模型管理
您需要经历 “创建模型空间 -> 生成密钥 -> 创建模型 -> 操作模型文件” 四个步骤来完成一次完整的快速入门体验。
1.创建模型空间
模型空间是您需要经过购买配额用于存储模型的空间。
(1)创建前准备
请确保您有AI模型空间创建者权限,请参考如何为用户授权,需要租户管理员为您添加AI模型空间创建者角色。
(2)创建模型空间
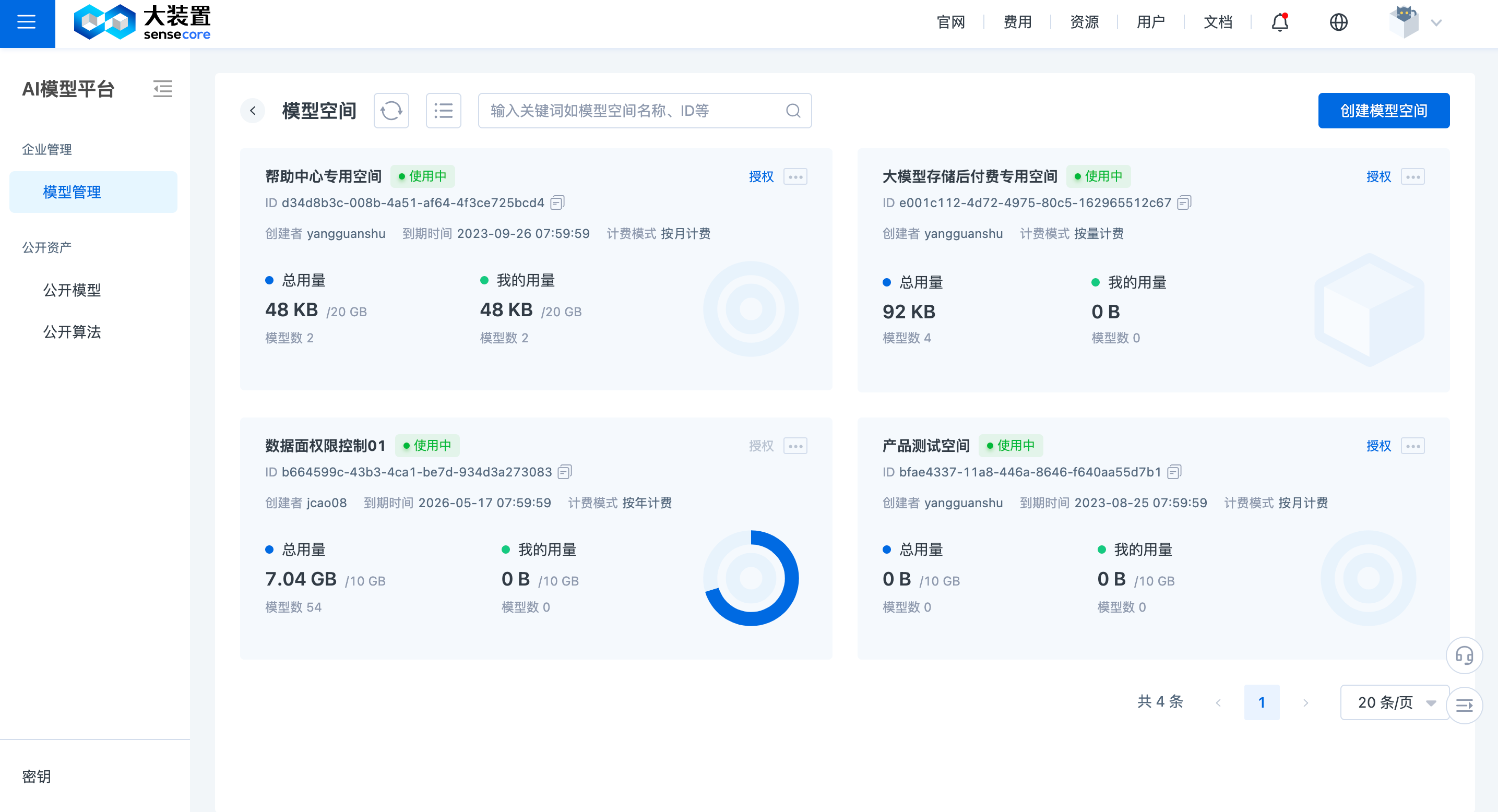
具有创建者权限后,在模型管理页面右上角点击【模型空间】,进入模型空间管理页面。
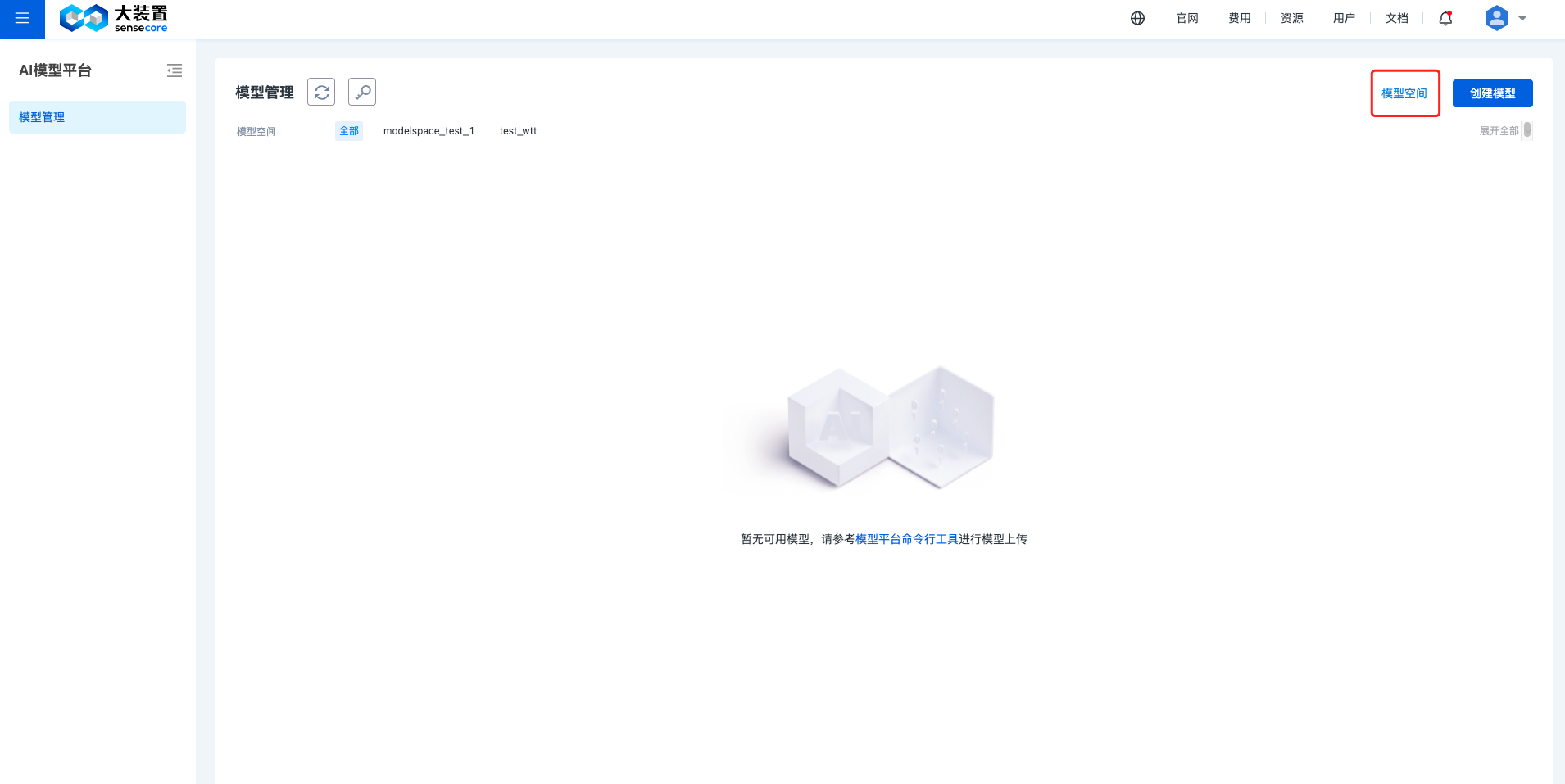
在模型空间管理页面右上角点击【创建模型空间】进入下单页。
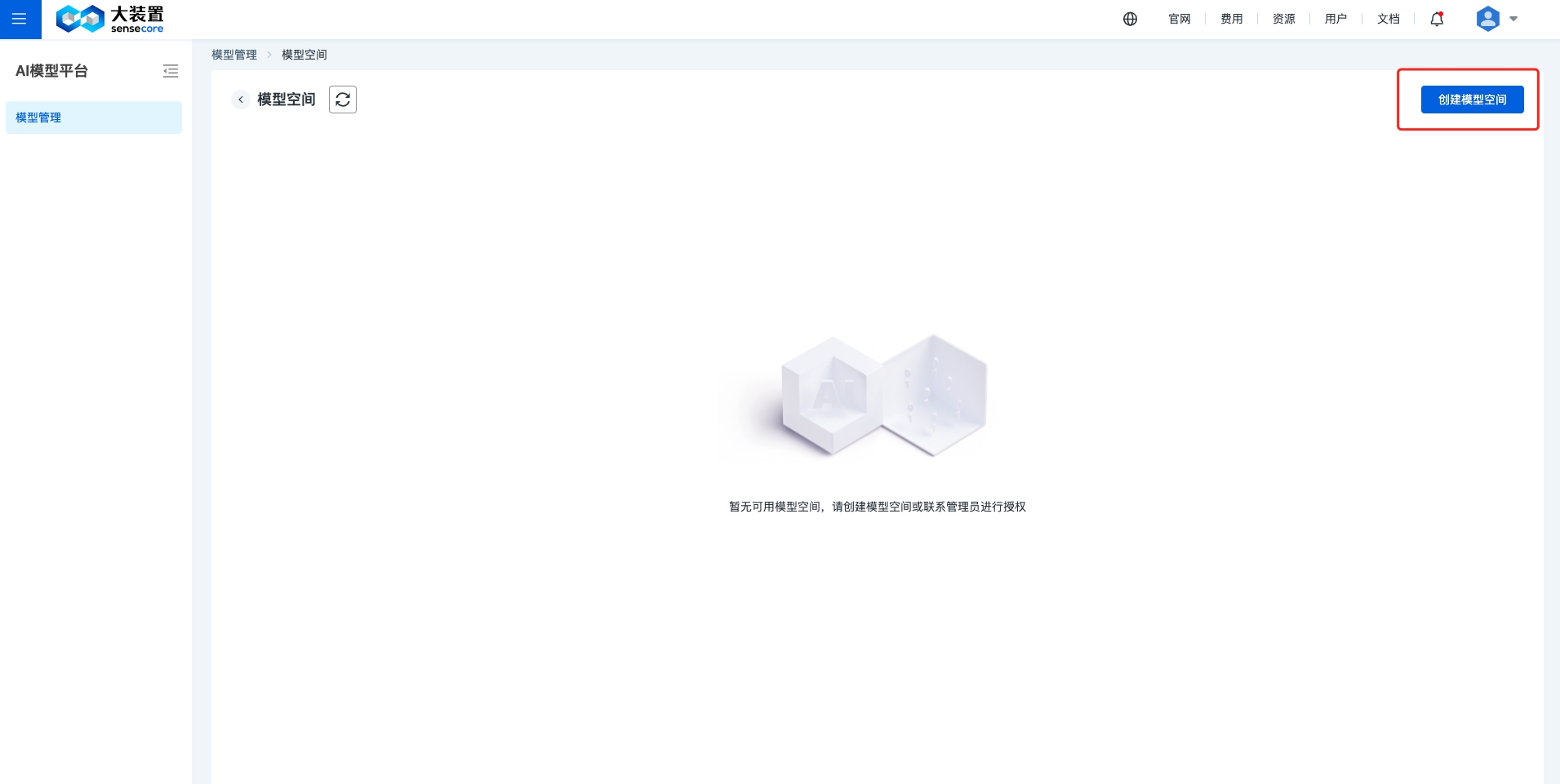
- 计费模式: 可选择按月计费/按年计费/按量计费。
- 版本选择: 选择“付费版”
- 存储配额: 最小购买单位为 10GB,可切换单位为TB/PB进行购买。
- 基本信息-模型空间名称: 输入模型空间名称,如“大语言模型专项空间”
点击【立即购买】即可成功创建模型空间并自动跳转到模型管理页面,便于直接进行模型创建。
(3) 模型空间总览
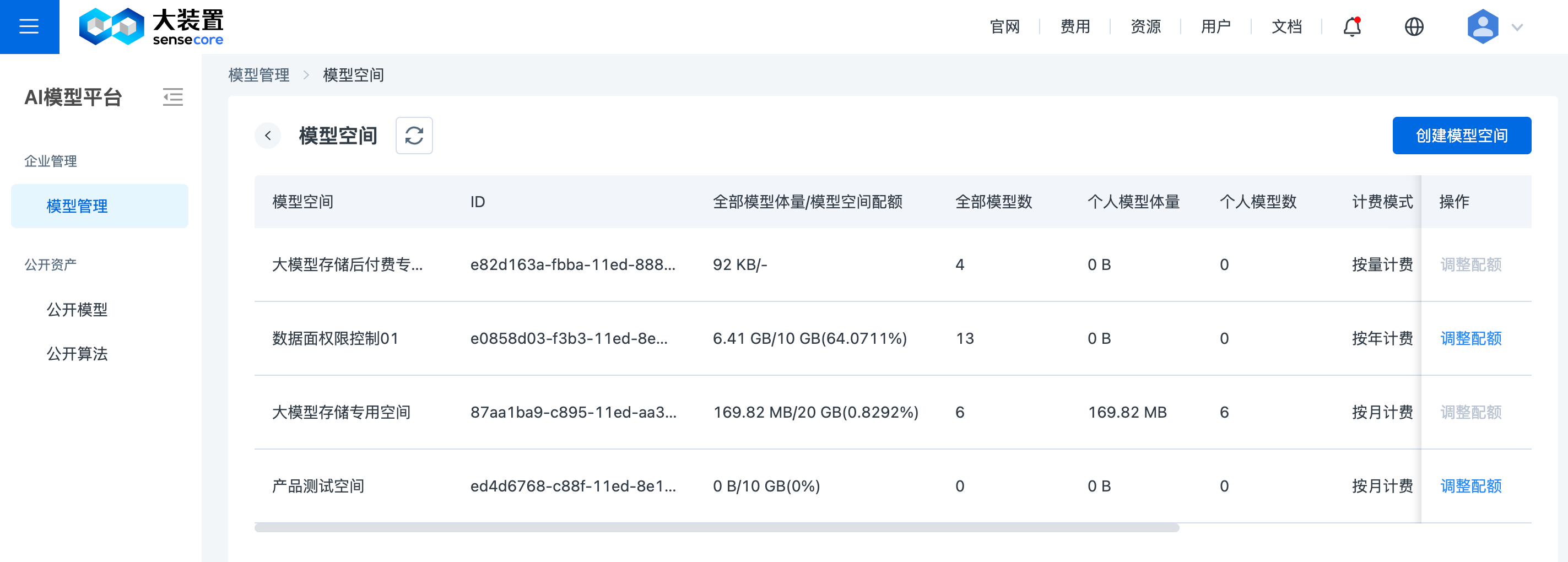
在模型管理页面右上角点击【模型空间】,进入模型空间管理页面,可显示您有权使用的模型空间列表,字段说明如下:
- 模型空间: 显示创建时指定的模型空间名称。
- ID: 系统自动生成用于唯一标识模型空间的ID
- 全部模型体量/模型空间配额: 显示当前空间内所有用户使用的总存储大小/空间总配额
- 全部模型数: 显示当前空间内所有用户创建的模型总数
- 个人模型体量: 显示当前空间内登陆用户使用的总存储大小
- 个人模型数: 显示当前空间内登陆用户创建的模型总数
- 计费模式: 显示当前模型空间订单的计费模式,即“按月计费”/“按年计费”/“按量计费”
- 状态: 显示当前模型空间订单状态,即“使用中”/“宽限期”/“保留期”
- 到期时间: 显示当前模型空间订单到期时间
- 创建者: 显示创建该空间的用户名称
(4)模型空间授权
当您为某一具体模型空间实例的拥有者/维护者时,您可以对模型空间进行管理。
- 授权: 将当前模型空间授权给其他用户使用或管理。具体角色说明详见权限设置
- 调整配额: 修改当前模型空间的容量大小,仅预付费模式支持。
- 续订: 延长当前模型空间的使用期限,仅预付费模式支持。
- 退订: 退订并释放空间资源。
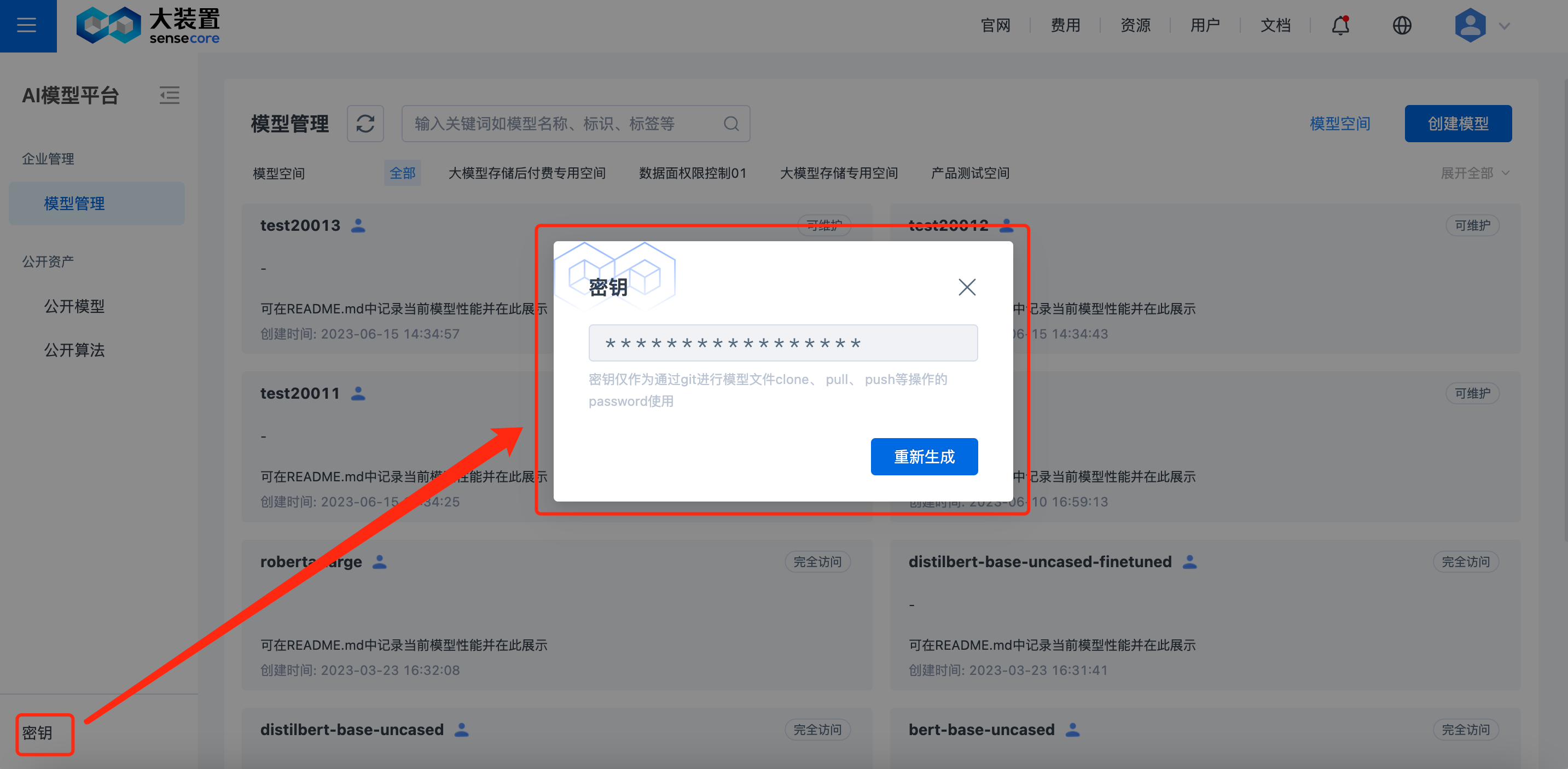
2.生成密钥
密钥是您用于通过git cli操作模型文件时唯一鉴权凭证,请妥善保管。
点击左侧导航栏下方的【密钥】弹出弹窗,点击【生成】可将您的密钥下载到本地,一旦泄露或丢失可通过平台重新生成,历史密钥会立即失效。
3.创建模型
模型是您创建后可用于存储和管理模型文件的仓库,拥有唯一的远端地址。
点击模型管理页面右上角的【创建模型】可进入配置页面。
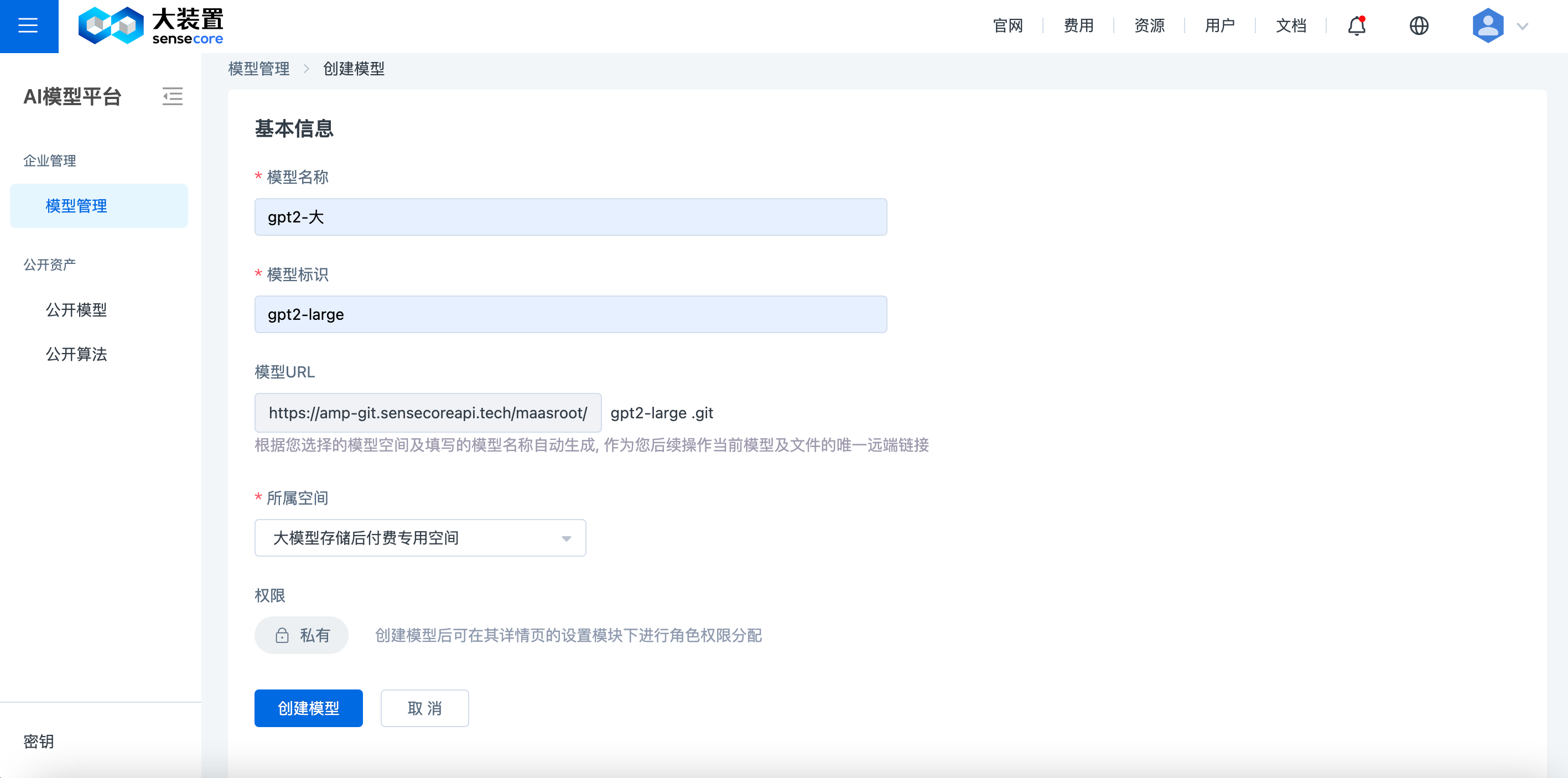
- 模型名称: 输入模型名称如“gpt2-大”,支持中文,用于模型名称显示,可通过名称进行模型检索。
- 模型标识: 输入模型标识如“gpt2-big”,不支持中文,用于模型远端地址生成,不可修改。
- 模型URL: 即模型远端地址,唯一且自动生成。
- 所属空间: 下拉选择有权限存储模型的模型空间。
- 权限: 模型创建成功后,可在其详情页的设置模块下进行角色权限分配。
点击【创建模型】进入该模型详情页,初始化时会自动创建 master 分支。
4.操作模型文件
您可通过原生git cli命令对模型文件进行上传,并在模型详情页对上传文件进行查看。
| 📣 Tips:您可点击模型详情部分的【如何操作模型】查看操作步骤提示。 |
(1)git clone
请确保您的电脑已经安装git,并准备任意本地文件夹作为clone模型的保存文件夹。 在模型平台前端可查看模型URL,点击【复制】

请使用您熟悉的命令行终端输入
$ git lfs install #安装lfs
$ git clone https://amp-git.sensecoreapi.dev/sensetime/gpt2-large.git #替换为您在创建模型时生成的模型url
按照提示输入步骤3中生成的密钥,clone成功后可在本地文件夹中查看初始化的文件列表。
| 📋 Notes:LFS 全称 Large File Storge,即大文件存储,是一个开源的 git 大文件版本控制的解决方案和工具集,可以用于管理比较大的文件。 |
(2)git push
| 📣 Tips:超过15M的模型文件需要使用lfs标记。更多关于lfs介绍可参考:https://git-lfs.com/ |
[可选] 当存在单个模型文件 > 4GB 时,需要先执行以下步骤,配置平台提供的自动分块工具
# 0. 环境确认: 请确保您已经安装 scoamp 工具, 安装方式 < pip install scoamp >
# 1. 进入模型目录:请确保您进入通过 git clone 获取的本地模型仓库目录下
cd <your-model-name>
# 2. 添加模型文件:在当前模型仓库下添加模型文件
# 3. 设置 lfs:设置后通过 git push 上传模型文件时,系统可以自动分块传输大文件
scoamp lfs setup .
再使用原生 git 命令上传模型文件即可。
$ git add . #添加当前目录下的所有文件到暂存区
$ git commit -m "first commit" #将暂存区内容提交到版本库
$ git push origin master #上传到远端合并
上传后在 web 上点击【刷新】文件列表,可查看模型文件。
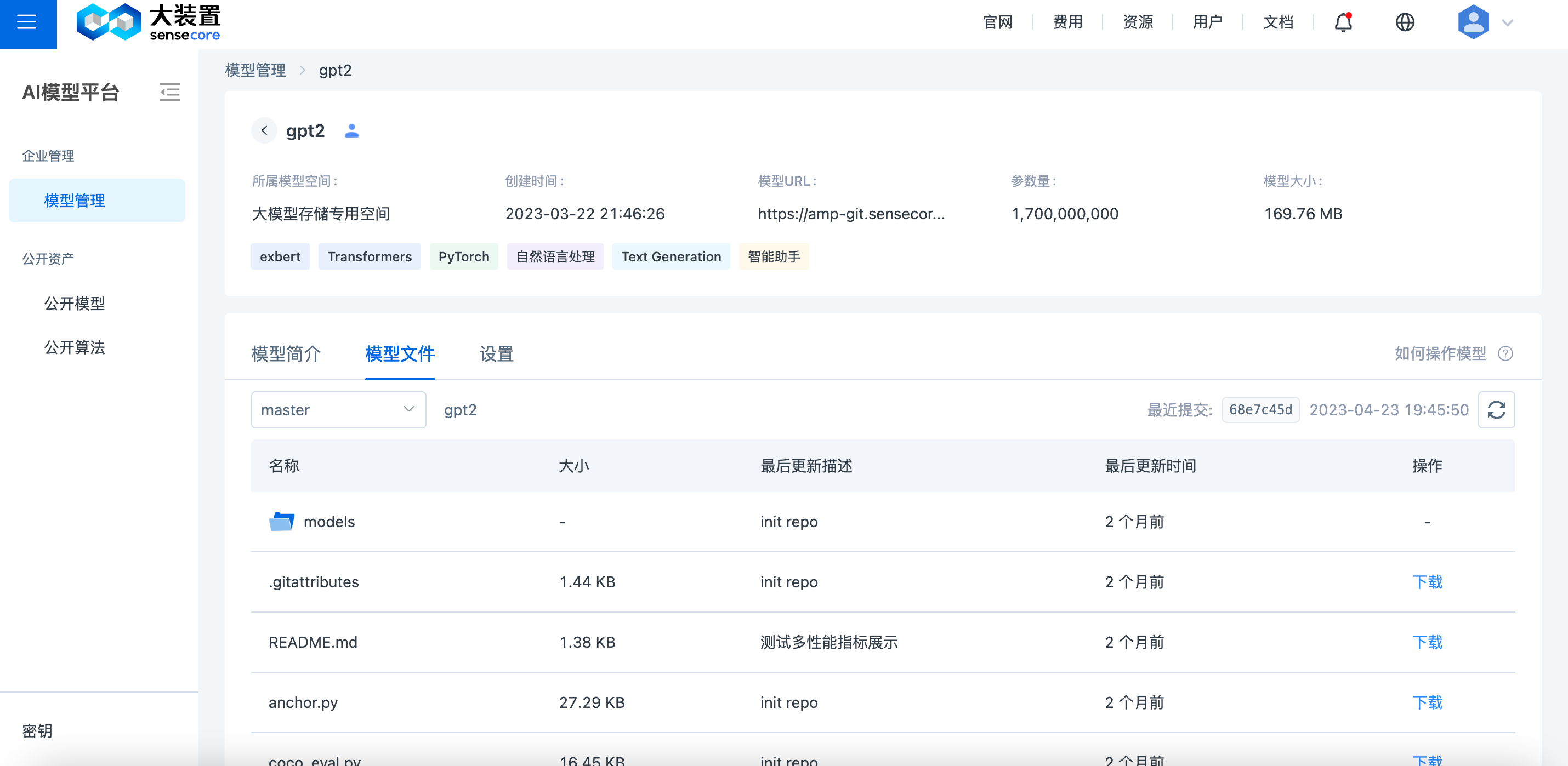
(3)git pull
$ git pull origin master #从远端拉取代码合并到本地
5.模型详情
模型是您创建后可用于存储和管理模型文件的仓库,拥有唯一的远端地址。
(1)模型总览
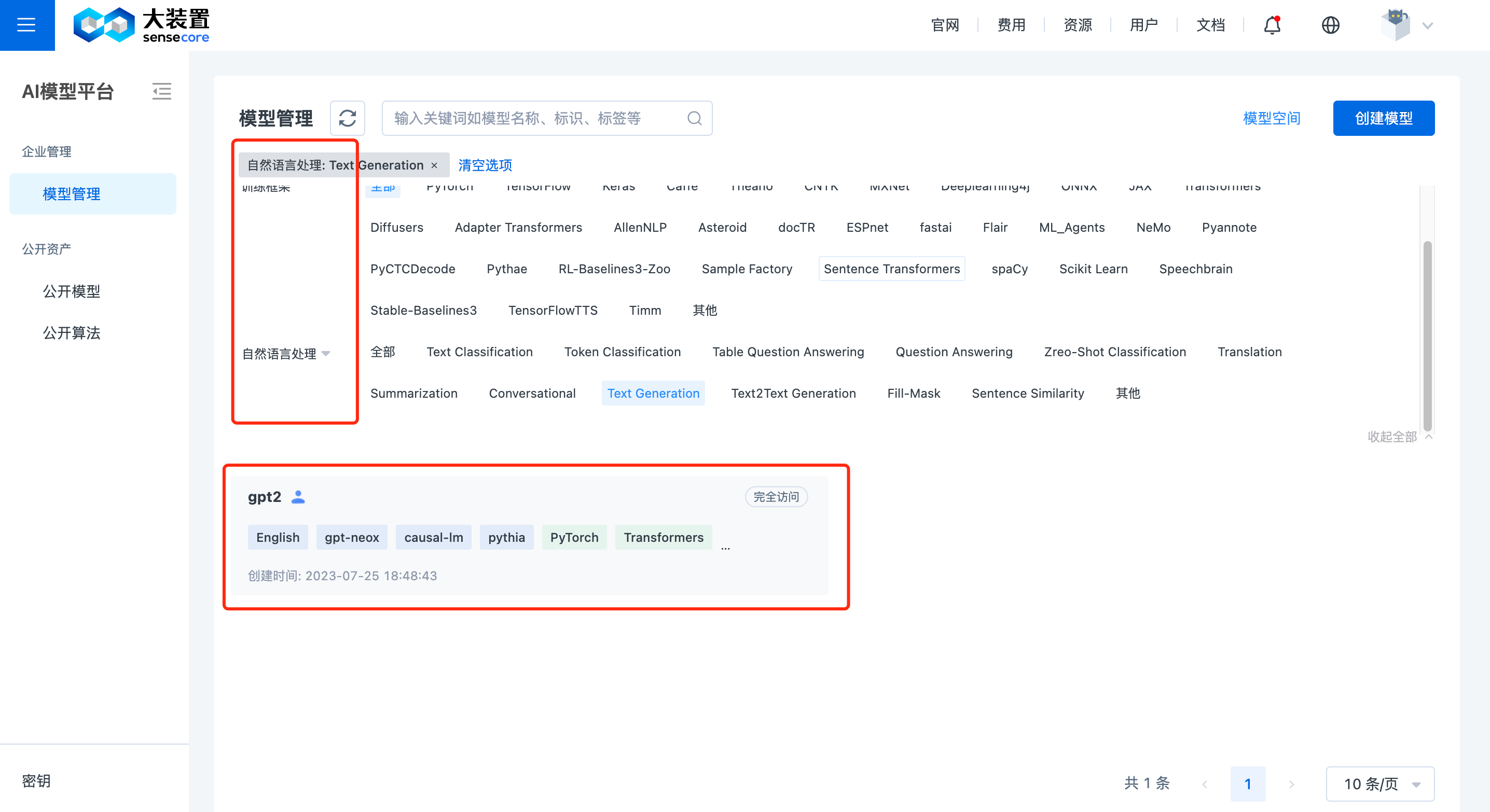
在模型管理页面,支持以卡片形式显示用户有权限的模型列表。卡片显示字段说明如下:
- 模型名称: 创建模型时填写的模型名称。
- 用户名: 创建该模型的用户名称。
- 性能信息: 从该模型的 master/README.md 中解析出的模型性能信息,若指定了数据集链接则可直接点击数据集名称跳转查看,规范参考模型描述文件
- 标签信息: 从该模型的 master/README.md 中解析出的标签信息,规范参考模型描述文件
- 权限信息: 登陆用户对该模型的操作权限。
平台支持模型筛选,可点击【展开全部】从模型空间、训练框架、任务类型三个维度对模型进行筛选。
(2)模型详情
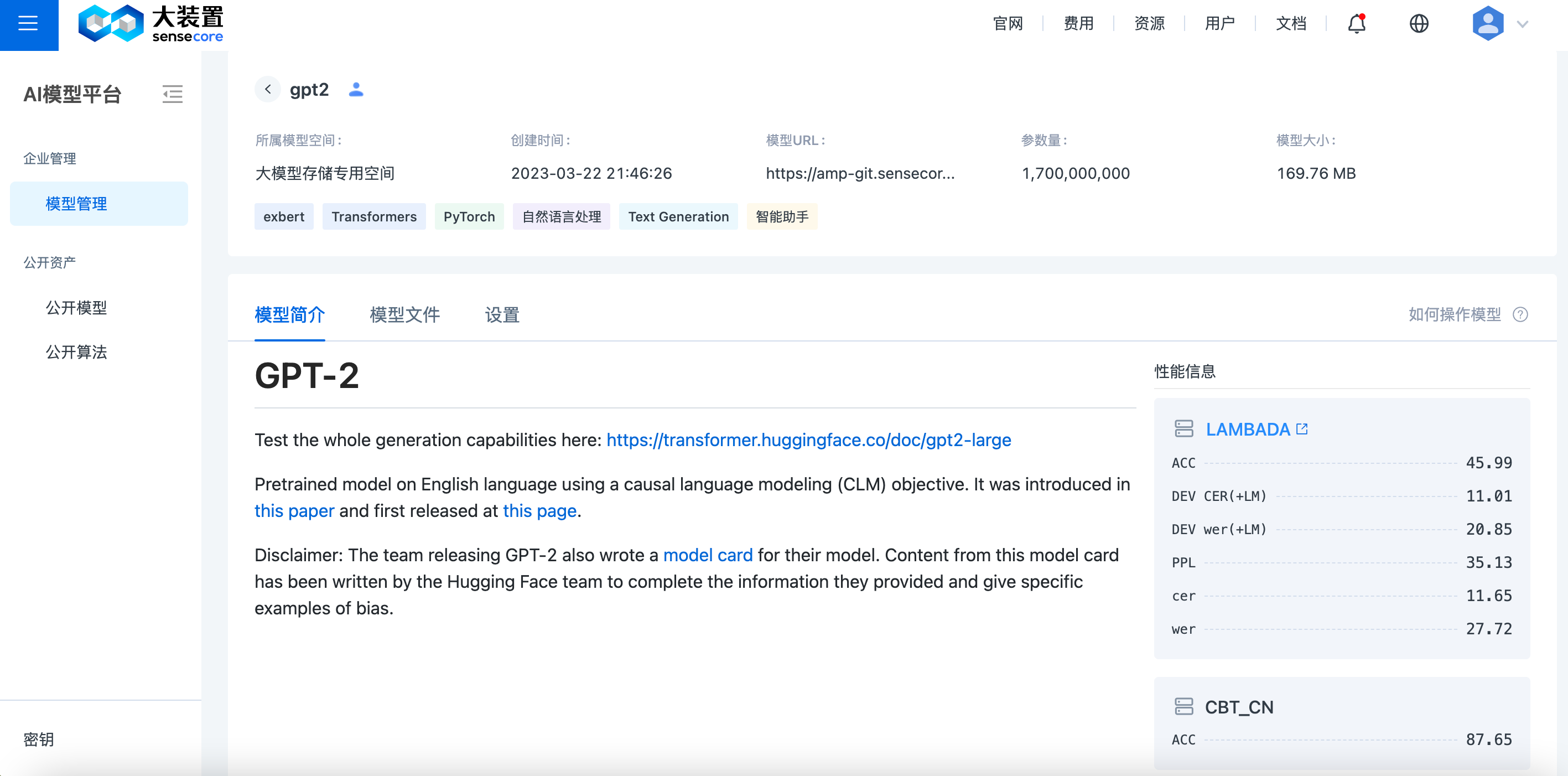
点击卡片即可进入模型详情页面,可查看模型基本信息、模型简介、模型文件三部分内容。
- 模型基本信息: 显示所属模型空间、创建时间、模型URL、参数量。
- 模型简介: 左侧显示 master/README.md 中模型说明部分内容,右侧显示 master/README.md 中模型性能部分内容。
- 模型文件: 可切换分支/版本查看对应模型文件列表,支持在线查看代码。
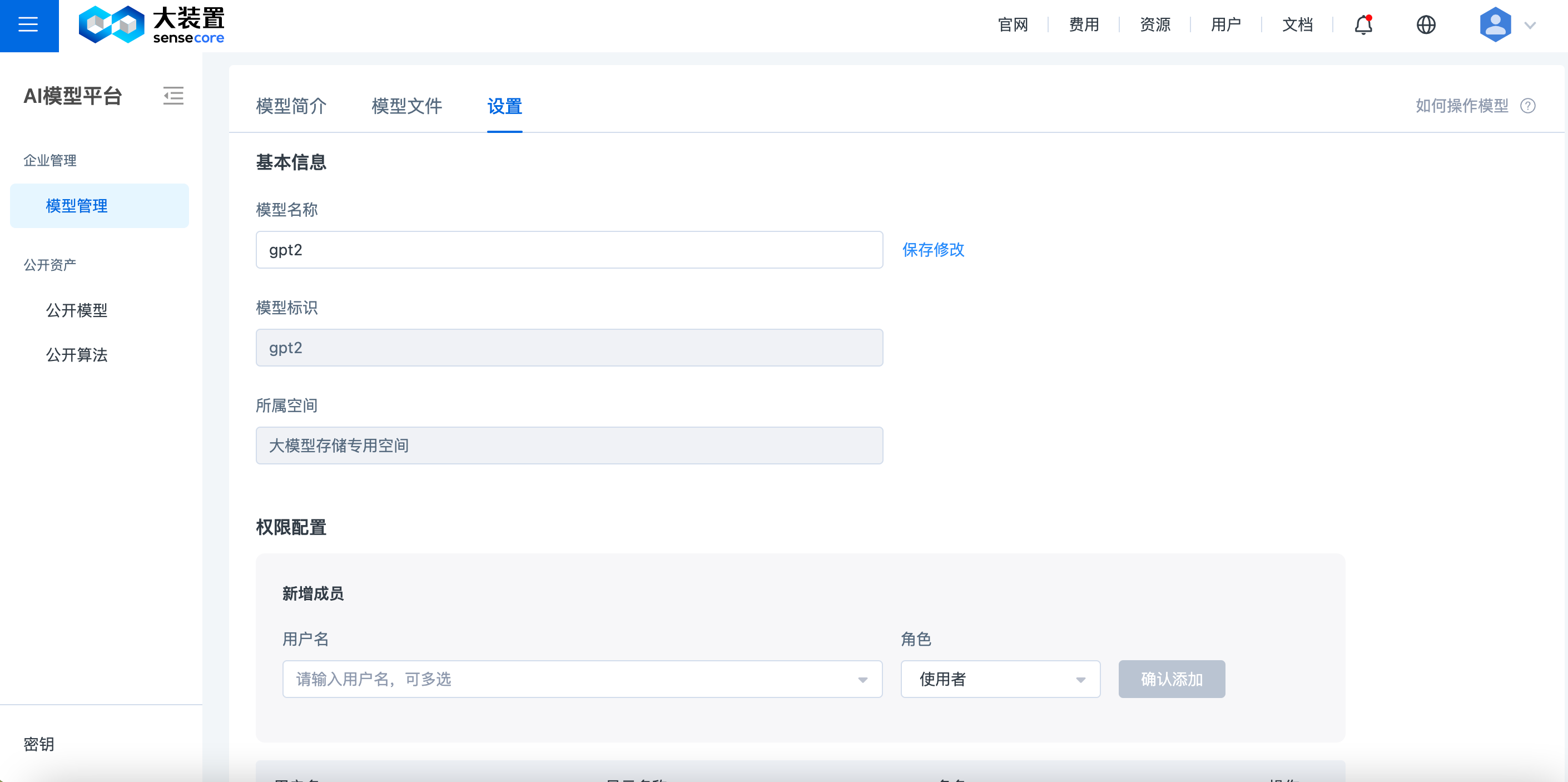
(3)模型设置
设置: 可修改模型名称,删除模型,配置模型权限。详细角色说明参考模型角色介绍
| 📣 Tips:模型空间的拥有者和维护者默认拥有空间内模型的完全访问权限,无需单独配置。 |
(4) 模型描述文件
该文件用于定义模型的描述信息,对于特殊字段,平台前端可自动渲染样式,并支持检索、跳转等特殊交互。
平台将自动从模型 master/README.md 文件内解析特定字段并展示,支持的保留字段及格式模版参考如下:
---
训练框架: #支持筛选
- PyTorch
- Transformers
任务类型:
类别: 自然语言处理 #支持筛选
算法: Text Generation #支持筛选
行业: 智能助手
其他标签: #支持搜索
- exbert
- en
参数量: 1700000000
开源协议: mit #支持搜索
性能信息:
- 数据集:
名称: LAMBADA #支持搜索
权限: 公开
链接:
性能指标:
PPL: 35.13
ACC: 45.99
- 数据集:
名称: CBT_CN
权限: 公开
链接:
性能指标:
ACC: 87.65
训练数据:
- 数据集:
名称: WebText #支持搜索
权限: 公开
链接: https://github.com/openai/gpt-2/blob/master/domains.txt #支持跳转
---
其他模型说明...
训练框架: 支持配置 PyTorch, TensorFlow, Keras, Caffe, Theano, CNTK, MXNet, PaddlePaddle, Deeplearning4j, ONNX, JAX, Transformers, Diffusers, Adapter Transformers, AllenNLP, Asteroid, docTR, ESPnet, fastai, Flair, ML_Agents, NeMo, PaddleNLP, Pyannote, PyCTCDecode, Pythae, RL-Baselines3-Zoo, Sample Factory, Sentence Transformers, spaCy, Scikit Learn, Speechbrain, Stable-Baselines3, TensorFlowTTS, Timm, 其他
任务类型: 仅可以在平台支持的范围中选择填写
| 类别 | 算法 |
|---|---|
| 多模态 | Feature Extraction, Text-to-Image, Image-to-Text, Visual Question Answering, Document Question Answering, Graph Machine Learning, 其他 |
| 计算机视觉 | Depth Estimation,Image Classification, Object Detection, Image Segmentation, Image-to-Image, Unconditional Image Generation, Video Classification, Zero-Shot Image Classification, 其他 |
| 自然语言处理 | Text Classification, Token Classification,Table Question Answering, Question Answering, Zreo-Shot Classification, Translation, Summarization, Conversational, Text Generation, Text2Text Generation, Fill-Mask, Sentence Similarity, 其他 |
| 音频 | Text-to-Speech, Automatic Speech Recognition,Audio-to-Audio, Audio Classification, Voice Activity Detection, 其他 |
| 表格 | Tabular Classification, Tabular Regression, 其他 |
| 强化学习 | Reinforcement Learning, Robotics, 其他 |
| 📣 Tips:"---"为平台解析模型描述信息的重要依据: 1. 请注意 "---" 所在行不能存在其他字符。 2. 首个"---"前仅可以存在空白字符。 |
根据 schema 解析保留字并筛选出模型的效果图如下:
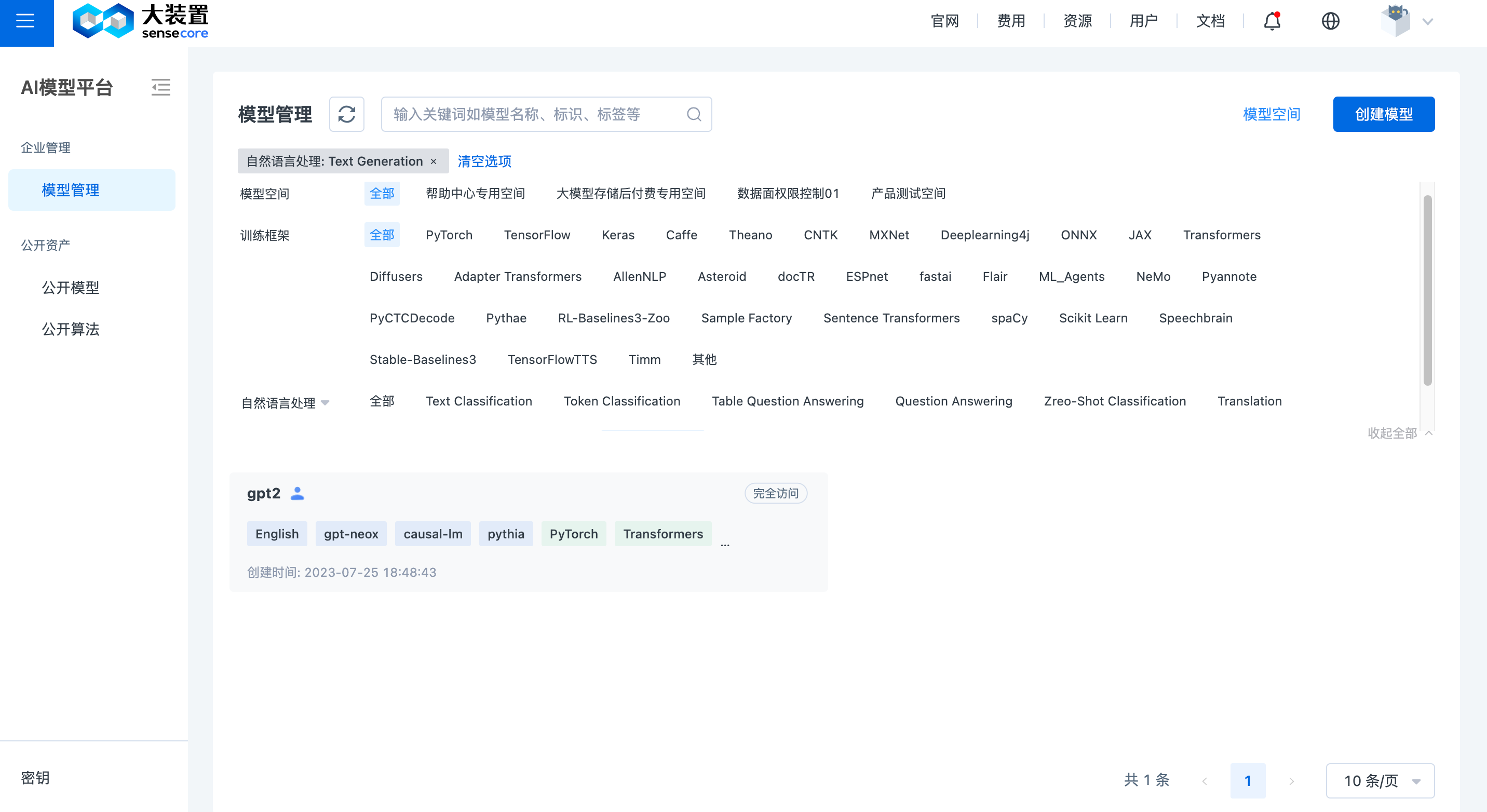
6.安全扫描工具
平台提供了安全扫描工具,对常见的代码漏洞、密钥泄露风险等进行识别,保障模型安全。
在模型详情页右上角,点击【安全扫描】按钮,选择想扫描的分支/版本/具体 commitID。
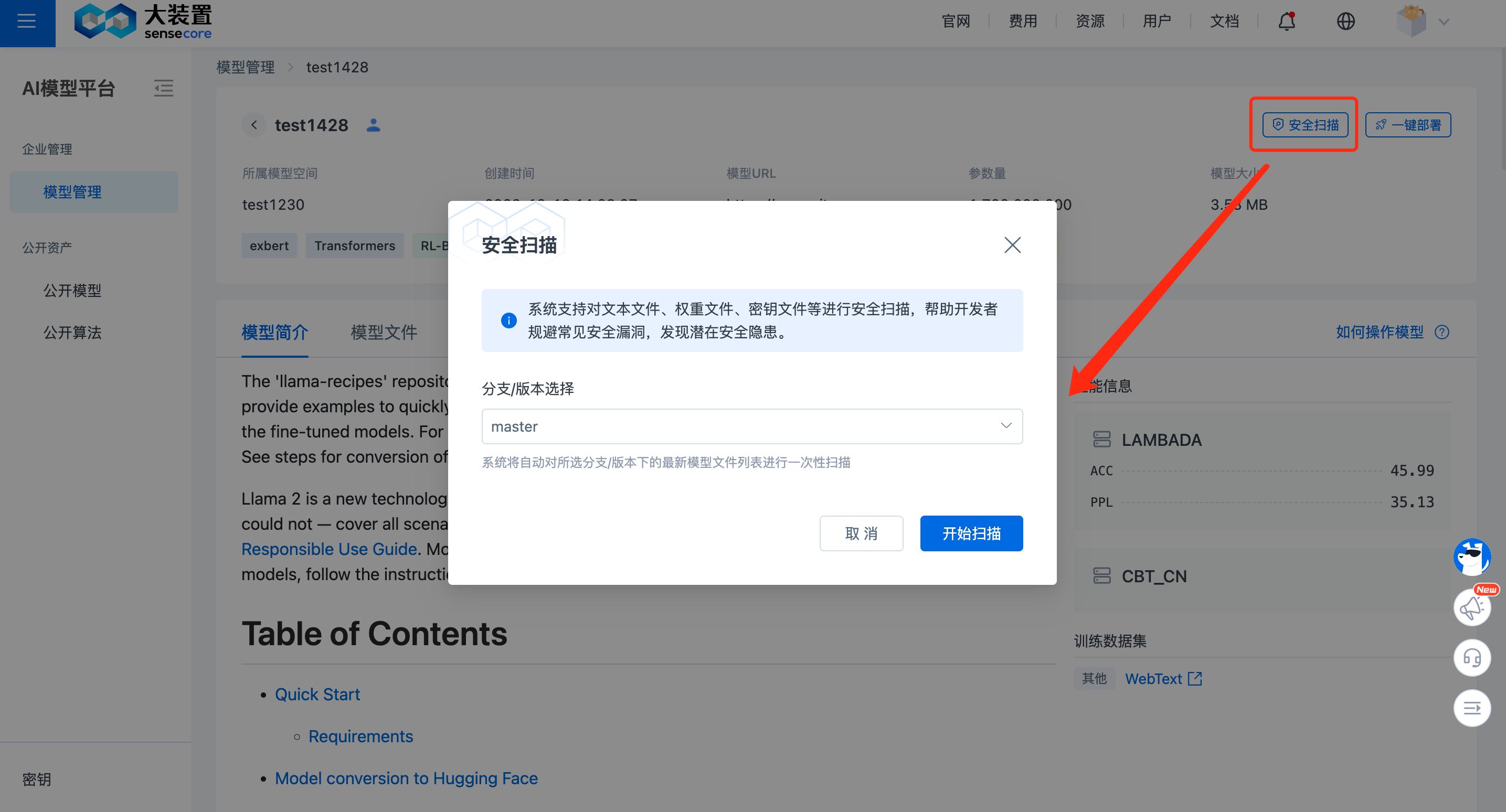
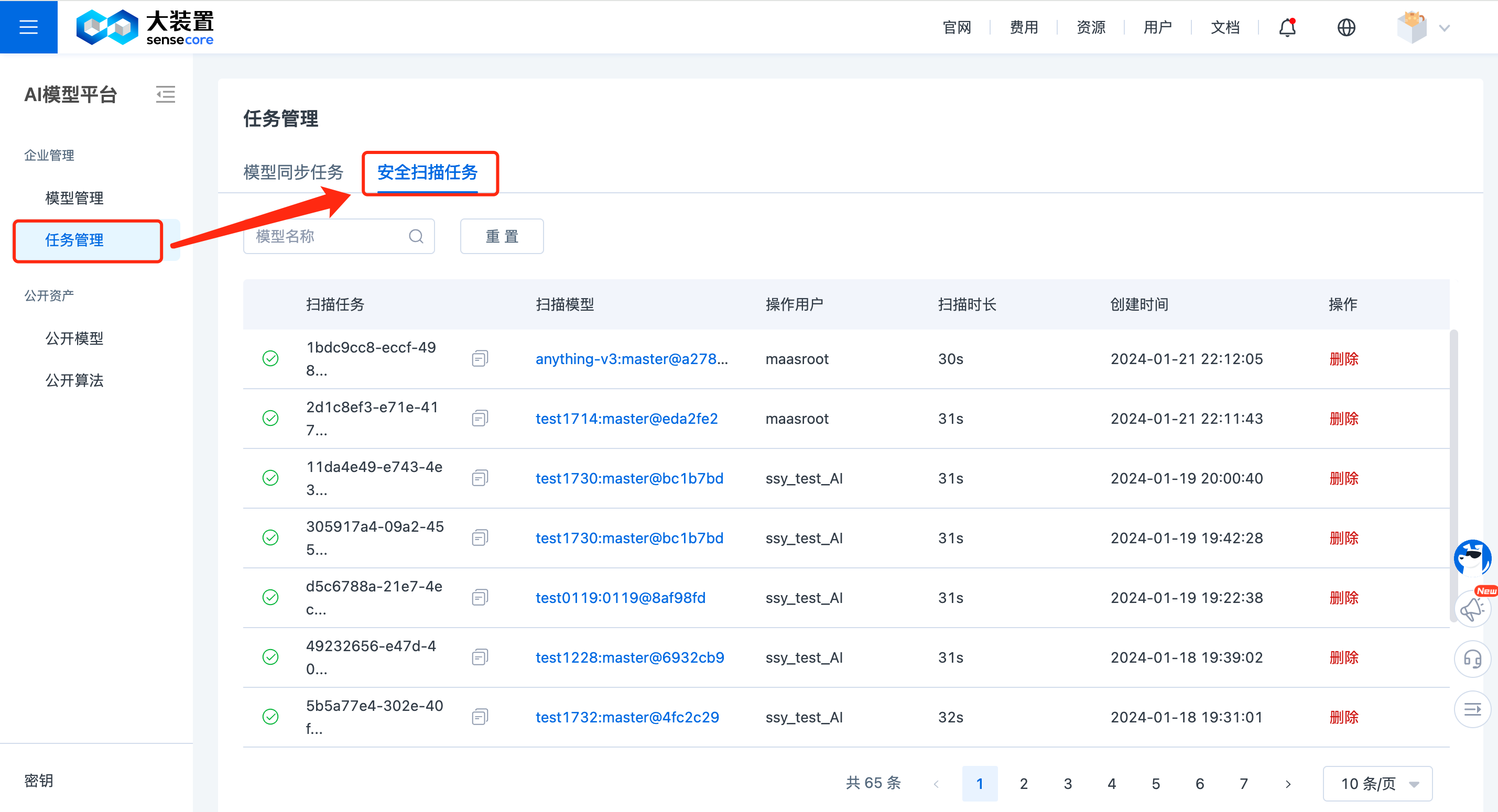
点击【开始扫描】启动扫描任务,并在 任务管理/安全扫描任务 列表内查看进度。
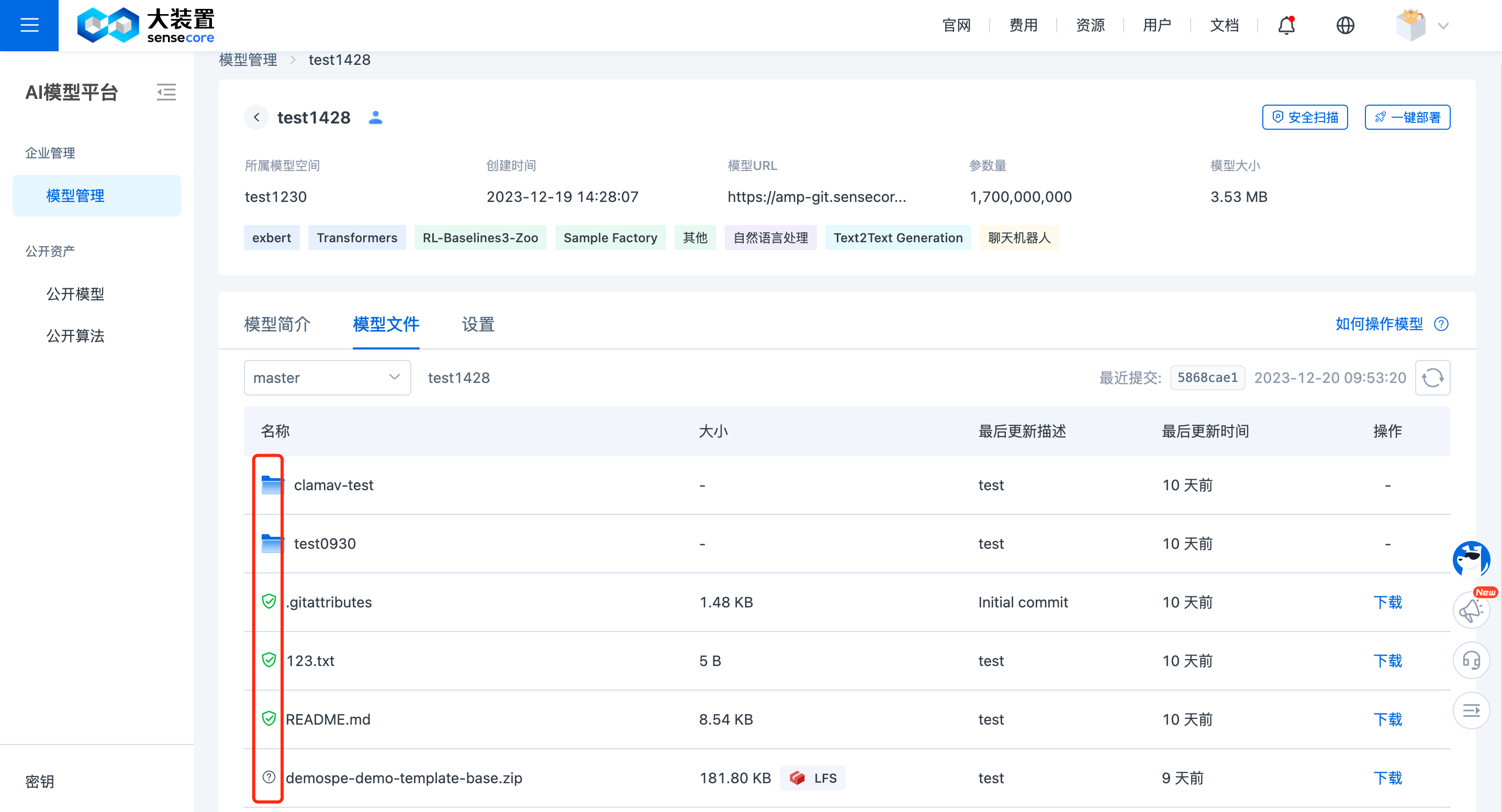
当安全扫描结束后,在模型文件列表页可以查看扫描结果。
7.模型同步工具
系统支持将用户模型同步到其他地区/可用区内,以便后续通过其他子产品(如AI推理服务等)使用时缩短模型下载速度。
在模型详情页右上角,点击【模型同步】按钮,选择目的可用区模型空间,及同步分支/版本/具体 commitID。
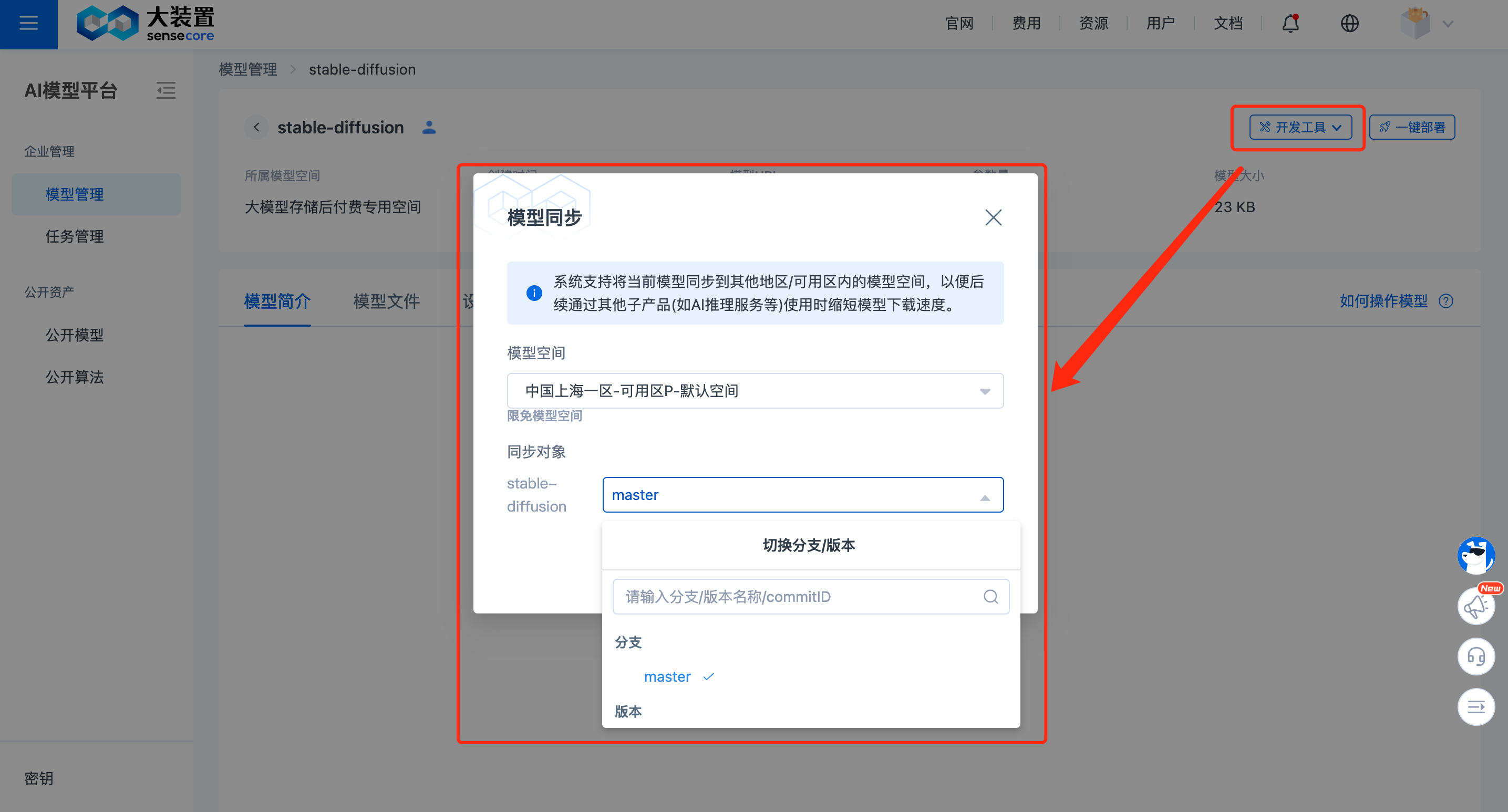
点击【开始同步】启动同步任务,并在 任务管理/模型同步任务 列表内查看进度。
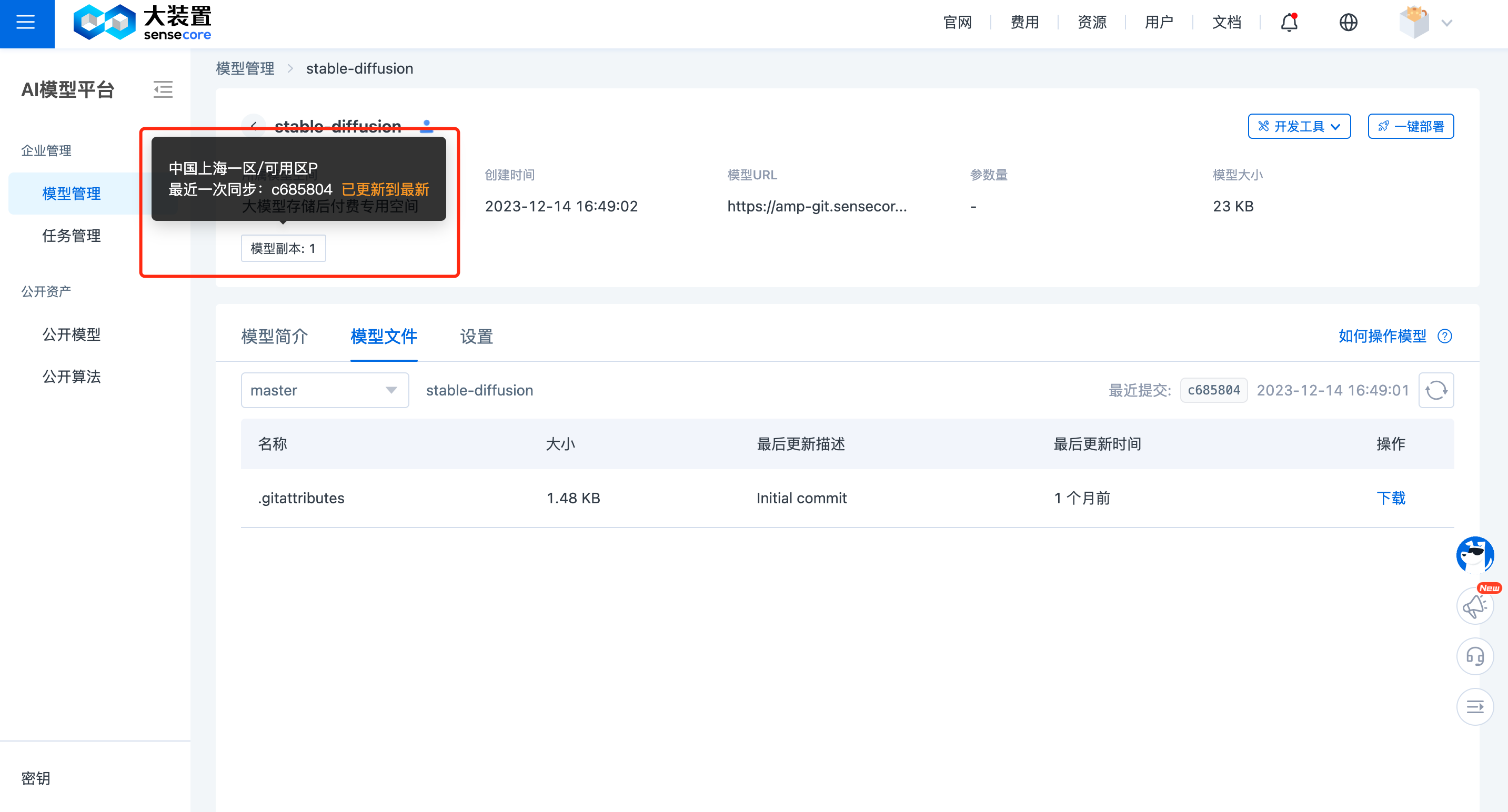
且当模型同步成功后,在该模型详情页会显示相应模型副本标签。
8.推理服务打通
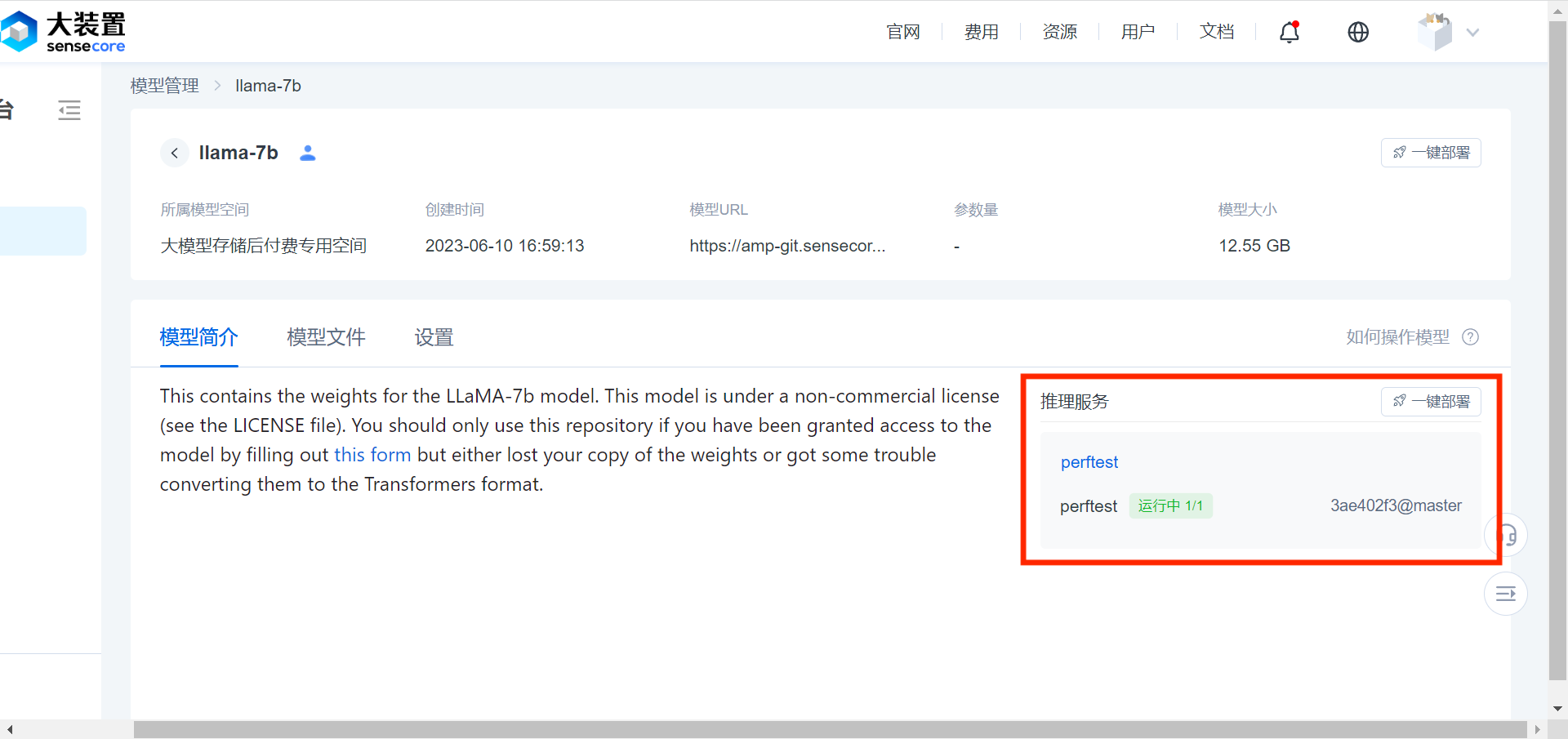
模型平台支持对用户模型和公开模型一键拉起推理服务,快速验证模型效果。
点击进入待部署的模型详情页,点击右上角的【一键部署】按钮,跳转至推理服务的创建页面。
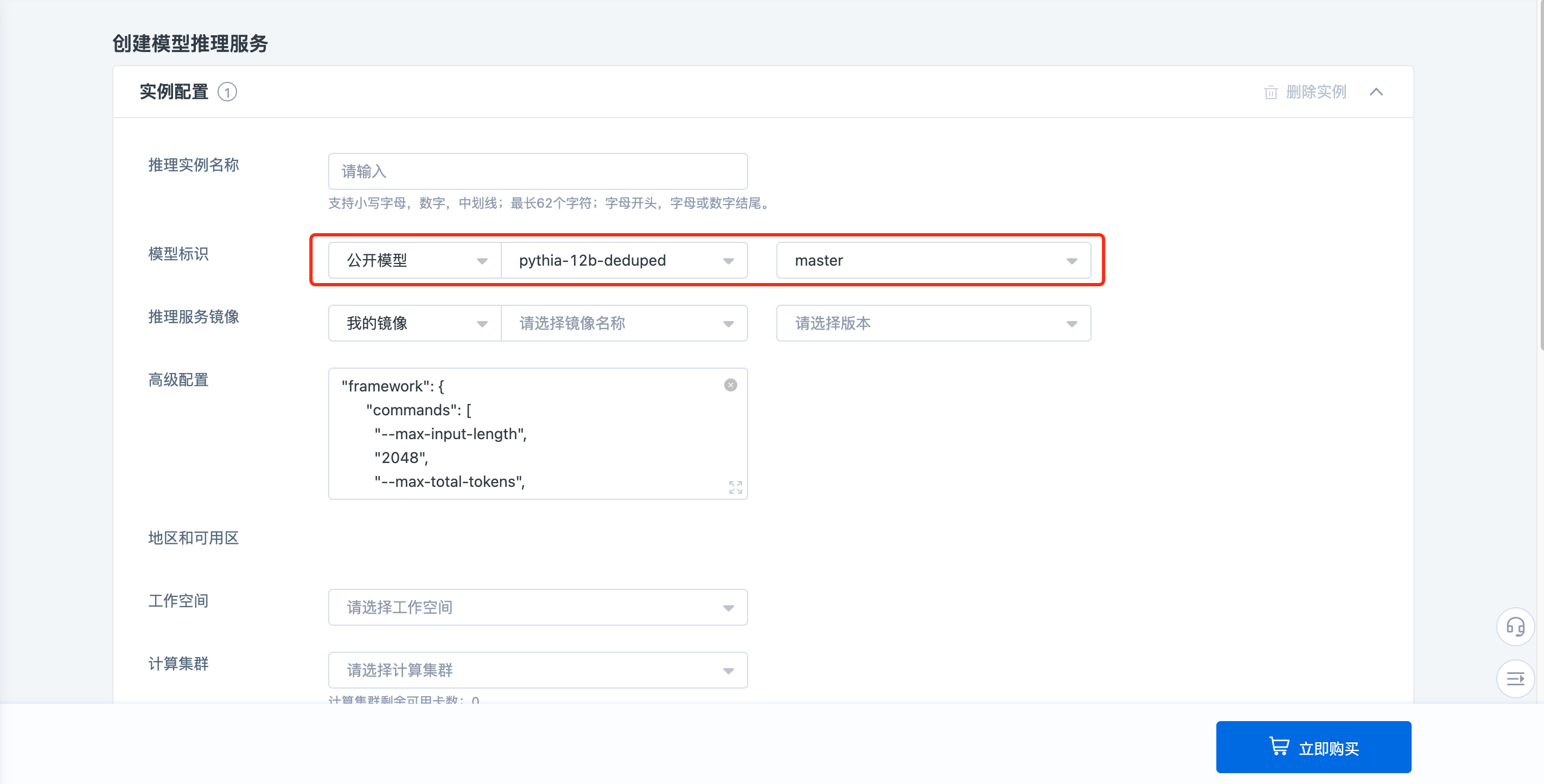
按照下单页要求配置推理服务参数,默认会选中该模型,支持修改,或调整特定的分支/版本。
创建成功后,模型详情页会显示对应推理服务的关键信息:推理服务名称、推理实例名称、状态、副本数,以及所采用的模型 commit id、版本/分支。
权限设置
模型空间级别的权限控制,具体角色及支持的操作范围如下表:
| 角色 | 角色说明 | 创建模型空间 | 使用模型空间 | 授权/取消授权 |
|---|---|---|---|---|
| 模型空间创建者 | 作用于资源/资源组/管理组,可配置 | ✅ | - | - |
| 模型空间拥有者 | 作用于某一模型空间实例,不可配置,默认为创建该资源的用户 | - | ✅ | ✅ |
| 模型空间维护者 | 作用于某一模型空间实例,可配置 | - | ✅ | ✅ |
| 模型空间用户 | 作用于某一模型空间实例,可配置 | - | ✅ | - |
模型级别的权限控制,具体角色及支持的操作范围如下表:
| 角色 | 角色说明 | 查看模型 | 检索模型 | 读模型文件 | 写模型文件 | 编辑模型 | 删除模型 |
|---|---|---|---|---|---|---|---|
| 模型拥有者 | 作用于某一模型实例,不可配置,默认为创建该模型的用户 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 模型维护者 | 作用于某一模型实例,可配置 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 模型开发者 | 作用于某一模型实例,可配置 | ✅ | ✅ | ✅ | ✅ | - | - |
| 模型使用者 | 作用于某一模型实例,可配置 | ✅ | ✅ | ✅ | - | - | - |
| 模型访客 | 作用于某一模型实例,可配置 | ✅ | ✅ | - | - | - | - |
常见问题
1、每次下载模型都需要输入密钥很麻烦,如何能缓存?
git config --global credential.helper 'store --file ~/.git-credentials' #缓存 secret