快速部署Llama3-8B-Instruct
创建推理服务
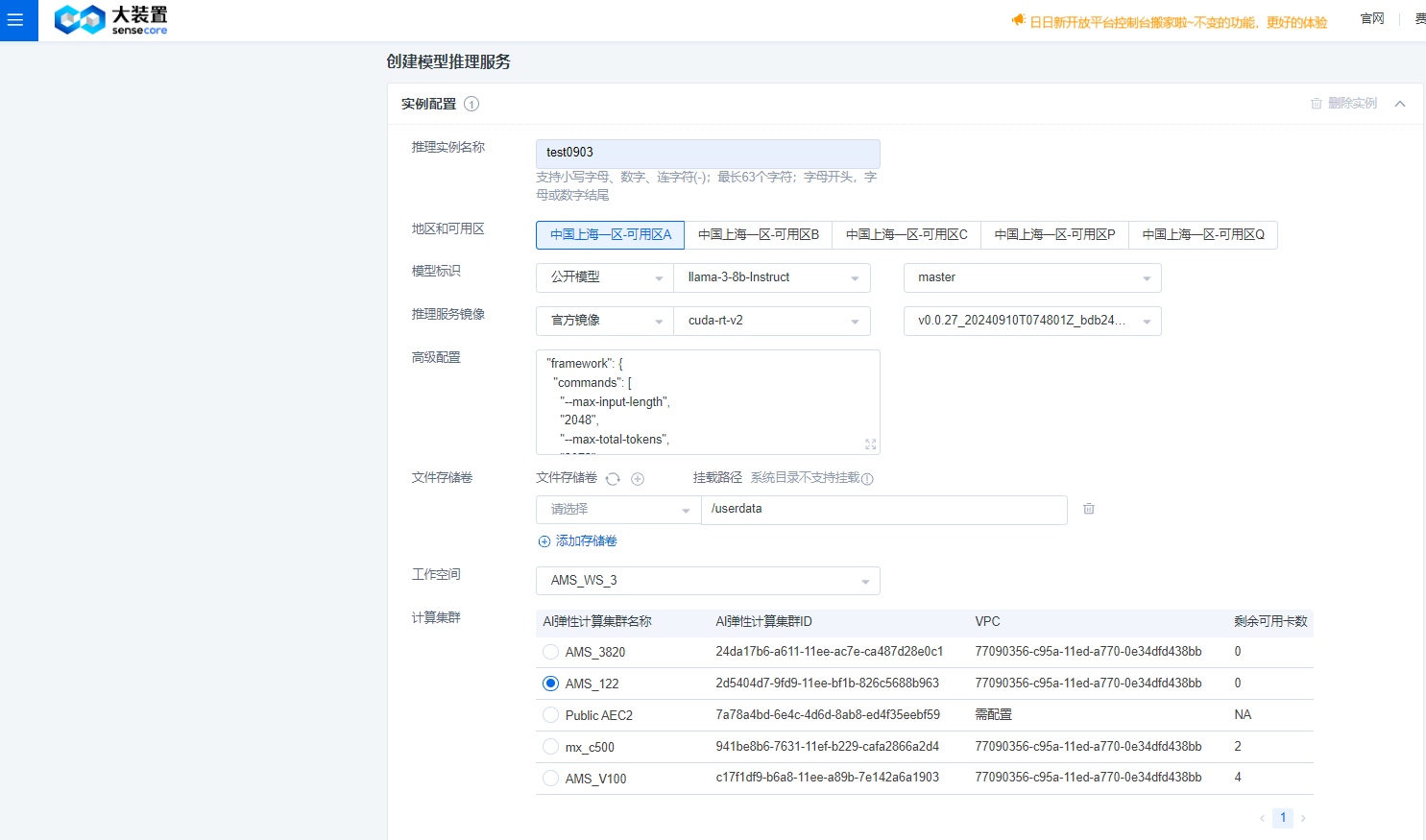
如下图所示,录入推理实例名称、选择地域及可用区。
模型标识选择:公开模型->llama-3-8b-instruct->master;
推理镜像选择:官方镜像->cuda-rt-v2->v0.0.27_20240910T074801Z_bdb242f9e;
高级配置:
"framework": /br{
"commands": [
"sh",
"-c",
" /opt/etc/monorepo/prod/studio/ams/v2/engine/tgi/qwen2/qwen2 --model={{ .MODEL_PATH_PREFIX }} --port 18001"
],
"envs": [
{
"name": "NCCL_DEBUG",
"value": "WARN"
}
],
"sidecar": {
"pool_size": 1,
"pool_wait": 100,
"load_threshold": 0.999
}
}
工作空间:选择提前预创建的工作空间,具体创建流程可参考:弹性计算集群AEC2->工作空间管理。
计算集群:选择工作空间已绑定的计算集群;
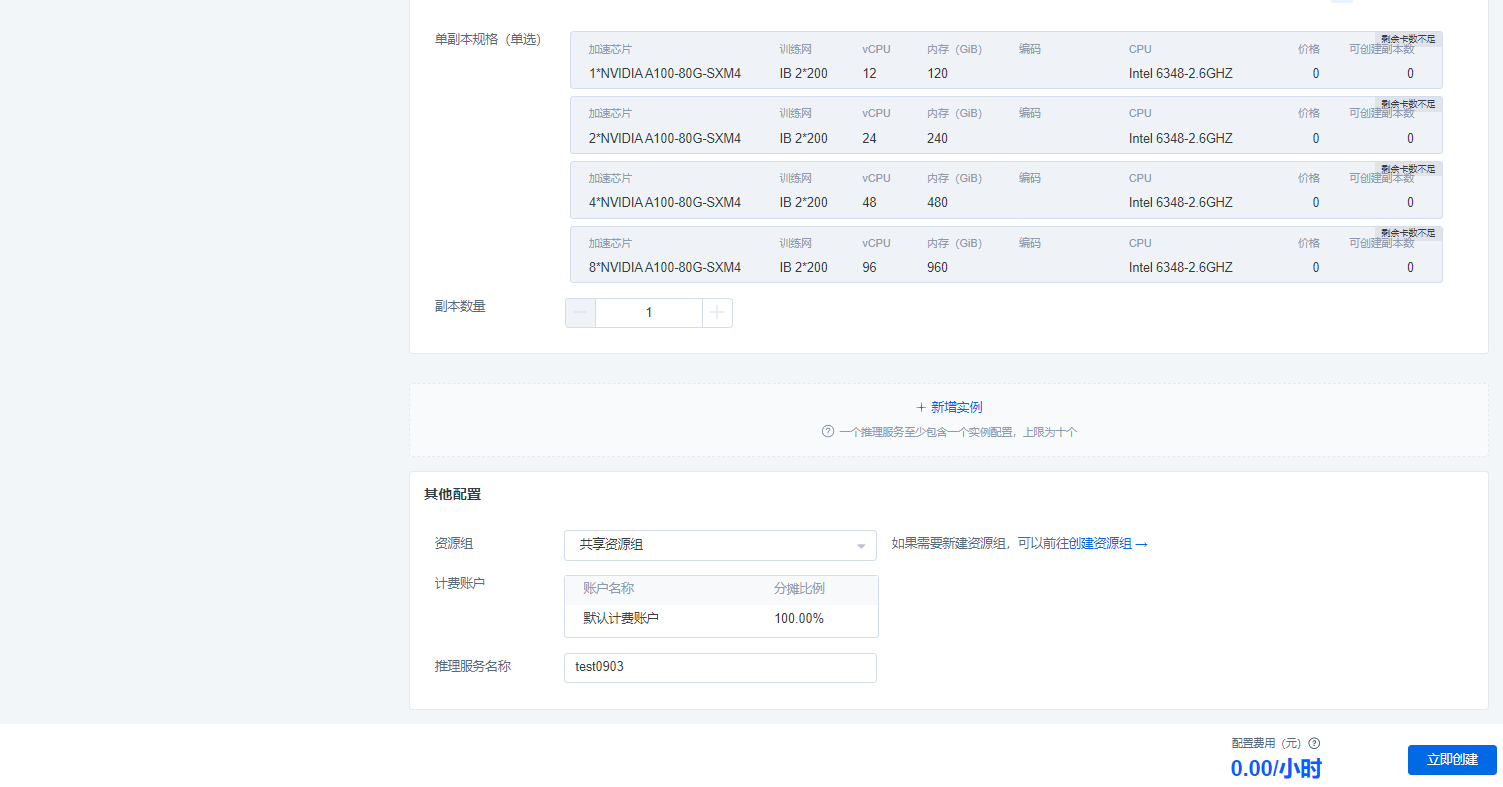
单副本规格:按需选择算力资源及规格,llama3-8B-instruct模型推荐算力规格为:2NVIDIA A100-80G-SXM4/2*NVIDIA A800-80G-SXM4。
副本数量:按需选择。
其他配置信息中,资源组、计费账户以及推理服务名称,按需配置即可。
注:因模型部署目前的主要收费项目为底层使用的算力资源,所以模型部署的相关收费订单都在算力资源上。
创建成功的推理服务可以在推理服务列表页查看该服务。\ 点击推理服务名称,例如本次为【Llama3-8B-Instruct】,进入模型详情页,获取推理接口URL,例如:https://maasroot.studio.sensecoreapi.tech/llama3-8B-instruct。\ 使用API测试工具进入测试.
服务调用示例
curl --location 'https://username.studio.sensecoreapi.cn/llama3-8B-instruct'\
--header 'Content-Type: application/json'
--header 'X-Request-Id: testlc'
--header 'Authorization:Bearer your_api_key'
##api key可通过推理服务的【鉴权管理】获取.
--data '{
"inputs": "hello, I am a pretty girl",
"parameters": {
"best_of": 1,
"details": false,
"do_sample": true,
"max_new_tokens": 100
},\
"stream": false
}'