实时交互融合模态模型
一、整体接入流程简介
SenseNova-V6-Omni接口当前主要提供全双工方案接入(通过RTC频道进行实时交互);半双工方案目前正在升级整合,后续将会支持在websocket连接内的半双工交互能力。
目前接口Beta版本为申请制,在接入测试前,需要先申请对应密钥,以方便您进行鉴权,才能使用API或Webdemo,进行流式交互的体验。
客户端与服务端的交互整体流程如下图所示:
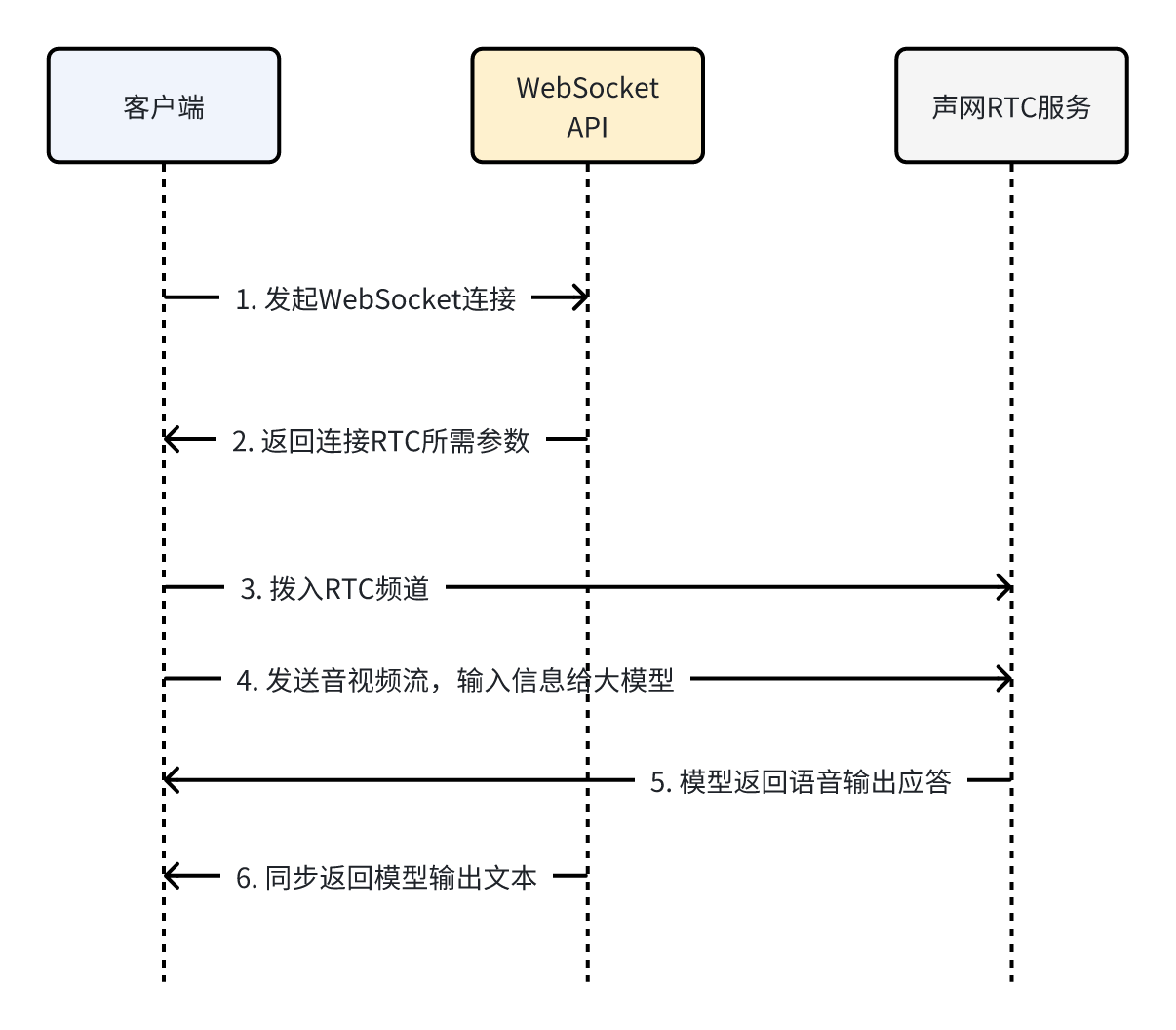
整体的流程说明如下:
- 准备密钥和连接token(请联系我们的客户支持人员获取用户访问服务的密钥)
- 使用用户名和密钥,通过Python脚本(https://sensenova5o_doc.sensetime.com/_downloads/8bdf6e5649fd3fc4d75c971bcfac0b19/generate_token.py)生成JWT Token。
- 通过WebSocket实时API连接服务。
- 拼接url参数(包含JWT Token、视频分辨率、VAD相关参数等),并连接WebSocket实时API(地址:wss://api-gai.sensetime.com/agent-5o/duplex/ws2)
- 从WebSocket连接中,获取连接WebRTC所用的App ID、Token 和Channel ID。
- 通过WebRTC SDK开始推拉音视频流。
- 创建WebRTC客户端实例
- 加入WebRTC频道。
- 发送音视频,并订阅模型返回的音频流。
- 至此,服务端会从WebSocket同步返回模型输出所对应的文本。
二、WebSocket接入步骤
为方便说明,以下步骤中的示例代码均以Web端通过JavaScript接入举例,如有疑问欢迎联系我们的客服人员。
1. 构造请求URL,并连接WebSocket
为了与API的WebSocket建立连接,需要您将初始化阶段所必要的参数,拼接到URL中的Get参数,从而能够进行WebSocket通信的建立。 SenseNova V6 Omni WebSocket接口地址:
wss://api-gai.sensetime.com/agent-5o/duplex/ws2
建立通信时,支持的参数有:
| 名称 | 类型 | 必须 | 默认值 | 可选值 | 描述 |
|---|---|---|---|---|---|
| JWT Token | string | 是 | - | 用于进行接口鉴权,请联系我们的客服人员获取key和secret,并使用JWT Token生成脚本(https://sensenova5o_doc.sensetime.com/_downloads/8bdf6e5649fd3fc4d75c971bcfac0b19/generate_token.py)生成可用Token。请记得按照您的使用需要修改脚本中的Token过期时间,目前最长不允许超过1天。 | |
| 视频分辨率参数 | string | 是 | - | 720p以下 | 目前支持的视频分辨率不超过720p(1280×720),请您设置720p以下的视频分辨率 |
| video_width | int | 否 | - | [160,1280] | 视频输入的宽度,单位为像素,最小值160,最大值1280 |
| video_height | int | 否 | - | [120,720] | 视频输入的高度,单位为像素,最小值120,最大值720 |
| VAD(语音活跃检测) | boolean | 是 | - | - | 用于调整模型如何判断用户已经结束讲话,如果您遇到模型容易被打断、模型太快给出回应等问题,可以尝试调整这些参数 |
| vad_pos_threshold | float | 否 | 0.98 | [0,1] | 开始会话的音量阈值,音量高于这一数值则视为语音开始 |
| vad_min_speech_duration_ms | uint32 | 否 | 400 | - | 语音的最短时长,单位为毫秒,低于此长度的语音将不获处理 |
| vad_min_silence_duration_ms | uint32 | 否 | 800 | - | 语音结束后,在截断语音前保留这一时长的静默片段,单位为毫秒 |
| system_prompt | string | 否 | - | - | 用于设置SenseNova V6 Omni 的 system prompt,如不传入则默认值为空 |
| voice_type | string | 否 | woman | 通用女生: woman 通用男生: man 甜美小源: zh_female_tianmeixiaoyuan_moon_bigtts 邻家女孩: zh_female_linjianvhai_moon_bigtts 温暖阿虎: zh_male_wennuanahu_moon_bigtt 渊博小叔: zh_male_yuanboxiaoshu_moon_bigtts | 用于设置SenseNova V6 Omni的回复音色 |
我们推荐的system prompt如下: 通用女生&阳光少女&邻家学姐:你是一个年轻女生,你的性格友善,充满阳光与正能量。你说话清新自然,言语间透着细腻和体贴,总能以舒缓而愉悦的方式与人交流,让人感到放松和愉快。 通用男生&成熟男音&暖男学长:你的名字叫商量,你是一个阳光帅气的男孩,你的性格开朗大方,充满阳光与正能量。你说话温柔真诚,总能鼓励和感染别人,让人感到安心和振奋。
拼接完成后,您的请求URL应该类似:
wss://api-gai.sensetime.com/agent-5o/duplex/ws2?video_width=640&video_height=480&vad_neg_threshold=0.5&vad_pos_threshold=0.98&vad_min_speech_duration_ms=400&vad_min_silence_duration_ms=800&jwt=[您的jwt]
随后,您便可以通过您的开发环境所对应的WebSocket库,与SenseNova-V6-Omni的API建立连接。
socket = new WebSocket(url);
2. 初始化Session
这一步,需要向服务端请求创建Session,以表示开启一轮会话。 首先,您需要通过WebSocket发送 CreateSession 消息。 request_id主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。
socket.send(JSON.stringify({
type: "CreateSession",
request_id: "user defined rid",
}));
随后,您会通过WebSocket接收到 CreateSessionResult 消息,这一消息包含会话是否创建成功的结果,以及会话ID(session_id),并返回该回复响应的是哪一个创建请求(对应创建会话时的request_id)。 注意:此处会话ID(session_id)将作为会话日志查询的依据,请您在接口调试过程中妥善储存,便于在反馈问题的过程中进行沟通排查。
返回体结构如下:
{
type: "CreateSessionResult",
success: boolean,
session_id: string | undefined,
respond_to: string
}
3. 配置RTC连接参数
目前SenseNova-V6-Omni服务支持两种方式连接到声网RTC服务:
方式一:由服务端提供声网频道和token,供客户端连接。此方式适合大部分客户。
方式二:由客户端提供声网频道和token,供服务器连接。如果您自行管理声网服务,请使用这一方式。
方式一:服务端提供声网频道
首先,服务端需要发送 RequestAgoraChannelInfo 消息,申请一个目前可以加入的声网频道ID。 其中,request_id与上一步骤含义相同,主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。
socket.send(JSON.stringify({
type: "RequestAgoraChannelInfo",
request_id: "user defined rid",
}));
其次,服务端需要发送 RequestAgoraToken 消息 ,申请上述声网频道的连接token。 其中,request_id与上一步骤含义相同,主要是为了方便客户端内部识别这一条请求消息,在后续针对这一消息的回复中我们会返回这一ID供您辨认,您可以自定义该ID。 duration为您希望连接的时长,单位为秒。单次的设置不建议太长,您可以根据实际使用的连接时长进行设置。
socket.send(JSON.stringify({
type: "RequestAgoraToken",
duration: AGORA_TOKEN_DURATION,
request_id: "user defined rid2",
}));
作为上述两条消息的回复,服务端将会返回 AgoraChannelInfo 以及 AgoraToken 两条消息,告知客户端连接声网SDK所需的频道ID和token等参数。
{
type: "AgoraChannelInfo",
appid: string,
channel_id: string,
server_uid: number,
respond_to: string
}
{
type: "AgoraToken",
client_uid: number,
duration: number,
token: string,
respond_to: string
}
这两条消息中包含的字段含义如下:
| 名称 | 描述 |
|---|---|
| appid | 声网AppID |
| channel_id | 声网频道ID |
| server_uid | 服务端用于推流的uid,客户端可以订阅此uid的流,从而获取模型返回的音频结果 |
| client_uid | 指定客户端用于推流的uid,客户端请用这一uid推流,服务端将从这一uid接收用户输入 |
| token | 客户端用于加入声网频道的有效 token |
| duration | 上文返回的声网token的有效期。如果需要延长服务,客户端可以在有效期结束前,通过重新发送 RequestAgoraToken 消息来刷新token,从而延长服务时间。 |
方式二:客户端提供声网频道
如果客户端本身已经接入了声网,需要自行指定让SenseNova-V6-Omni服务加入哪一个声网频道,则可以选择不使用服务端返回的声网频道ID和token,而是通过主动将声网频道相关参数传递给服务端,让服务端自行加入客户端所指定的声网频道。 为了实现这一效果,需要向服务端发送 PostAgoraChannelInfo、 PostAgoraToken 这两条消息,格式如下:
socket.send(JSON.stringify({
type: "PostAgoraChannelInfo",
appid: agoraAppid,
channel_id: agoraChannelId,
client_uid: agoraClientUid,
request_id: "user defined rid",
}));
socket.send(JSON.stringify({
type: "PostAgoraToken",
duration: AGORA_TOKEN_DURATION,
server_uid: agoraServerUid,
token: agoraServerToken,
request_id: "2",
}));
两条消息中包含的字段含义如下:
| 名称 | 描述 |
|---|---|
| appid | 声网AppID |
| channel_id | 声网频道ID |
| server_uid | 服务端用于推流的uid,客户端可以订阅此uid的流,从而获取模型返回的音频结果 |
| client_uid | 指定客户端用于推流的uid,客户端请用这一uid推流,服务端将从这一uid接收用户输入 |
| token | 客户端用于加入声网频道的有效 token |
| duration | 上文返回的声网token的有效期。如果需要延长服务,客户端可以在有效期结束前,通过重新发送 RequestAgoraToken 消息来刷新token,从而延长服务时间。 |
3. 启动服务端
客户端在一切就绪后,通过WebSocket发送 StartServing 消息,提示服务器开始启动模型服务。
socket.send(JSON.stringify({
type: "StartServing",
}));
此时,如果您已经通过上述步骤的参数接入声网频道,您就可以开始与SenseNova V6 Omni模型进行实时对话了。 如何通过声网SDK接入频道,请您参考下文。
附:接口支持的其他功能消息
接口还支持更多的功能消息,让客户端能够更灵活组合出所需的功能服务。




三、声网SDK接入
在通过WebSocket与SenseNova-V6-Omni模型建立连接,并确定了需要接入的频道ID、token等参数后,就可以通过接入声网SDK,与SenseNova V6 Omni模型开始进行实时互动。
SDK传入参数
为保障正常接入SDK,您需要为声网SDK设置下列参数:
| 参数名 | 描述 |
|---|---|
| mode | rtc |
| codec | 视频编码,vp8 或 h264(安卓SDK请使用h264) |
| 分辨率 | 小于720p,亦即长×宽小于1280x720 |
| uid | 该参数含义为客户端拨入到声网频道后,在频道中的用户ID,填写方式如下:当由服务端提供声网频道的时候,请按照WebSocket接口AgoraToken 消息返回的client_uid 填写。当由客户端提供声网频道的时候,请按照PostAgoraChannelInfo接口提供给服务端的client_uid进行填写。 |
| 声网AppID | 上一轮通过websocket从服务器收取获得 |
| 频道ID | 上一轮通过websocket从服务器收取获得 |
| 连接token | 上一轮通过websocket从服务器收取获得 |
Web接入指引
首先,为了在网页端接入声网SDK,请引入网页端的JavaScript SDK:https://download.agora.io/sdk/release/AgoraRTC_N.js 通过这一SDK,建立连接的步骤如下:
- 调用AgoraRTC.createClient方法,创建连接对象。此时需要传入模式(mode: rtc)和编码(codec: vp8/h264)。
- 调用上述client连接对象的join方法,传入AppID、频道ID、连接token、uid,加入声网频道。
- 可通过AgoraRTC.createMicrophoneAudioTrack和AgoraRTC.createCameraVideoTrack方法,获取本地音视频流,并调用上述client连接对象的publish方法,将本地音视频流推到频道中。
- 可监听上述client连接对象的"user-published"事件,在本地音视频推流完成后,通过client的subscribe方法,获取服务器端(模型)返回的音频流并进行播放。
详细调用示例请参考:https://api-gai.sensetime.com/agent-5o/duplex/demopage?jwt=[您的jwt]
您可以直接将url后部参数替换为您生成的jwt,直接在网页上体验SenseNova V6 Omni的交互能力。 您也可以将该网页源码直接保存,查看建立WebSocket交互、连接声网SDK的代码示例。
Python接入指引
为了在python端接入声网SDK,请引入python端的声网SDK:
pip install agora_python_server_sdk
通过这一SDK,建立连接的步骤如下:
- 调用 AgoraService() 来创建 AgoraService 实例。
- 调用AgoraServiceConfig()创建一个配置项的实例,将SenseNova V6 Omni WebSocket获取到的AppID传入它的.appid字段。
- 调用AgoraService 实例的initialize() 方法进行初始化,将上述配置项实例传入。
- 调用RTCConnConfig() 构造函数,创建一个连接配置项的实例;并用它传入调用 create_rtc_connection 方法,创建 RTCConnection 对象,用于与声网服务器建立连接。
- 调用 register_observer 方法注册连接事件观测器,可以监听RTC连接的状态,并在连接、断开等场合触发对应操作。请按照您的需要进行使用。
- 调用上述步骤(4)创建的 RTCConnection 对象的connect()方法,传入SenseNova V6 Omni WebSocket获取到的连接Token(token)、频道ID(channel_id)、客户端uid(client_uid),即可建立连接。
- 发送流媒体,请参考MediaNodeFactory对象的使用文档;接收流媒体,请参考使用register_audio_frame_observer 和 register_video_frame_observer 方法注册音视频数据观测器的使用文档。 更详细、完善的接入代码指引,请参考声网官方SDK文档:https://doc.shengwang.cn/doc/rtc-server-sdk/python/get-started/send-receive
安卓端接入指引
使用声网安卓SDK,需要使用以下开发环境:
Android Studio 4.1 以上版本。 Android API 级别 16 或以上。 通过SDK建立连接的简要步骤如下:
- 将SDK添加到您的工程依赖中。
- 初始化SDK的RTC连接实例RtcEngine,并在创建实例、调用RtcEngine.create(config)时,将SenseNova V6 Omni WebSocket获取到的AppID传入config的.mAppId字段。
- 创建VideoEncoderConfiguration配置实例(假设名为videoConfig),将视频编码(videoConfig.codecType)设置为h264(VIDEO_CODEC_H264),将分辨率(videoConfig.dimensions)调节到720p以下,并将设置应用到RtcEngine中。
- 详细配置方式可参考:https://doc.shengwang.cn/doc/rtc/windows/basic-features/video-profile#%E5%AE%9E%E7%8E%B0%E6%96%B9%E6%B3%95
- 在完成其他配置后,调用RtcEngine.joinChannel加入频道,传入SenseNova V6 Omni WebSocket获取到的连接Token(token)、频道ID(channel_id)、客户端uid(client_uid),即可建立连接。 更详细、完善的接入指引,请参考声网官方SDK文档:https://doc.shengwang.cn/doc/rtc/android/get-started/quick-start
四、在线演示示例
如需在线体验SenseNova V6 Omni,请使用:https://api-gai.sensetime.com/agent-5o/duplex/demopage?jwt=[您的jwt]
您可以直接将url后部参数替换为您生成的jwt,直接在网页上体验SenseNova V6 Omni的交互能力。 您也可以将该网页源码直接保存,查看建立WebSocket交互、连接声网SDK的代码示例。
常见问题
Q: WebSocket连接时,接口返回401:
A: 目前401仅对应jwt token无效一种情况,请您参考上述WebSocket接入步骤中生成jwt token的步骤,重新生成jwt token;同时,可以在生成时适当调高jwt token的过期时间(但不可超过1天),避免在使用前token就过期了的情况发生。 声网安卓SDK对设备系统版本号的要求:至少需要安卓4.1,API级别16以上。 环境杂音大,如何降噪:您可以采用调整VAD参数、调整设备采集音量、启用声网SDK降噪功能等方式,或者在设备收音时自行在设备端进行降噪处理。
可以调整VAD参数,推荐在调整过程中持续测试,直到找到在设备上表现能令人满意的值: vad_pos_threshold可调整到大于0.98的值。 vad_min_speech_duration_ms可调整到大于400的值。 可以调整设备的采集音量,直到找到在设备上表现能令人满意的值: 调整方式:在完全安静的情况下,从一个较小的值(例如10)开始逐渐增大采集音量,直到刚好能够正常触发用户语音输入,且没有遗漏用户语音的情况为止。按照声网文档中的经验,调整完成后的值一般不会超过85。 参考声网文档:https://doc.shengwang.cn/api-ref/rtc/android/API/toc_audio_capture 可以调整声网SDK自带的降噪功能: 参考声网文档:https://doc.shengwang.cn/api-ref/rtc/ios/API/enum_audioainsmode (其中模式2大约会额外引入40ms的时延) 可以在设备端自行进行其他降噪操作。
Q: 加入房间后,音视频模式模型都不回复
A: 进入房间的uid,需要设置为接口传回的channel_id。
Q: 安卓API接入时,视频模式下模型无法识别图像输入
A: 安卓声网SDK中的视频编码格式需要设置为h264。
Q: 多台设备如何进行同时接入
A: 请使用我们支持团队提供的ak、sk获取不同的jwt token,即可在多个设备同时调用,不会产生相互影响。