模型精调最佳实践
为什么需要模型微调
- 领域知识学习:通用大模型在某些特定的垂直领域的知识不足时,会容易出现幻觉,生成虚假或者不相关的信息,而如何让模型增强对特定领域的泛化能力,微调就是很快捷有效的方式之一。
- 定制化功能:赋予大模型更加定制化的功能。通用模型虽然能力强大,但在特定任务可能表现不佳。通过微调,可以使模型更好地适应特定任务的需求和特征。
- 低成本部署:部署一个较大参数的模型需要耗费大量的资源,且由于资源限制,模型响应时间也不可控,而通过微调,使用较小参数的模型也可以达到预期的效果,从而减少资源消耗,降低模型响应时延。 当然,很多任务通过prompt工程或RAG也可以很好的解决,但如果你需要调整模型的输出行为、输出风格、融入领域知识、低成本的部署,那微调仍然不可或缺。
模型精调主要场景
- 拟人对话:需要固定风格的回答和文体,如角色扮演。
- 意图识别:需要根据上下文识别用户意图,大模型无法知晓判断依据,用特定数据训练可高效完成用户意图的识别,如智能语音助手、智能搜索。
- 复杂任务:需要处理较复杂的任务,难以通过 Prompt 或者知识库的方式实现,如从海量信息中抽取结构化信息。
- 工具调用:基础大模型具有标准的functioncall能力,特定场景functionCall效果不稳定,如:企业OA助理
- 数据标注:需要大量数据标注的任务,人力成本过高,可以训练特定领域模型进行标注。
模型精调使用步骤
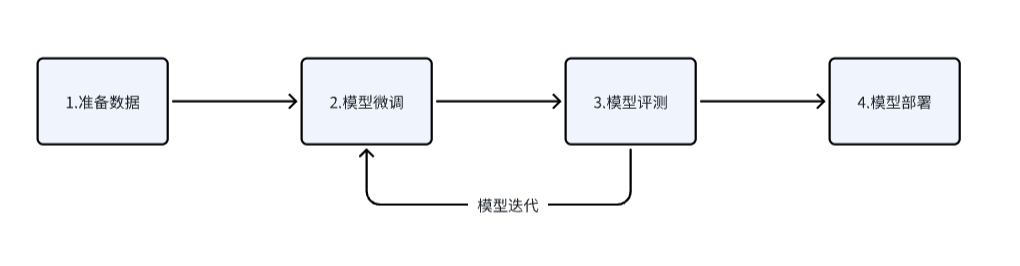
场景示例
以下,就以 角色扮演 为例,介绍如何高效使用微调 场景介绍:开发一个 智能助手,该助手定位是一个古代医术高明的江湖医生,需要以武侠风格的回答使用者提问。
数据准备
在训练开始前,需要准备好精调所需的数据集,数据集根据模型大小而变化,通常,对于20B以下的模型,需要准备1000条左右的标注数据。此处,系统已预置好示例场景的数据:

模型精调
在训练前,还需要选择合适的模型,适当的训练方法,对于提高模型性能非常重要。
a. 选择模型
根据场景不同,需要处理的文本长度也有差异,选择合适的模型能够处理特定长度的文本,若选择了文本长度较小的模型,而实际需要处理大文本,则模型整体性能会较差。比如:- 如果数据集长度(95%以上)在4k以内:考虑使用4k模型并进行SFT微调;
- 如果超过4k的数据较多(20%以上)或需长文本处理:使用8k版本模型进行微调。
b. 训练方法
微调方法分为全参微调、Lora、P-Tuning、Prefix-Tuning等多种微调方法,但从性能、效率、数据量等多方面考虑,Lora使用更为广泛c. 超参配置
EPOCH:根据数据规模适当调整EPOCH大小,比如100条数据时, Epoch为15,1000条数据时, Epoch为10,10000条数据时, Epoch为2。
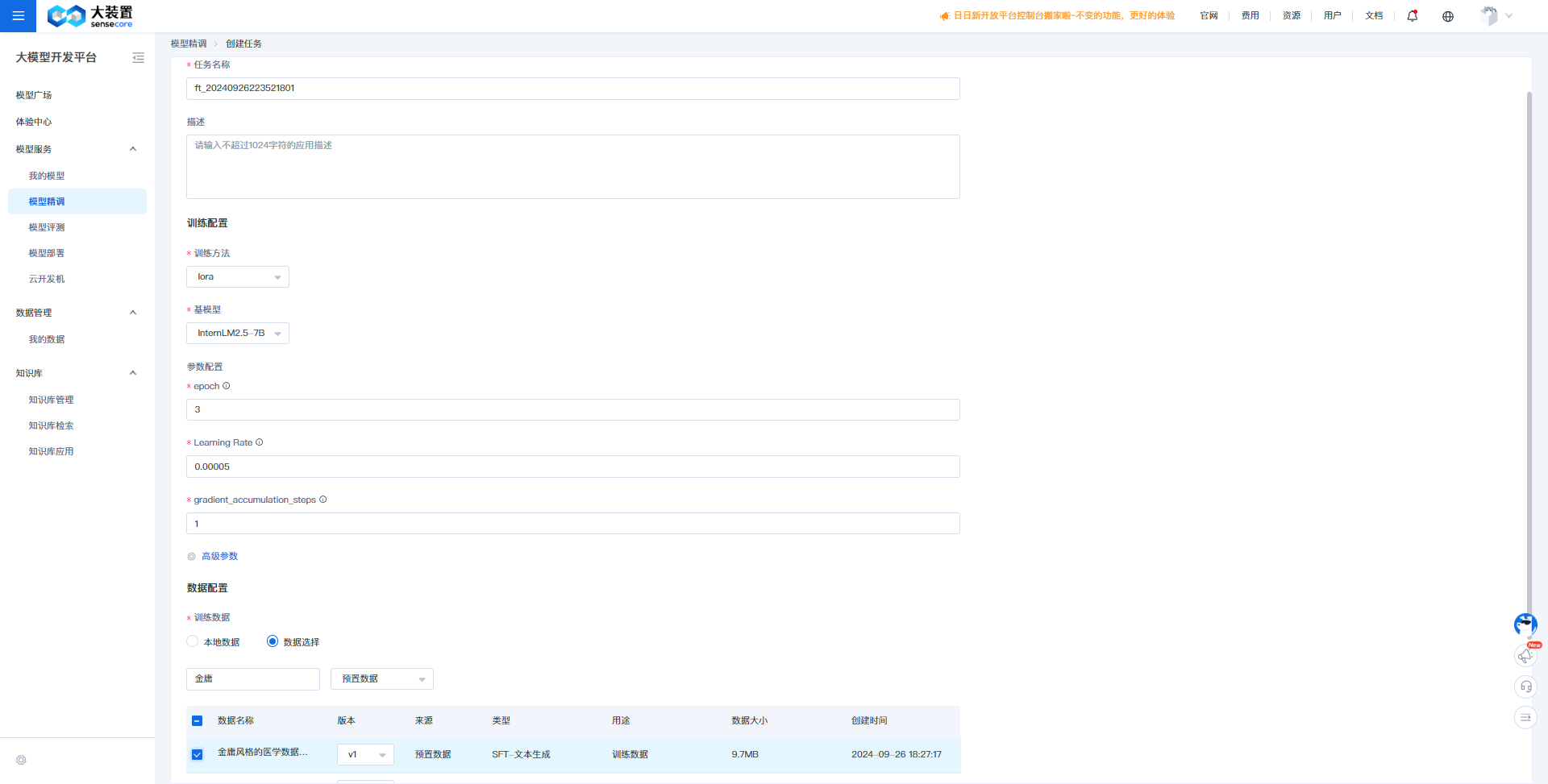
LearningRate:是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,如果没有专业的调优经验,推荐使用默认值。基于以上,我们创建精调任务的准备工作已完成,具体创建步骤如下:
- 进入“大模型开发平台AI Studio”模块,点击“模型精调”,进入模型精调任务列表。
- 点击“创建任务”
- 填写任务名称、描述,选择训练方法和基模型,调整超参数,选择/上传训练数据,确认后创建模型精调任务。
训练过程查看
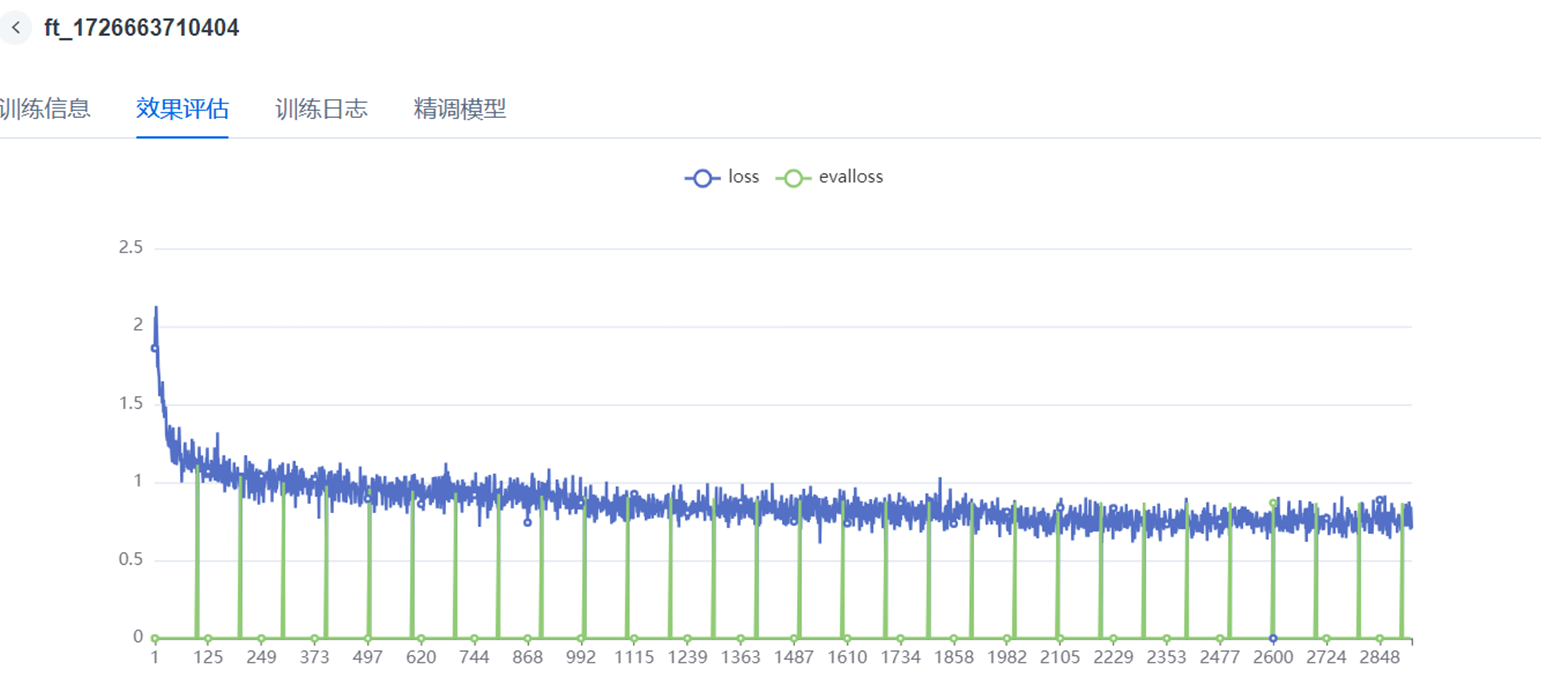
在训练过程中,会根据训练过程中每个step的loss值,绘制Training loss的收敛曲线,成功的训练一般有明显的收敛过程。
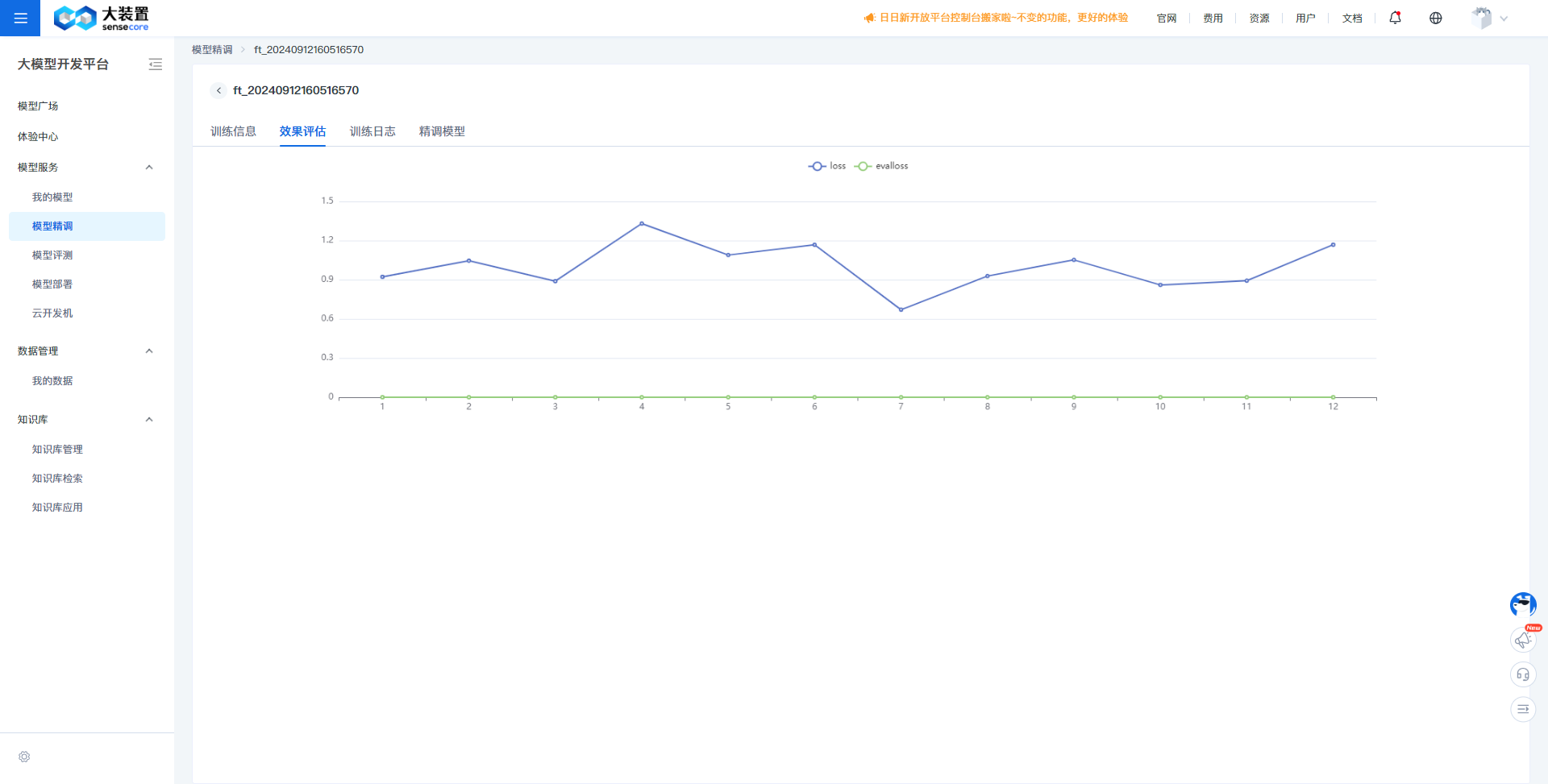
a. 若没有明显收敛,说明训练不充分,可以增加训练epoch重训,或者进行增量训练。
b. 若过早收敛,而后部分的loss平稳无变化,说明可能有过拟合,可以结合eval-loss,若两者差值较大,则说明可能过拟合,选择是否减少epoch重训。
c. 若有收敛趋势,但没有趋于平稳,可以在权衡通用能力和专业能力的前提下考虑是否增加epoch和数据以提升专业能力,但会有通用能力衰减的风险。
较好的收敛:
 过拟合:
过拟合:
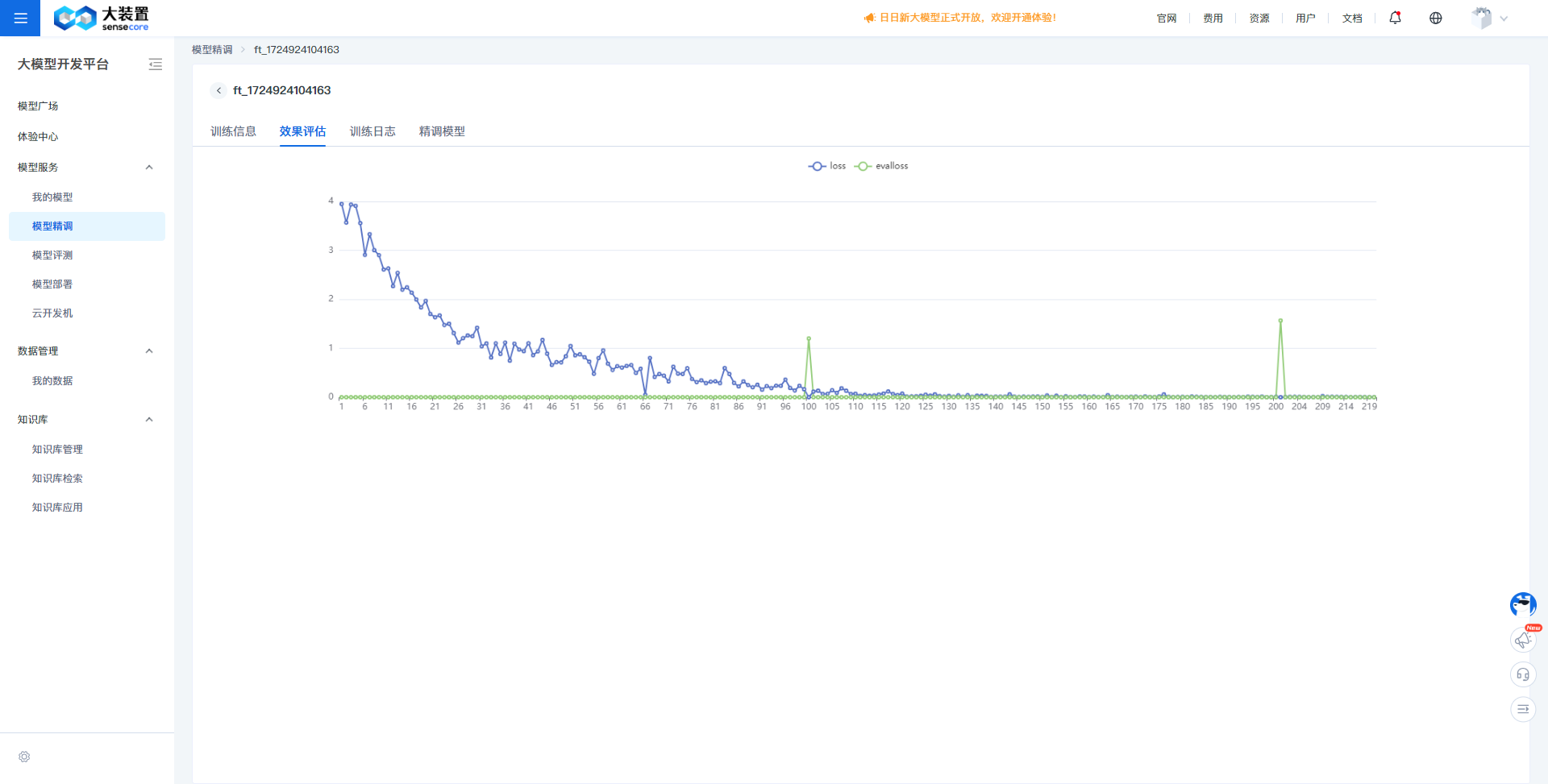 未收敛:
未收敛:
模型评测
训练完成后,需要进行模型评测,以确定模型在特定任务上的有效性、准确性、泛化能力以及适用性。
评估指标:
对于模型使用场景的不同,可以分为多种维度指标的评测,目前平台采用自动评测的方式,在通用维度上对模型进行评估,具体指标如下: | 指标名称 | 指标说明 |
| ----------------------- | ---------- | | BLEU-4 (%) | 用于评估模型生成的句子和实际句子的差异的指标,以unigram,bigram,trigram,4-grams的加权平均 | | ROUGE-1 (%) | 将模型生成的结果和标准结果按unigram(单个单词)拆分后,计算出的召回率 | | ROUGE-2 (%) | 将模型生成的结果和标准结果按bigram(连续成对的单词)拆分后,计算出的召回率 | | ROUGE-L (%) | 将模型生成的结果和标准结果按LCS(最长公共子序列,两个序列中顺序相同的最长公共子序列)拆分后,计算出的召回率 |模型对比:
选定测试集后,模型会在测试集上自动评估,输出精调后模型与基模型在测试集上的性能指标,同时,也可以进行多模型的对比,具体步骤如下:- 进入“大模型开发平台AI Studio”模块,点击“模型评测”,进入模型评测任务列表。
- 点击“创建评测”。
- 填写任务名称、描述,选择待评测的模型,选择/上传评测数据,确认后创建模型评测任务。
- 任务执行成功,点击列表中的“预览”,即可视化查看评估指标。
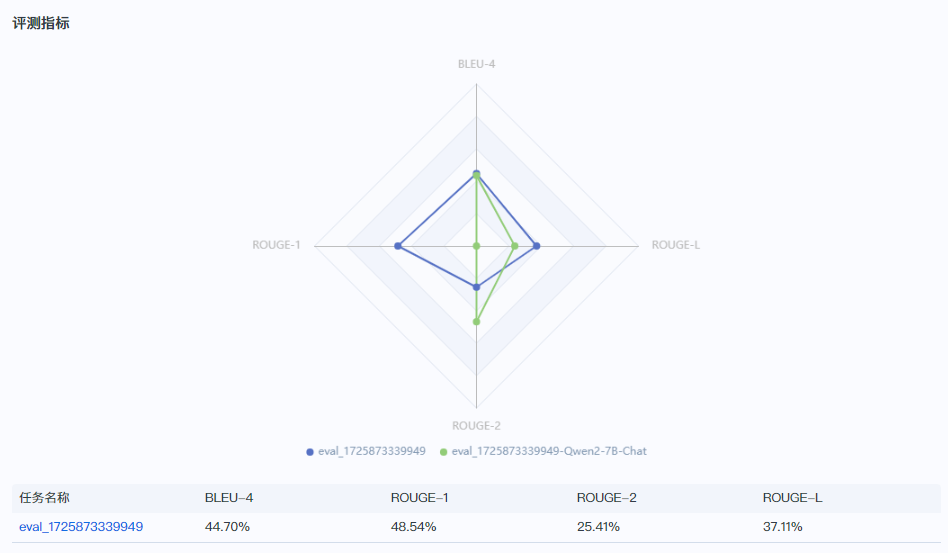
精调模型与基模型的对比:
对比精调后模型和基模型,在精调后的模型在ROUGE-1和ROUGE-L上有较大的提升,还需结合试用效果具体判断是否满足需要。
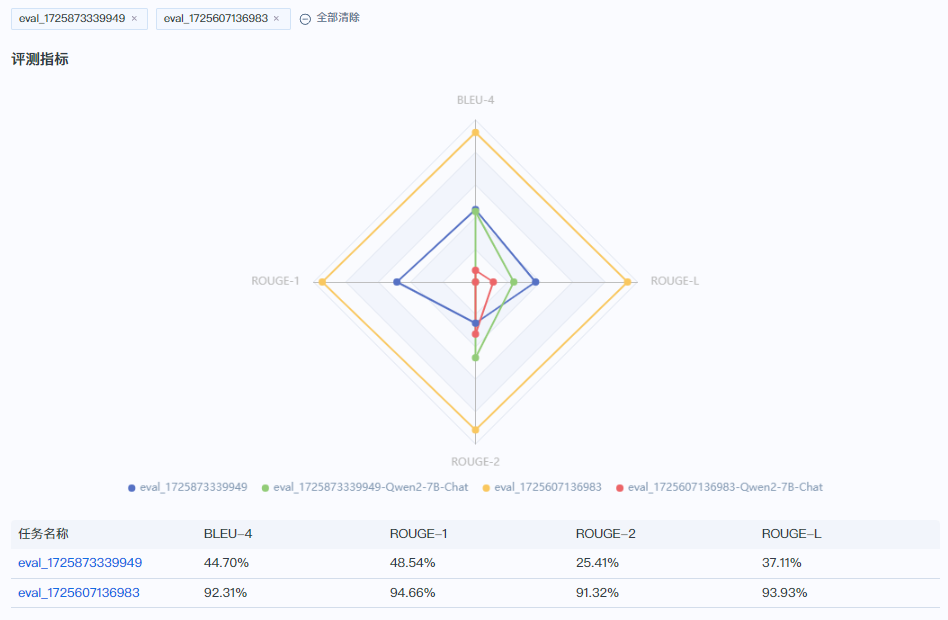
多个模型之前的对比:
两个模型在测试集上有较大的性能差异,黄色在各维度上明显优于蓝色,若测试集数据分布合理,说明黄色代表的精调模型要远优于蓝色代表的精调模型。
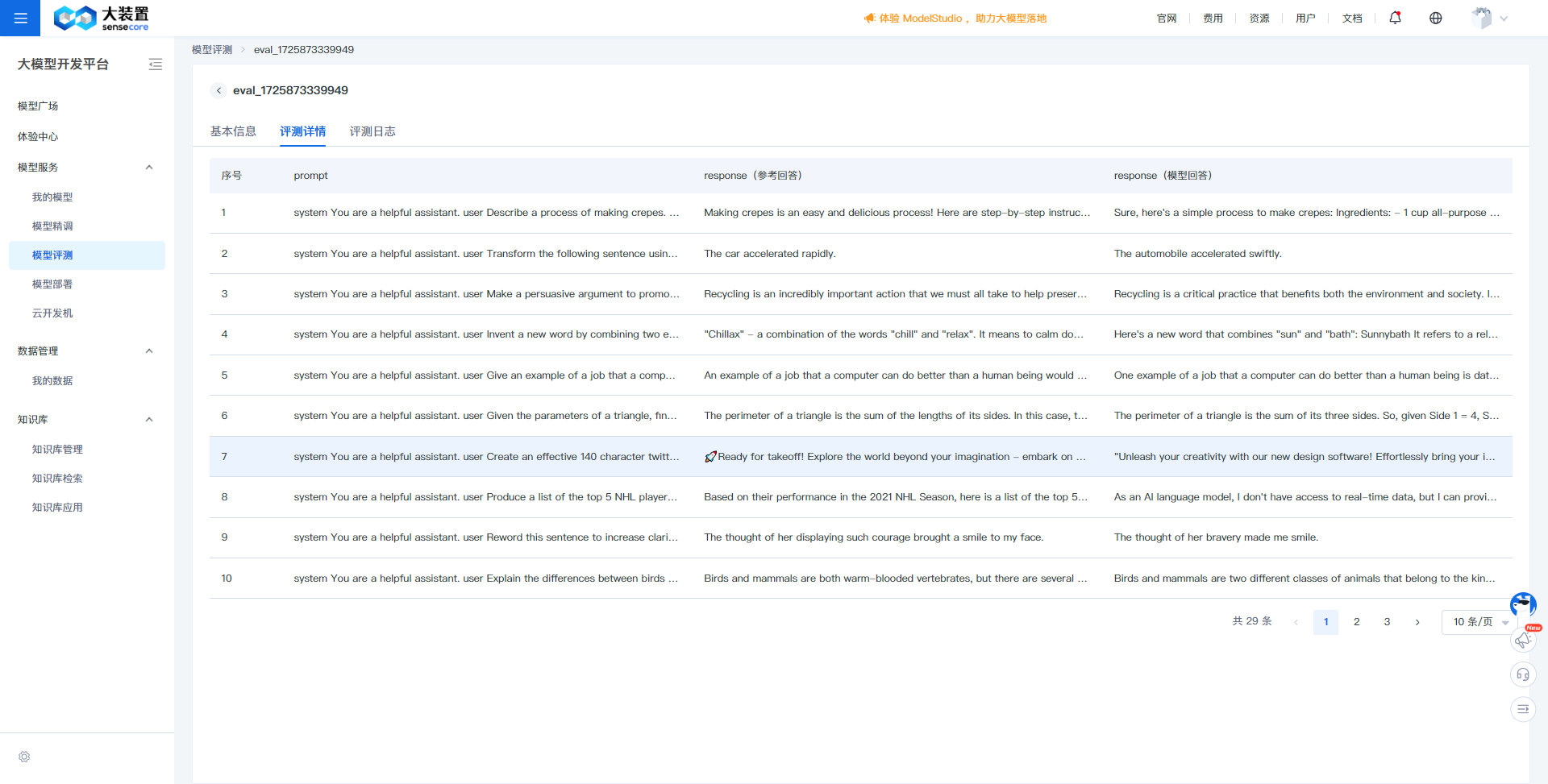
评测详情:
评测详情展示了评测过程中模型输出的回答与原始评测数据集的对比情况,分为prompt、response(参考回答)、response(模型回答),对比response(参考回答)、response(模型回答)的内容,可实际看出模型效果的差异
模型试用:
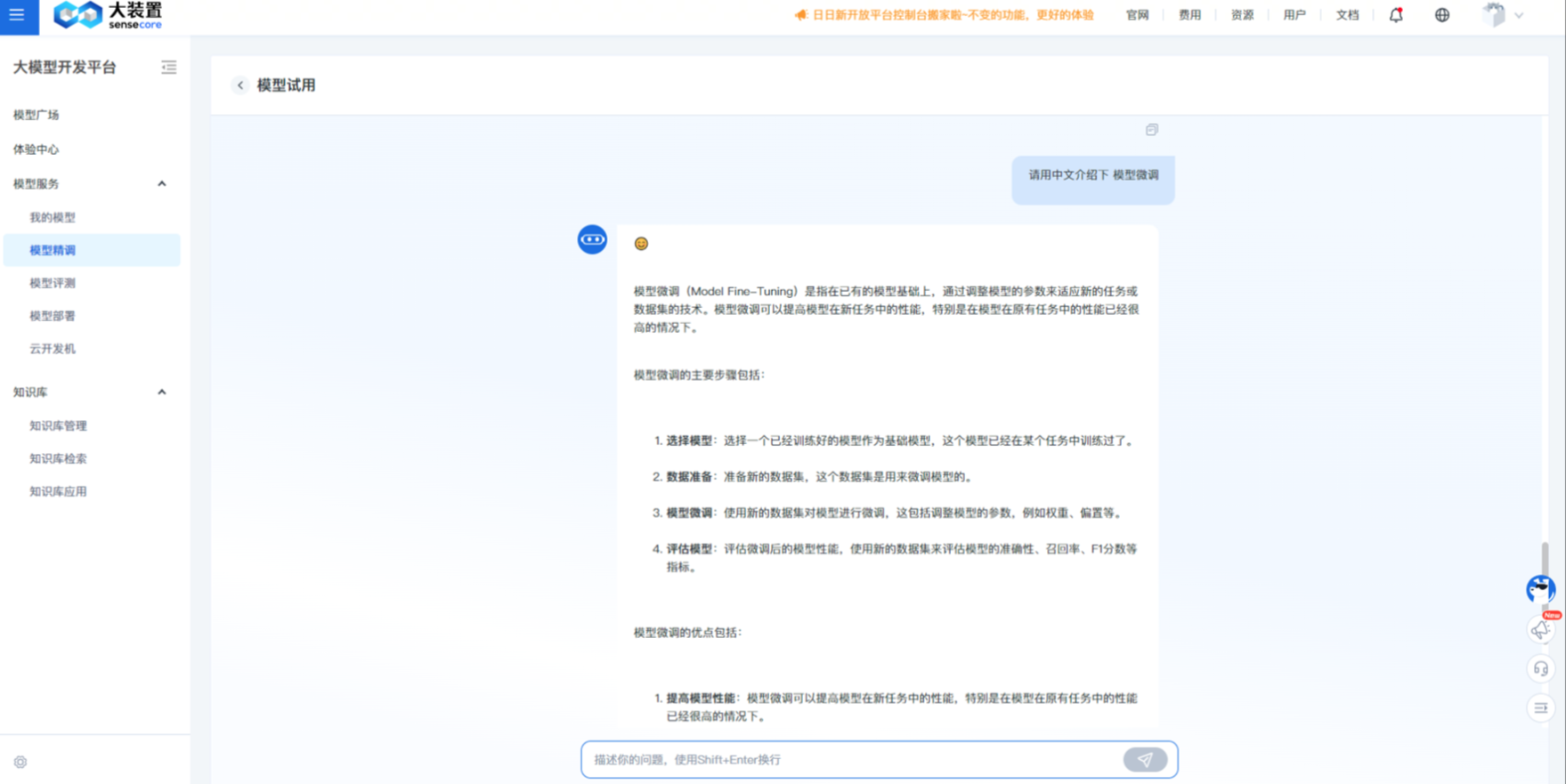
通过模型试用,可快速与精调后的模型对话,体验精调后模型的效果,辅助判断模型是否满足特定场景的需求
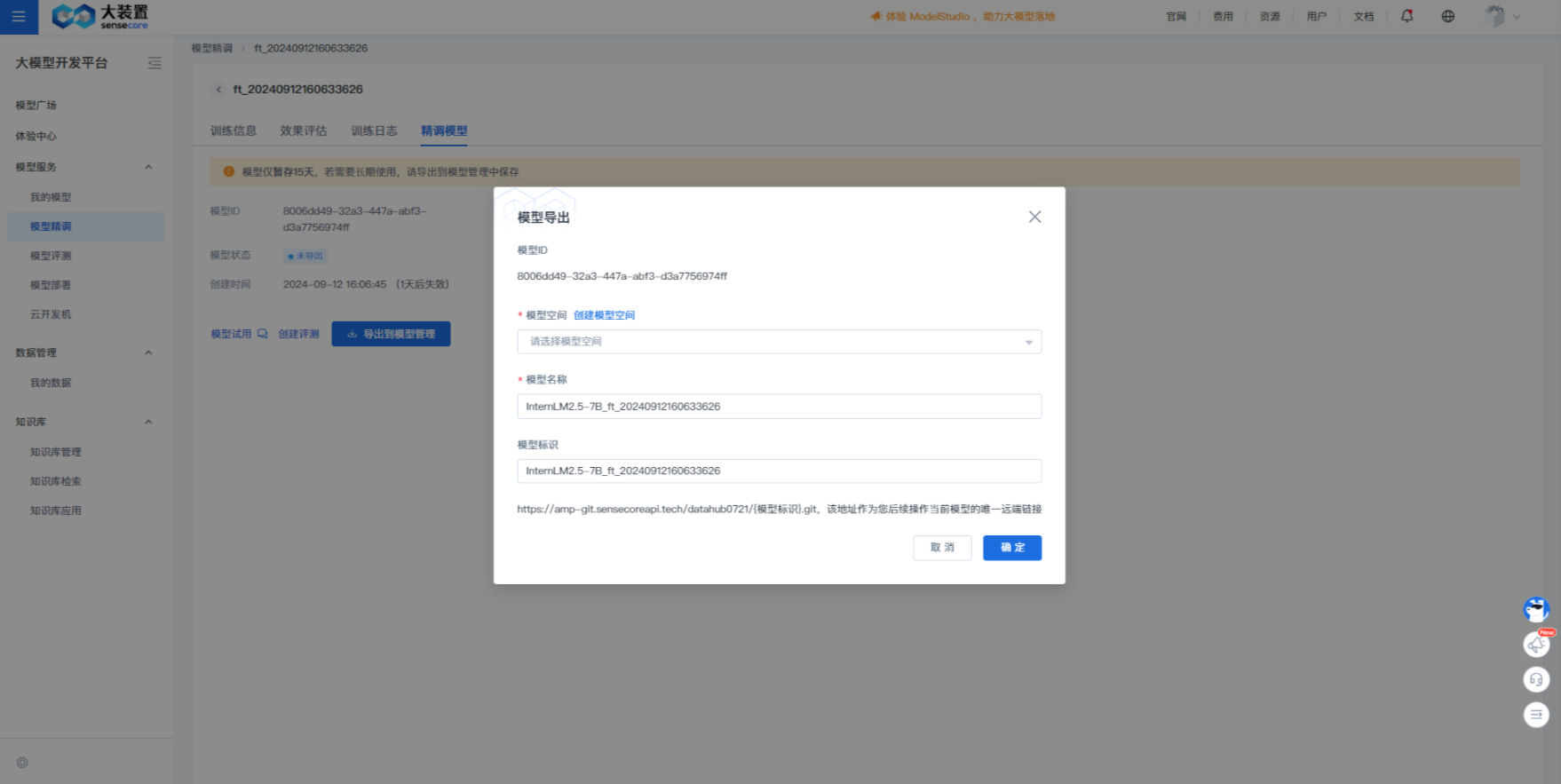
模型导出&使用
通过以上评测过程,结合训练过程Training loss的收敛曲线,可以确定性能较好的精调模型,若需要将模型投入实际的业务生产中,则需要将模型导出到模型管理平台进行推理部署。具体步骤如下:
a. 进入“模型精调”详情,点击“精调模型”的tab
b. 点击“导出到模型管理”,填写具体信息,提交导出任务,直至导出成功
c. 导出成功后,进入“我的模型”中查看已导出的模型,点击“一键部署”
d. 至此,就完成一次从模型精调到推理部署的全流程