【快速开始】微调Llama-3-8B-Instruct模型最佳实践
模型介绍
Llama-3-8B-Instruct模型由Meta公司开发,属于Llama系列模型。由于针对对话用例进行了优化,所以该模型在多个行业基准测试中表现优于许多现有的开源聊天模型。Llama-3-8B-Instruct支持多种输入和输出,包括文本和代码生成,并且采用了优化过的transformer架构。该模型通过监督式微调(SFT)和基于人类反馈的强化学习(RLHF)进行了调优。
使用前提
前置动作1:在弹性计算集群(AEC2)创建工作空间 --> 创建节点 --> 将节点绑定到目标集群。如您已经有可用集群则可以忽视本步骤。前置动作2:在文件存储AFS创建文件系统
通过控制台微调模型
点击进入ACP高性能算力池。
选定工作空间。
点击左侧栏快速开始。
点击Meta-Llama-3-8B-Instruct模型。
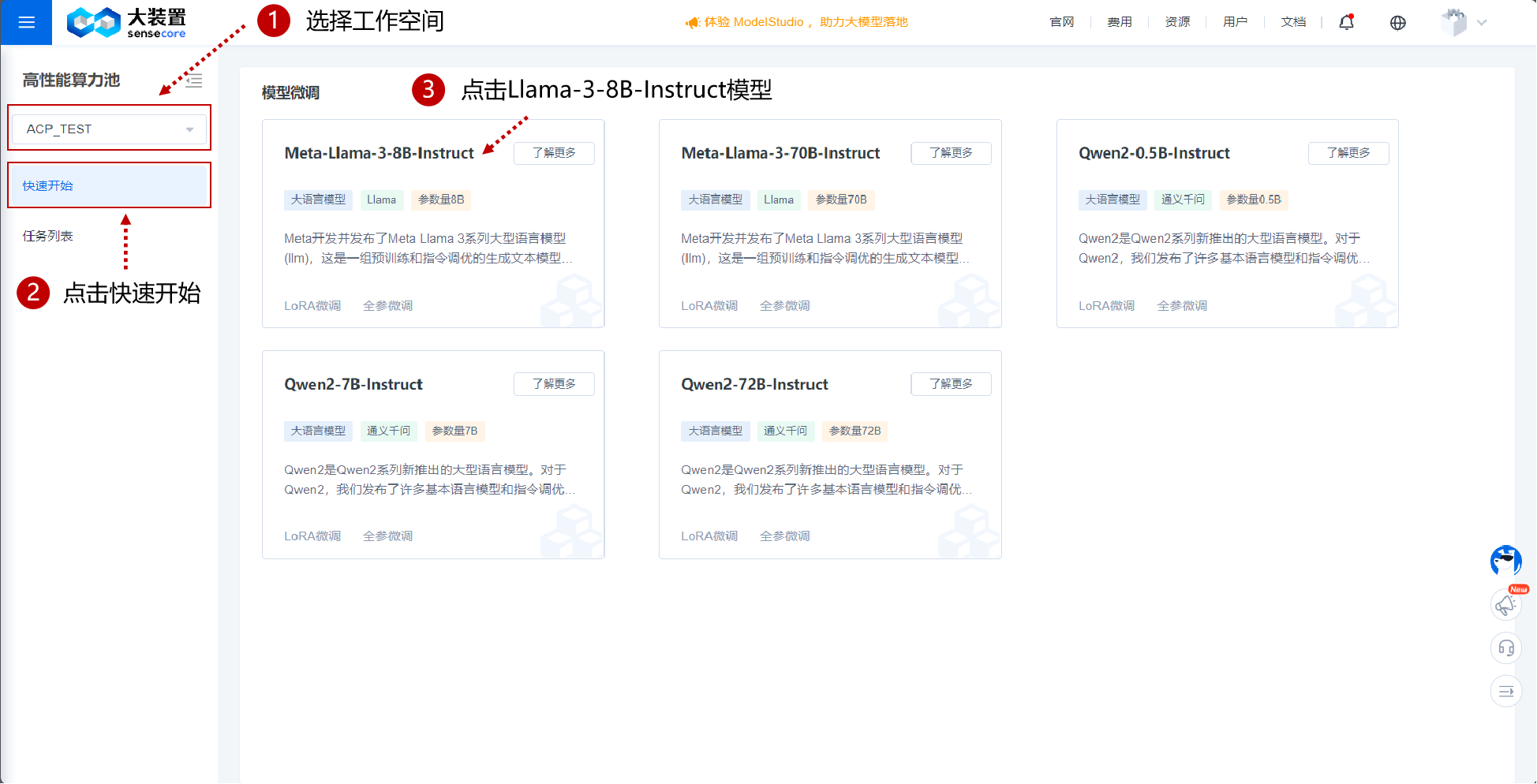
- 关键配置
基本信息
- 填入显示名称,微调方法可以采用LoRA或全参微调,Lora微调所需时间更短,并根据显卡类型需求选择集群(您可用的集群可能与本实例截图不同,请以实际情况为准)。
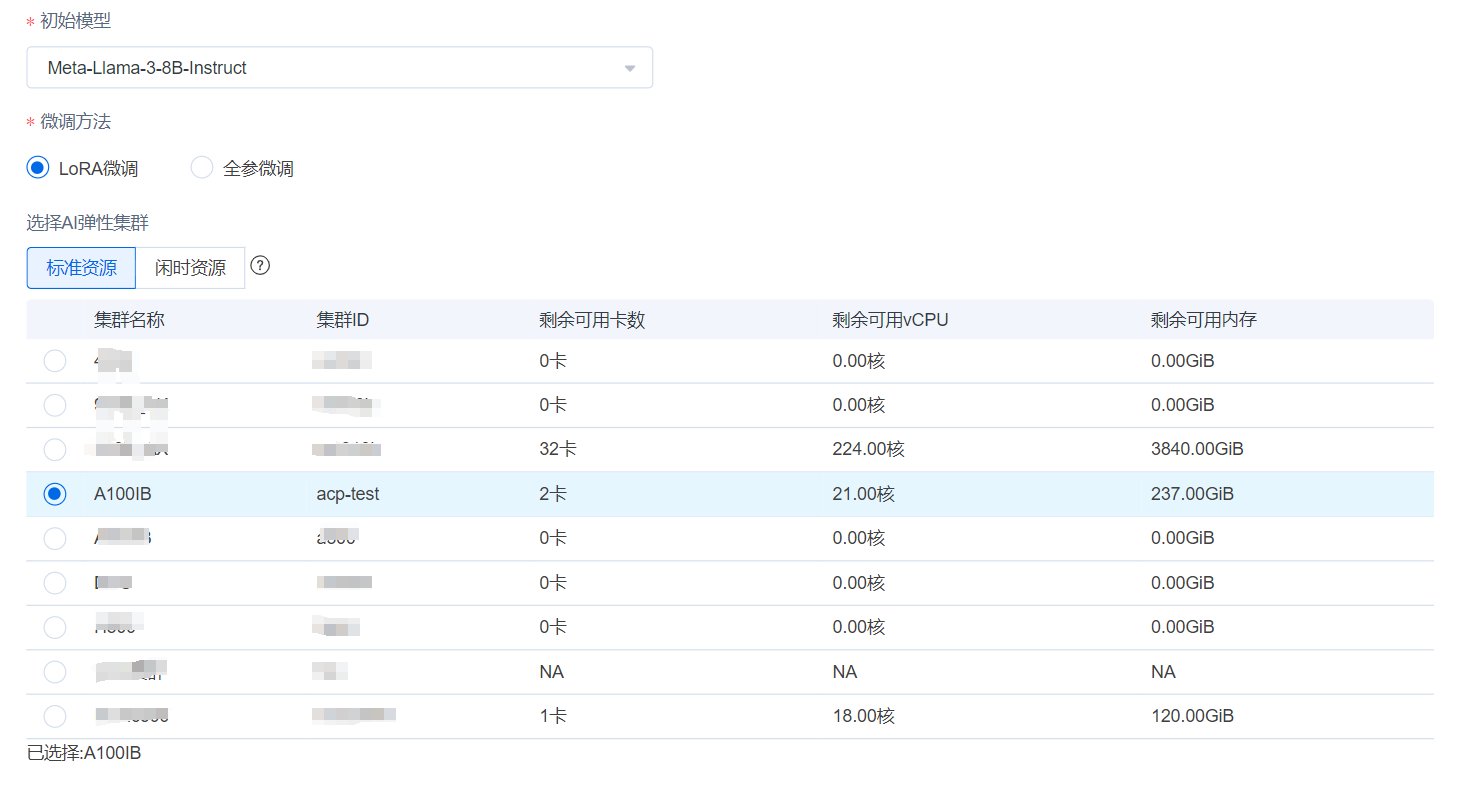
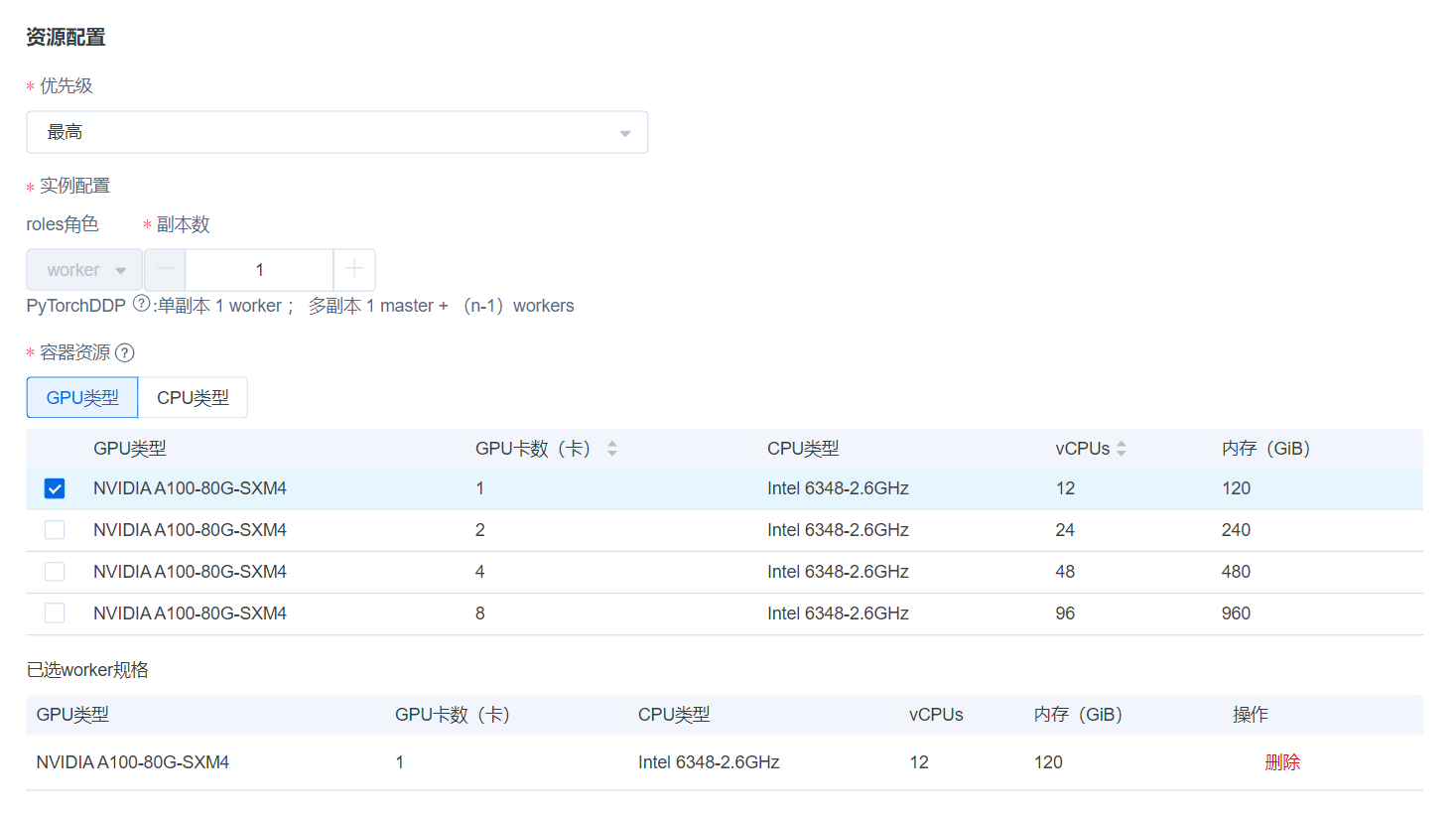
资源配置
- 优先级:选择任务优先级(含最高、高优和普通)。
- 实例配置:本例选择单副本数即可(若模型参数量更大,可以考虑通过多机多卡进行训练,即副本数选择>1)。
- GPU类型:对于本示例的8B模型,LoRA微调建议使用单张24GB以上显存的加速卡,全参微调建议1-4张80GB显存加速卡。
数据集配置
- 平台提供了默认数据集供训练,无需进行额外操作获取数据集;另外,您也可以自行提供训练数据集(目前只支持通过http或https方式上传自定义数据集):训练数据接受Json格式输入,每条数据由问题、答案组成,分别用"instruction"和"output"字段表示,数据集格式示例如下:
[ { "instruction": "hi", "input": "", "output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?" }, { "instruction": "你是商汤科技开发的SenseChat吗?", "input": "", "output": "抱歉,我不是 商汤科技 开发的 SenseChat,我是 {{author}} 开发的 {{name}},旨在为用户提供智能化的回答和帮助。" } ]超参数配置
- 平台提供默认模型微调超参数,您也可以根据需要自行调整。
超参数名称 解释 默认值 训练batch size 训练时每块GPU上的批量大小 1 验证batch size 验证时每块GPU上的批量大小 1 max epochs 最大的训练迭代次数,值越大训练越久 3 learning rate 决定了训练神经网络时权重参数更新的速度(建议0.0001-0.00001) 0.0001 max samples 进行微调时的训练集最大数据总量(而batch size是每次迭代的数据量) 1000
训练输出及TensorBoard配置
- 训练输出配置:如您已经有存储卷,可以直接选择目标存储卷。模型存储挂载路径默认为/mnt/afs/model。
- TensorBoard配置:采集TensorBoard可选,若选定“是",则需要选择目标存储卷,默认挂载路径为/mnt/afs/tensorlog。
- 若还没有任何文件存储卷,请先前往AFS文件存储创建,如果不挂载持久存储,训练结果将会丢失。
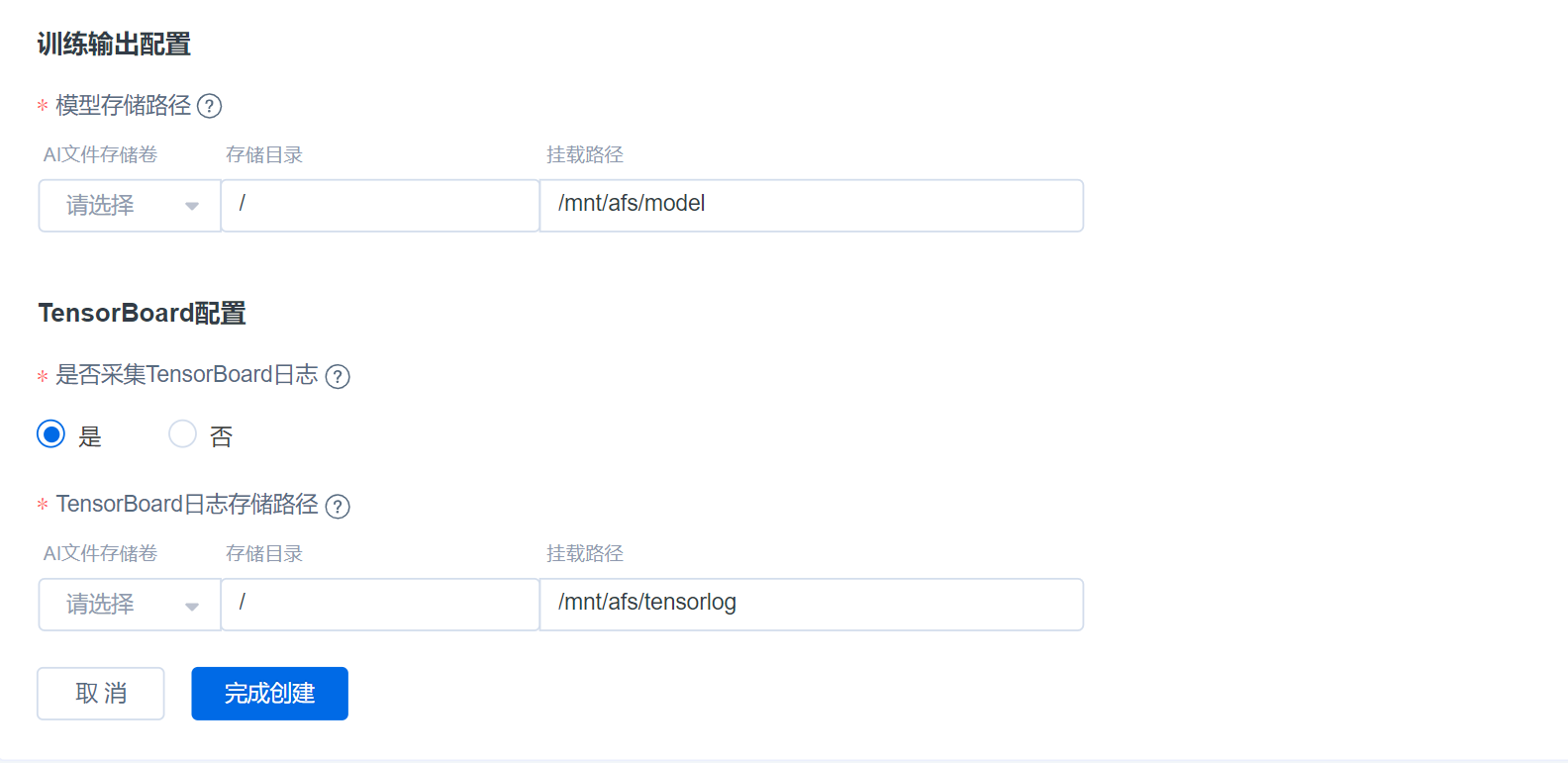
- 点击完成创建
- 创建完毕后,任务会经历【初始化】-【启动中】,【运行中】等状态,如状态转为【成功】,说明训练任务已完成,请到目标文件存储空间查看微调完毕的模型;若失败,可以通过“复制”(位于任务列表每个任务的右侧-操作),重新开始模型微调。
- 注意,快速开始中的模型每次微调都是基于预置镜像从头开始,暂不支持基于已有模型的checkpoint进行续训练)。
