提交一个Pytorch DDP分布式任务
对于Pytorch DDP分布式任务,我们会创建两种类型的Pod:Master和Worker,其中Master为Worker提供了可以访问的Master IP地址、Master 服务端口,并且自动把Pytorch任务中全部的进程数量和每个Pod的进程ID都输出到了环境变量中,所以用户在使用Pytorch分布式训练任务的时候,可以直接使用如下环境变量名称替换训练脚本中的Master ip、Master端口、进程总数和进程rank。
$MASTER_ADDR
$MASTER_PORT
$WORLD_SIZE
$RANK
举例如下:
python -m distributed.launch --nproc-per-node 2 --nnodes $WORLD_SIZE --node_rank $RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT mnist.py --backend nccl
对于使用RoCE的算力池的训练任务,可以在训练脚本中增加如下环境变量获得最优性能:
注意:对于使用IB类型的算力池任务,可以不加
NCCL_IB_TC、NCCL_IB_GID_INDEX这两个环境变量,加了可能会比较慢
export NCCL_DEBUG=INFO # 这个与性能无关,只是便于排查问题
export NCCL_IB_TC=106 # 指定NCCL使用的交换机通道
export NCCL_IB_GID_INDEX=3 # 选择指定的IB index
export NCCL_SOCKET_IFNAME=eth0 # 在构建NCCL socket时选择eth0网络
export NCCL_CROSS_NIC=0 # 固定每个网卡的连接通道
#当训练的规模达到千卡及以上时,可以增加如下环境变量:
export NCCL_ALGO=TREE
UI界面提交DDP任务示例
在a100_RoCE_1024算力池【RoCE类型的算力池】上启动一个128机8卡共计1024卡的DDP Pytorch 训练任务。
启动命令如下:
export NCCL_DEBUG=INFO
export NCCL_IB_GID_INDEX=3
export NCCL_IB_TC=106
export NCCL_CROSS_NIC=0
export NCCL_ALGO=RING
export NCCL_SOCKET_IFNAME=eth0
bash ./train/176B_ft_qb_60w_en_80w_20230213.sh $MASTER_ADDR $MASTER_PORT $WORLD_SIZE $RANK
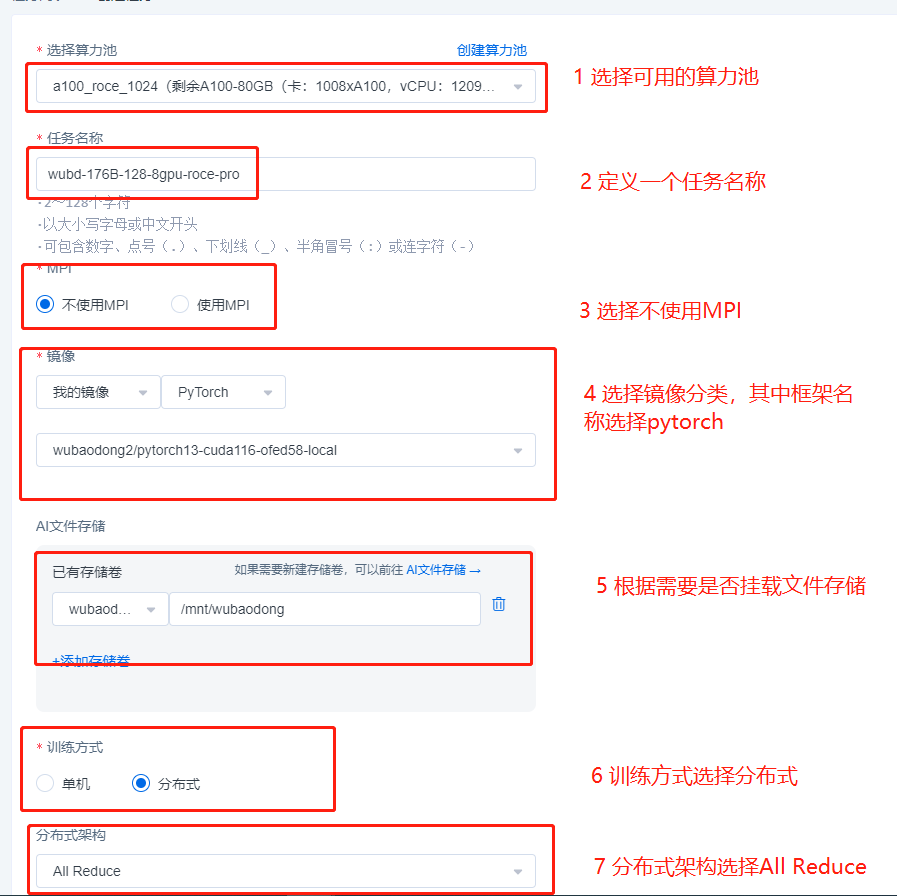
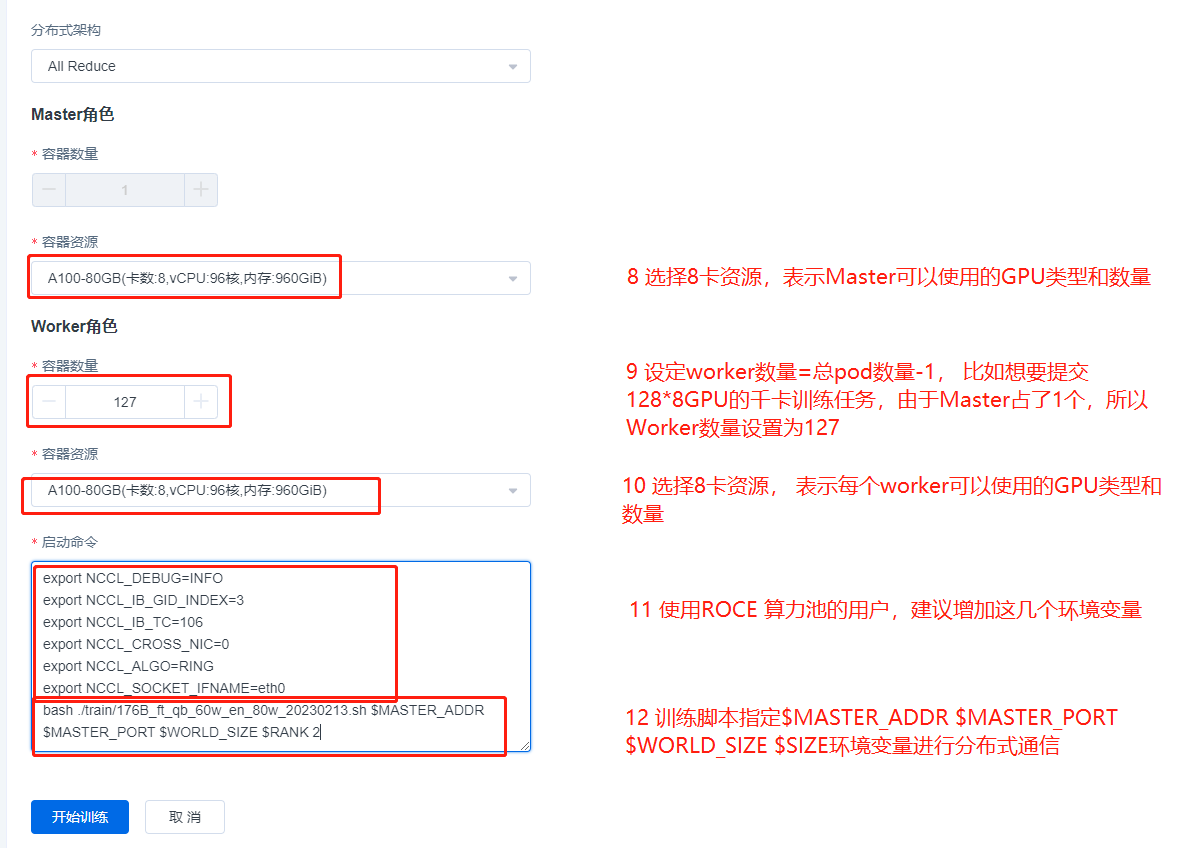
上面是RoCE类型算力池任务的示例,如果是IB类型的算力池,提交的流程完全相同,只需要去掉启动命令中的
export NCCL_IB_GID_INDEX=3
export NCCL_IB_TC=106
export NCCL_CROSS_NIC=0
这3个环境变量即可。
注意:我们在新版本的高性能AI算力池中简化了任务提交流程,您只需要指定一个角色数量和规格。若您指定和n个角色数量,我们会自动为您以1个Master角色和n-1个Worker角色启动任务。