6-30 |
| 数据管理平台 GA 版 v1.4.0 | 扩展可供访问使用的公开数据集数量;upload 命令支持取消锁定路径功能;数据集初始化页面改为推荐使用upload命令;数据集支持默认按照更新时间进行倒序排列。 | 2023-7-30 |
| 数据管理平台 GA 版 v1.5.0 | SDK 支持文生图大模型 tar 包加载推荐方案;Web 端文件导入支持 AOSS、新建文件夹。 | 2023-8-30 |
| 数据管理平台 GA 版 v1.6.0 | 引入数据空间,实现更精细化的数据管理和租户服务;对接云管资源转移功能,确保数据空间的资源能够顺畅无阻地进行转移;增加数据集查看者角色,可以实现更细粒度的数据权限控制。 | 2023-9-30 |
| 数据管理平台 GA 版 v1.7.0 | 对接云审计功能,支持对 Web 端操作进行详细记录;API 中心接入;前端支持查看 Parquet 文件。 | 2023-10-30 |
| 数据管理平台 GA 版 v1.8.0 | 对接云审计功能二期,支持对 CLI、SDK 端操作进行详细记录; 标注可视化支持 SenseBee 格式;CLI download 命令支持下载到大装置 AOSS;CLI upload 命令支持其他常用 OSS(amazon,阿里,百度,华为等);Web 端支持导出数据 & 从常用 OSS 导入数据。 | 2023-11-30 |
| 数据管理平台 GA 版 v1.9.0 | 数据集授权优化,支持对数据集一次性授权和用户名模糊匹配;下线 AIDMP 的试用版,减少用户的概念混淆; OpenAPI 的数据导入和导出的接口优化。 | 2023-12-30 |
| 数据管理平台 GA 版 v1.10.0 | 对数据集授权优化,支持对用户组授权,以及增加数据预览的角色权限。对数据空间进行展示优化,便于用户更方便跨数据空间使用数据集。支持对数据空间的缩容操作,使用户能够更有效地管理其资源容量。 | 2024-1-30 |
| 数据管理平台 GA 版 v1.11.0 | 支持新增数据集纳管 AOSS 数据,提供更广泛的数据来源集成。优化 json、jsonl、tsv、csv等文件的可视化展示,使用户更容易理解和分析这些格式的数据。数据集列表页优化,并且支持数据集给全体员工授权。 | 2024-3-10 |
常见问题
Q1:CLI或者Web上传Annotation_config.json文件过程中报错,应该如何处理?
A1:在上传标注配置文件Annotation_config.json过程中,系统会校验配置文件是否正确,如果配置不正确会给出相应的提示,常见的错误如下
| 报错信息 | 问题原因 |
|---|---|
| Annotation_name “xxx” is repeated, please check and resubmit | 标注配置文件Annotation_config.json中,存在同名的标注单元名称,也就是annotation_name重复 |
| Media_path “xxx” does not exist, please check and resubmit | 标注配置文件Annotation_config.json中,配置的媒体文件路径Media_path不存在,需要检查路径是否有效 |
| Annotation_path “xxx” does not exist, please check and resubmit. | 标注配置文件Annotation_config.json中,配置的标注文件路径annotation_path不存在,需要检查路径是否有效 |
| Annotation_path “xxx” is repeated, please check and resubmit | 标注配置文件Annotation_config.json中,配置的标注文件路径annotation_path重复,需要检查每个标注单元的annotation_path是否唯一 |
| Annotation_format “xxx” can not be recognized, please check and resubmit. Currently supported: "COCO",“SenseBee” | 目前标注可视化支持COCO格式和 SenseBee 格式,因此Annotation_format必须为 “COCO” 和 “SenseBee”,并且区分大小写 |
| Annotation_config.json error, please check and resubmit | 标注配置文件Annotation_config.json格式不合法,存在语法错误 |
| Annotation_config.json 校验不通过,请检查后重新提交 | 标注配置文件Annotation_config.json格式不合法,存在语法错误 |
Q2:如何续费数据管理平台的数据空间?以及如何退订数据管理平台的数据空间?
A2:在正常使用期、宽限期和保留期,用户可以通过费用-订单管理-续订管理界面发起续订,并在续订管理查看产品有效时间,
在正常使用期,用户可以通过费用-订单管理-退订管理界面发起退订,退订后,数据管理平台的数据空间将会立即删除,
Q3:资源超量使用后,数据管理平台的数据空间会怎么样?是否可以将数据空间转移资源给到其他部门进行管理?
A3:资源超量使用后,数据管理平台的数据空间无法正常使用,请尽快扩容相应的资源,可以在数据管理平台的首页,点击资源扩缩管理,可以对相应资源进行扩容,同时也能够支持缩容。
可以进行数据空间的资源转移,, 找到相应数据空间的所在资源,点击详情,可以编辑修改其所在的资源组。请注意,修改到其他资源组之后,先前的数据空间的数据仍然保留,相应的数据权限则需要重新分发。
Q4:可以使用 AI 缓存服务加速数据集的 SDK 读取吗?
A4:可以的。您既可以使用 AI 缓存服务加速数据管理平台的所有数据集,也可以使用 AI 缓存服务加速数据管理平台的指定数据集。通过系统配置,可以查看数据管理平台的所有数据集的存储桶信息,进而前往 AI 缓存服务加速所有的存储桶。通过数据集设置,查看数据集的存储信息,可以查看指定数据集的存储桶信息和存储路径,进而前往 AI 缓存服务加速指定的存储路径。
Q5:对数据集的操作是否有相应的审计记录?
A5:对 数据管理平台的每一步操作都会有相应的审计记录,可以前往云审计界面查看对于数据集的各种操作,包括 Web 端、CLI 和 SDK 的相关操作,。