模型评测
简介
模型评测是模型开发过程中的重要环节之一,涉及对训练好的模型进行性能评估和验证的过程。模型评测的目的是确定模型在特定任务上的有效性、准确性、泛化能力以及适用性。
为什么需要模型评测
- 验证模型精调的效果:引入特定数据集精调后的模型,理论上在特定领域具备更强大的性能,但需要实际检验能力的提升,确保满足特定业务的能力需要。
- 预防模型精调带来的潜在风险:精调后的模型,在学习过程中可能会存在通用能力的退化或其他风险,通过评测可以提早发现这些潜在风险。
使用指南
一、模型评测前准备
准备评测数据:
- 模型评测前需要准备对应的评测数据集,通常为对话形式,目前支持OpenAI格式
已训练好待评测的模型
- 模型精调可具体参考模型精调
二、评测任务管理
- 创建任务:
- 进入“万象模型开发平台 ModelStudio”模块,点击“模型评测”,进入模型评测任务列表。
- 点击“创建评测”
- 填写任务名称、描述,选择待评测的模型,选择/上传评测数据,确认后创建模型评测任务。
- 目前仅支持OpenAI格式的数据,支持json、jsonl的文件,具体示例如下:
[
{
"messages": [
{
"role": "system",
"content": "你是一个无所不知,无所不晓的AI助手"
},
{
"role": "user",
"content": "请介绍下文艺复兴"
},
{
"role": "assistant",
"content": "文艺复兴时期是一个关于艺术、文化和学术的复兴运动。"
}
]
}
]{"messages": [{"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "请介绍下文艺复兴?"}, {"role": "assistant", "content": "文艺复兴时期是一个关于艺术、文化和学术的复兴运动。"},{"role": "user", "content": "那雕塑方面如何呢?"}, {"role": "assistant", "content": "文艺复兴时期的雕塑也非常有名,几位世界级的雕塑大师都出自于这个时期"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "请介绍下文艺复兴?"}, {"role": "assistant", "content": "文艺复兴时期是一个关于艺术、文化和学术的复兴运动。"},{"role": "user", "content": "那雕塑方面如何呢?"}, {"role": "assistant", "content": "文艺复兴时期的雕塑也非常有名,几位世界级的雕塑大师都出自于这个时期"}]}

评测指标:
- 评测指标展示了模型在评测数据集上的性能表现,主要分为以下:
指标名称 指标说明 BLEU-4 (%) 用于评估模型生成的句子和实际句子的差异的指标,以unigram,bigram,trigram,4-grams的加权平均 ROUGE-1 (%) 将模型生成的结果和标准结果按unigram(单个单词)拆分后,计算出的召回率 ROUGE-2 (%) 将模型生成的结果和标准结果按bigram(连续成对的单词)拆分后,计算出的召回率 ROUGE-L (%) 将模型生成的结果和标准结果按LCS(最长公共子序列,两个序列中顺序相同的最长公共子序列)拆分后,计算出的召回率

任务详情:
- 在模型评测任务列表页面,点击某个任务名称,可进入任务详情。
- 任务详情主要展示了评测任务详情,包括任务名称、关联的精调任务名称、基模型名称、评测数据等信息。
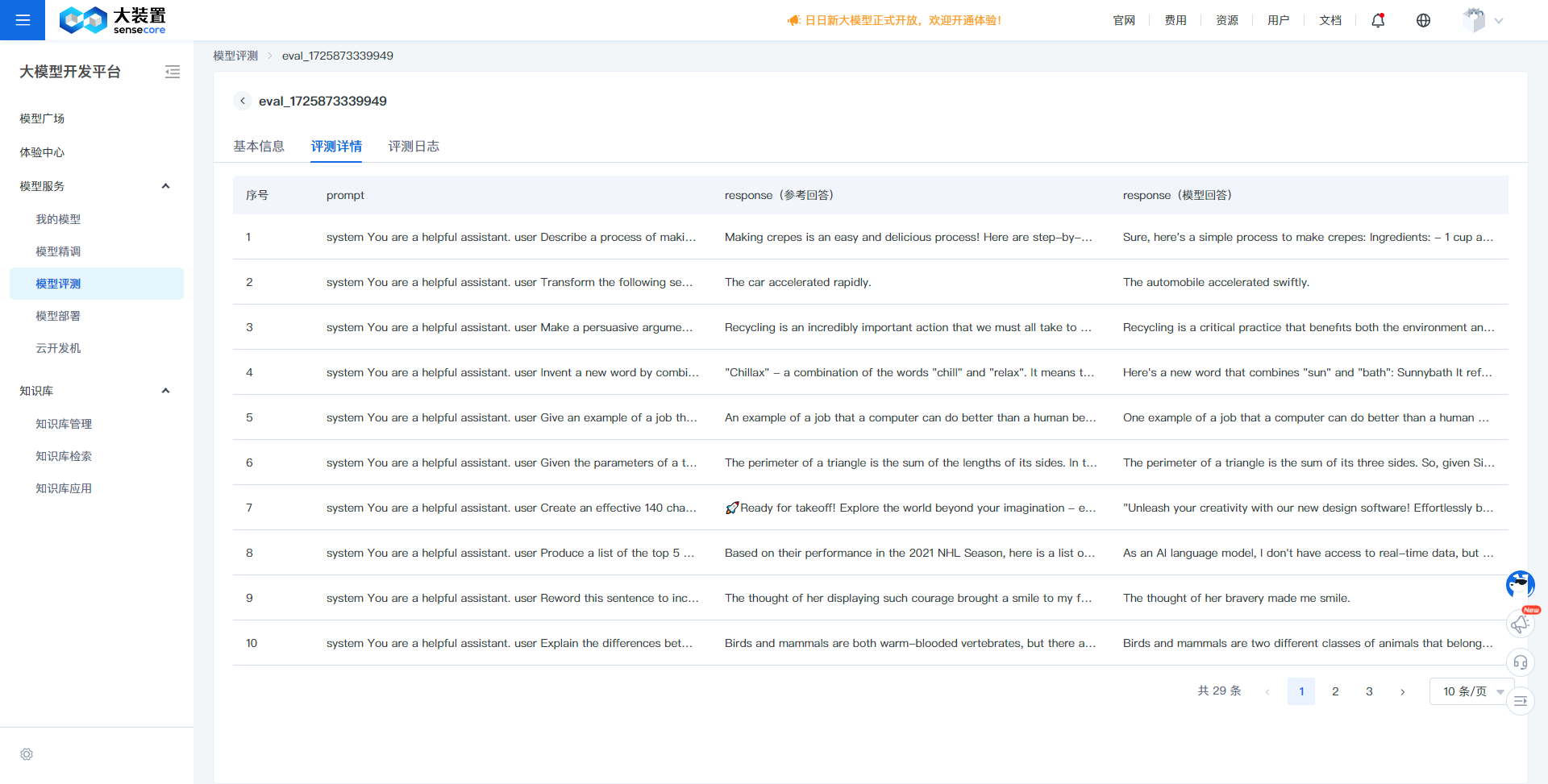
评测详情:
- 评测详情展示了评测过程中模型输出的回答与原始评测数据集的对比情况,分为prompt、response(参考回答)、response(模型回答),对比response(参考回答)、response(模型回答)的内容,可实际看出模型效果的差异
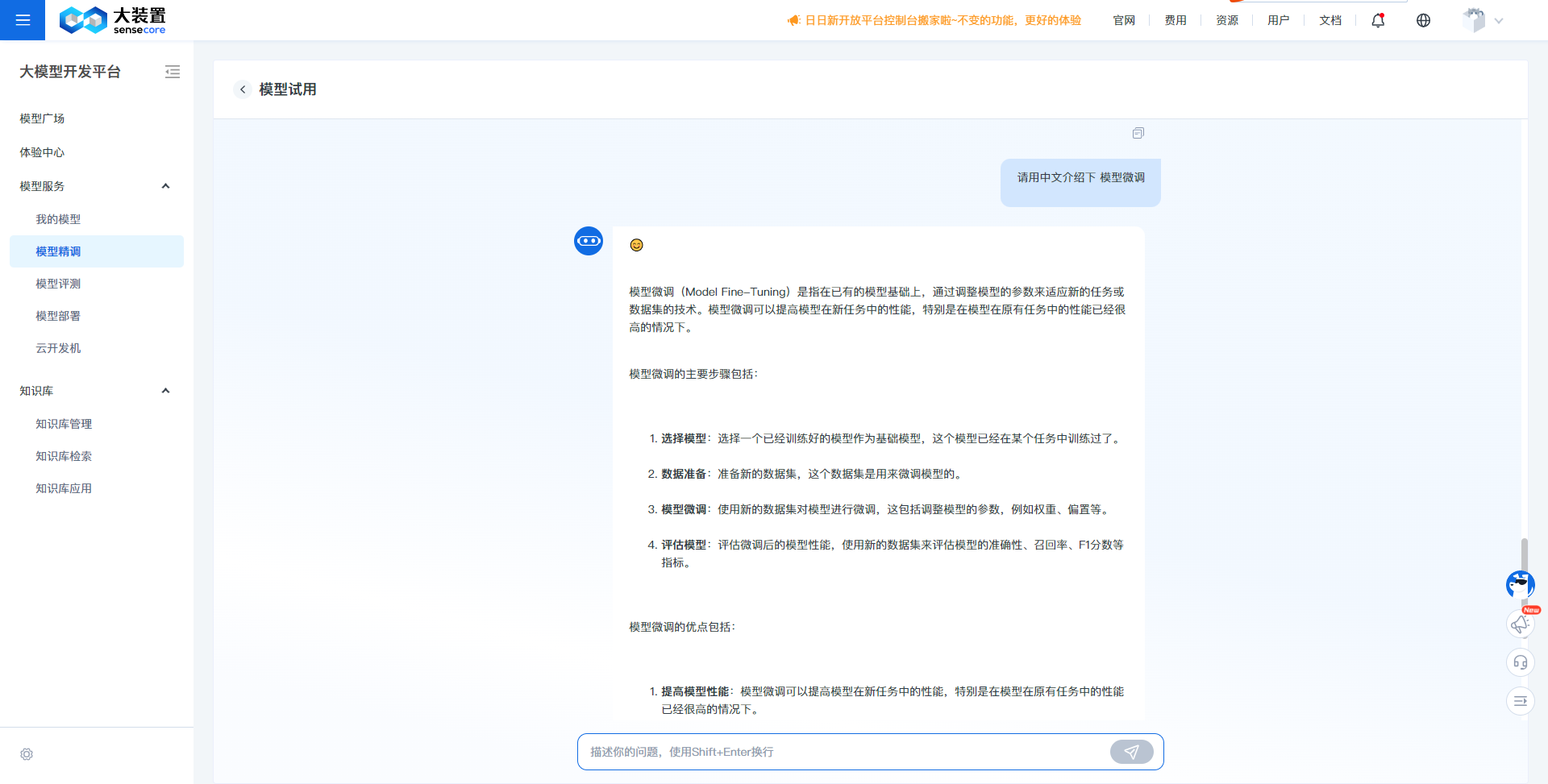
模型试用:
- 通过模型试用,可快速与精调后的模型对话,体验精调后模型的效果,辅助判断模型是否满足特定场景的需求
评测日志:
- 评测日志展示了评测过程中的详细信息,可定位追踪评测过程中的异常