提交一个MPI分布式任务
MPI任务是一种使用多节点多进程通信框架MPI来启动分布式训练的作业,依靠MPI负责进程管理和跨节点通信。高性能算力池ACP支持用户发起MPI的分布式训练任务。
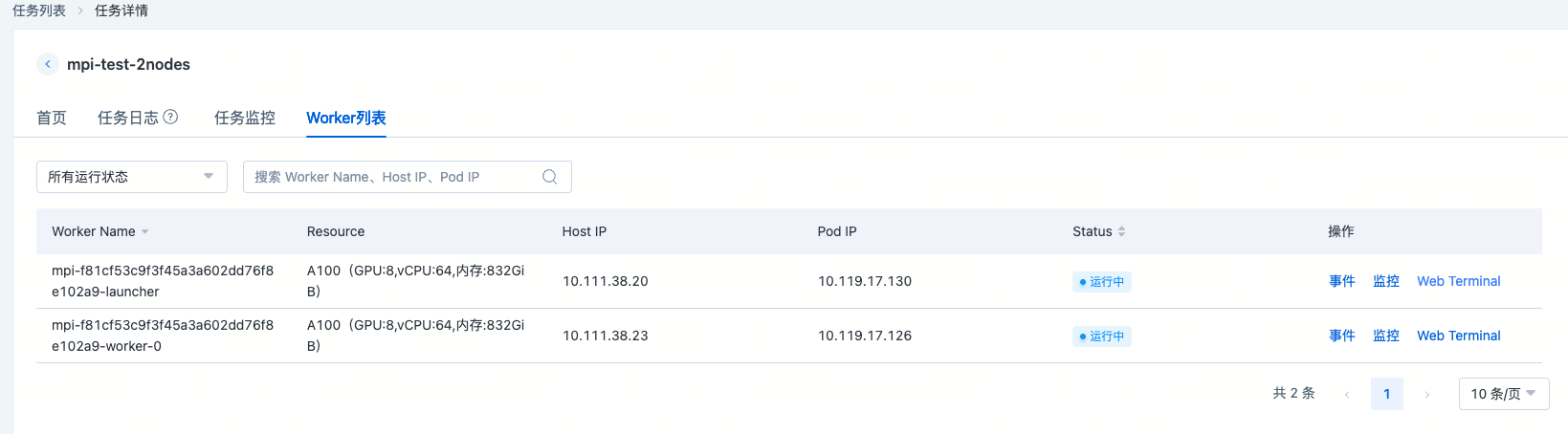
对于MPI提交的分布式任务,平台会创建一个后缀为launcher的Pod和多个后缀为worker的Pod,分别表示MPI任务的启动节点和执行节点。当然launcher即是启动节点也是执行节点。与Pytorch DDP的方式不同,mpirun没有提供master_addr和master_port,而是由MPI的通信机制建立容器之间的进程拓扑关系。因此MPI分布式任务的启动命令必须是如mpirun的启动命令或者包含mpirun启动命令的脚本。常见的MPI分布式训练任务有:
- Pytorch+Horovod
- Pytorch +MPI
- TensorFlow+MPI
- TensorFlow+Horovod
MPI任务在启动时会做如下事情:
- 收集当前MPI任务所有的podname到MPI launcher Pod的/etc/mpi/hostfile文件中, 格式如下:
MPI-zjwghlra-launcher slots=8
MPI-zjwghlra-worker-0 slots=8
MPI-zjwghlra-worker-1 slots=8
MPI-zjwghlra-worker-2 slots=8
MPI-zjwghlra-worker-3 slots=8
MPI-zjwghlra-worker-4 slots=8
MPI-zjwghlra-worker-5 slots=8
MPI-zjwghlra-worker-6 slots=8
在MPI launcher Pod中增加
OMPI_MCA_plm_rsh_agent=/etc/mpi/kubexec.sh环境变量使得mpirun建立进程通信时可以走该代理通道,从而无需建立ssh连接;同时launcher Pod中要执行的命令也是通过该代理通道下发到各个worker中的。在MPI launcher Pod中增加
OMPI_MCA_orte_default_hostfile=/etc/mpi/hostfile环境变量来设置默认hostfile,这样用户在执行mpirun命令的时候就无需手动指定hostfile。
此外针对MPI启动命令,必须增加一些必备项,才能保障正确执行,如下所示:
mpirun --allow-run-as-root -bind-to none -map-by slot --mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" -mca pml ob1 -mca btl ^openib -mca plm_rsh_num_concurrent 300 -mca routed_radix 600 -mca plm_rsh_no_tree_spawn 1
详细解释:
mpirun \
--allow-run-as-root \ ## 指的是允许root身份执行程序,默认是不允许
-bind-to none -map-by slot \ ## openMPI才会用到,指的是不自动绑定cpu核心,可以使用超线程,并且按照设置的slot进行映射,我们默认的每个节点的slot=用户设置的Pod GPU数量
--mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" \ ## 为launcher用指定的ssh发起连接远程启动worker任务
-mca pml ob1 -mca btl ^openib \ ## openMPI建立进程socket的强制使用ob1 PML方式,建立连接不使用IB网
-mca plm_rsh_num_concurrent 300 \ ## openMPI 指定要同时调用的plm_rsh_agent实例数
-mca routed_radix 600 \ ## 解决限制Pod并发数量问题,在起的MPI 容器少于65个时不用加,大于等于65就需要加这个,否则会被openMPI约束
-mca plm_rsh_no_tree_spawn 1 \ ## openMPI指定是否使用基于树的拓扑启动应用程序,1为允许
-np 1 \ ## 表示训练任务使用的进程数,其值小于等于GPU总数,如4机8卡,就是4*8=32;当np小于GPU总数时会有 (GPU总数-np) 个GPU无法被使用
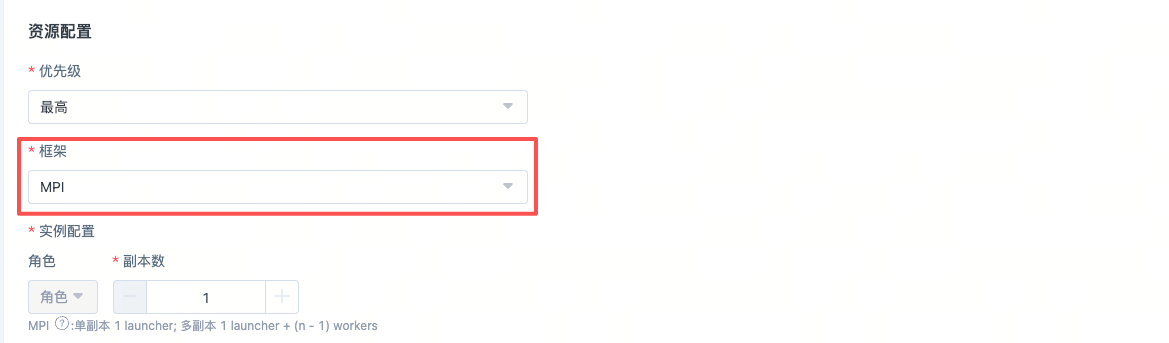
提交一个MPI任务实例
注意:算力池当前的MPI任务只支持
openmpi,原因是社区中采用预配置节点的方式为openmpi命令独有的参数,其他MPI实现可能会有所差别,暂时还不支持。https://www.open-MPI.org/
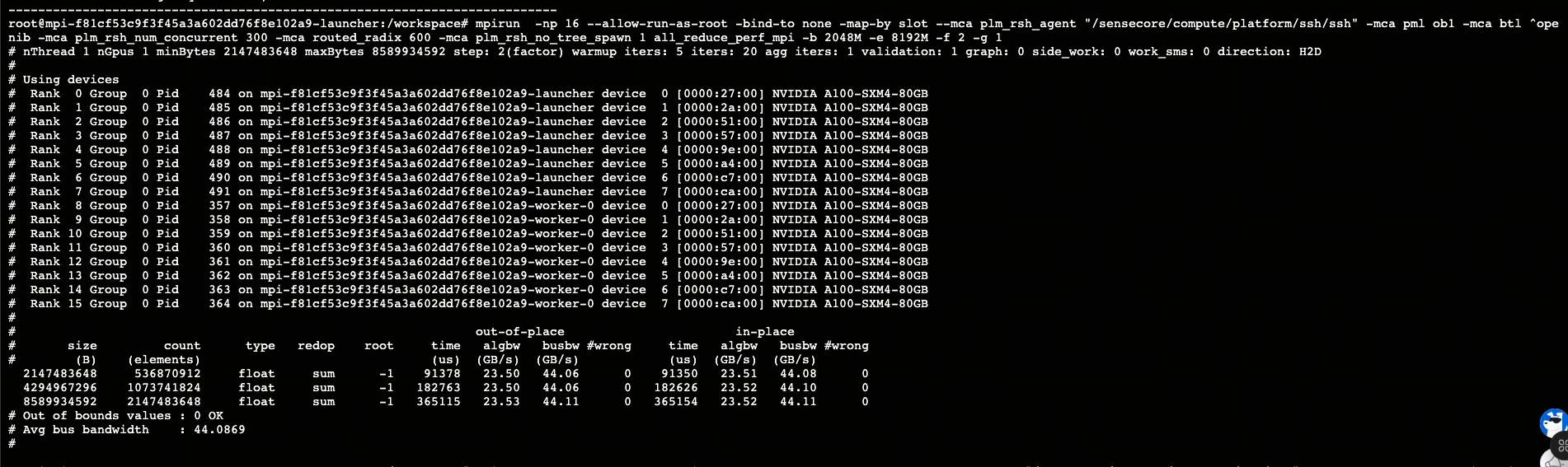
在算力池上提交一个2*8的MPI任务,用户做多机通信库检测,启动命令如下:
mpirun --allow-run-as-root \
-bind-to none -map-by slot \
--mca plm_rsh_agent "/sensecore/compute/platform/ssh/ssh" \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_num_concurrent 300 \
-mca routed_radix 600 \
-np 16 \
all_reduce_perf_mpi -b 2048M -e 8192M -f 2 -g 1
更多相关操作详情,可参考【NGC 镜像】nccl-test 通信库检测最佳实践 。